

大数据挖掘平台算法设计
目录
一.基本统计方法
二.降维算法()
主成分分析()
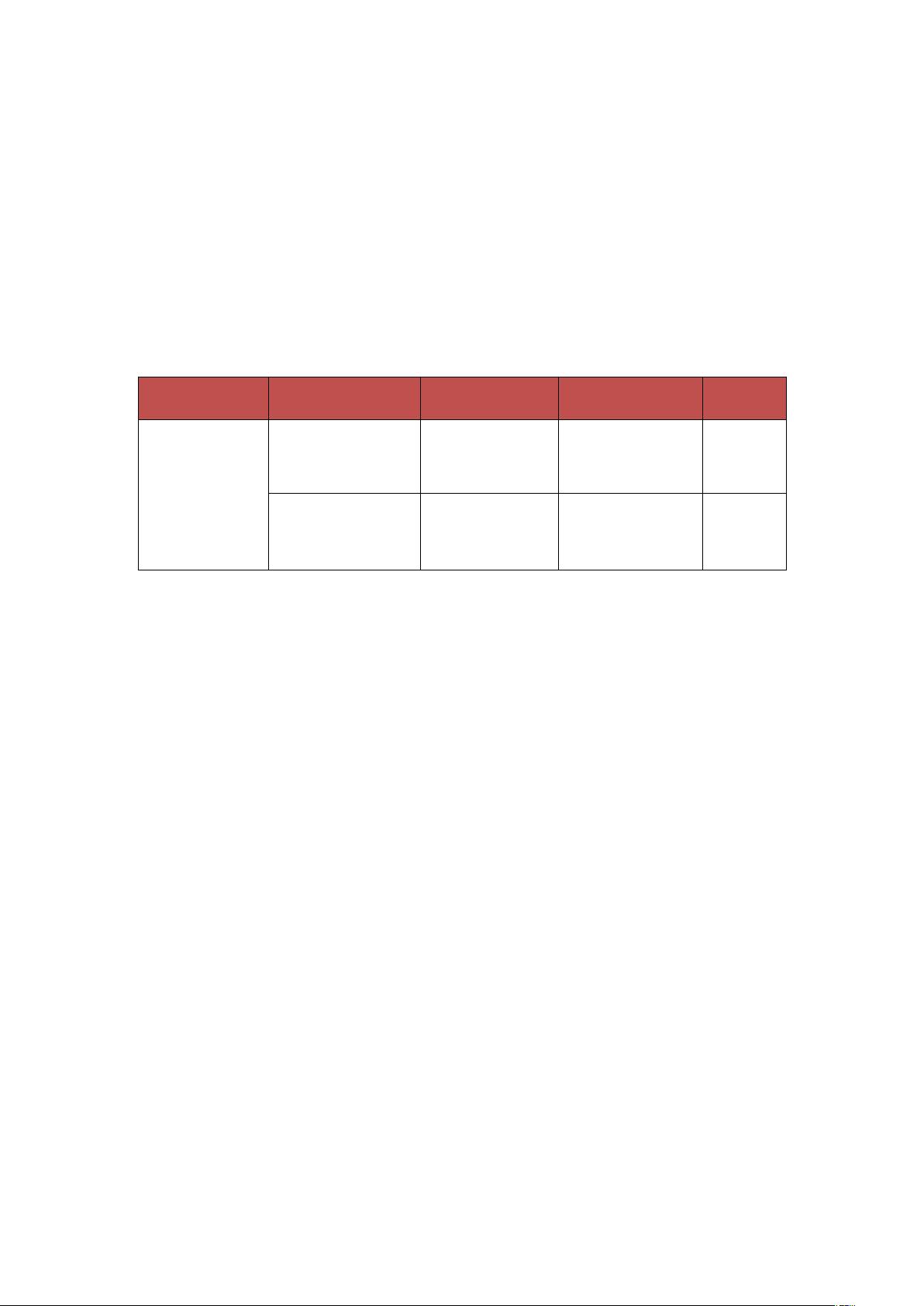
表 载荷矩阵(示例)
奇异值分解()
三.分类算法
分类算法基本介绍
分类算法输入与输出
表 分类结果明细表(示例)
四.聚类算法
聚类算法介绍
聚类算法的输入
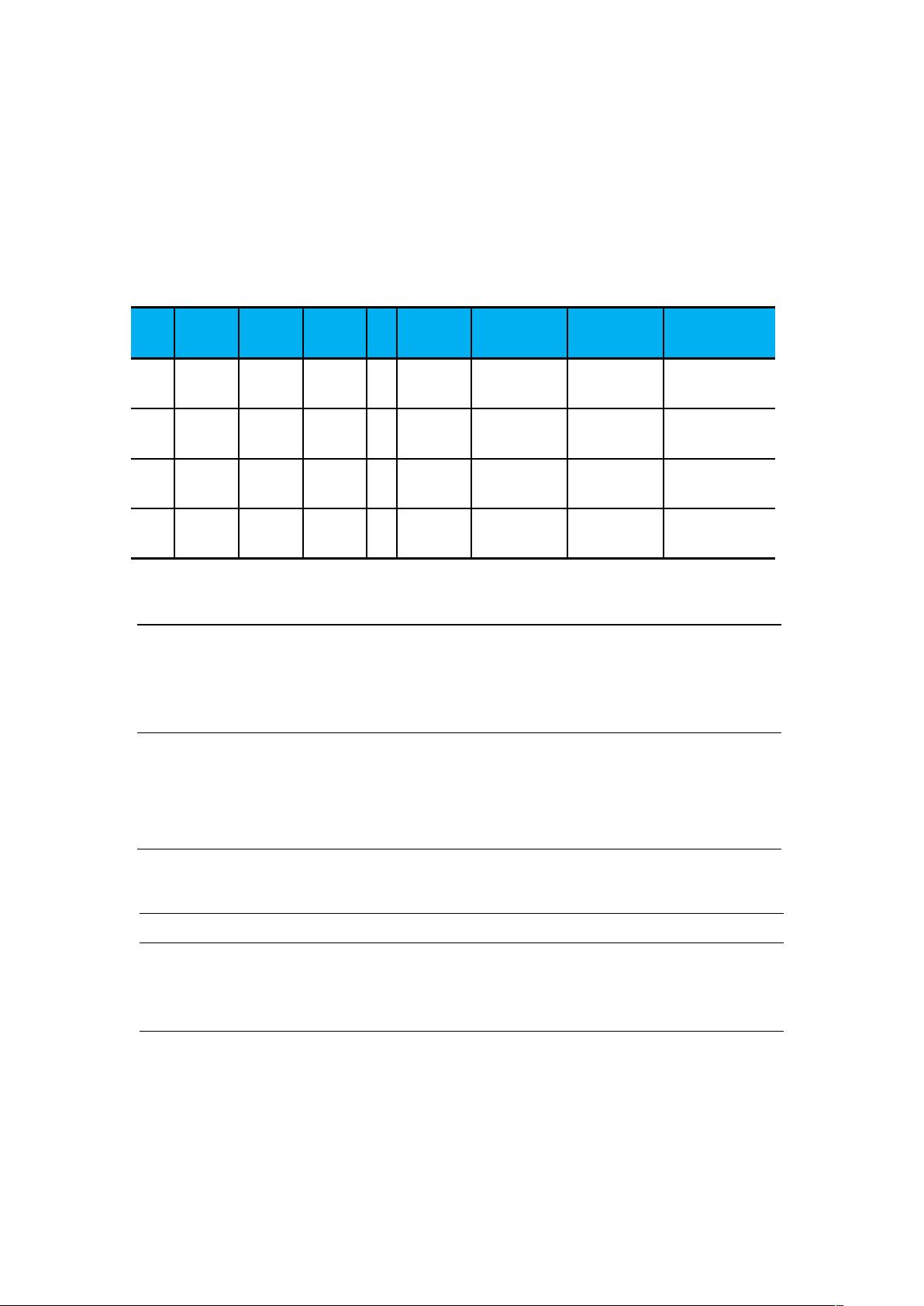
表 聚类算法的输入与输出
聚类算法的输出
五.关联分析算法
关联分析算法介绍
关联分析算法的输入
关联分析算法的输出
六数值预测算法
数值预测算法介绍
数值预测算法的输入
数值预测算法的输出
数值预测算法的效果评估


剩余27页未读,继续阅读
资源评论


dinjun268
- 粉丝: 0
- 资源: 13









最新资源
- 基于MATLAB 使用模糊逻辑算法控制给定交叉口的红绿灯系统
- android-19安卓操作系统版本8
- springboot医院病历管理系统--论文-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- springboot在线小说阅读平台_0hxfv-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- springboot智慧生活分享平台62(源码+sql+论文)-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- springboot智能菜谱推荐系统_ct3p7--论文-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 毕业生信息招聘平台-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 大学生创新创业训练项目管理系统设计与实现-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 大健康养老公寓管理系统_to14d-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 复现一篇国内中文核心,改进的DSOGI-PLL锁相环 能够对含有电压直流分量或者是含有高次谐波 都能够锁定电压基波频率50HZ
- 大学新生报到系统的设计与实现-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 大学生社团活动平台-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 儿童性教育网站-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 点餐平台网站-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 个性化电影推荐系统-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
- 高校学生饮食推荐系统_02187-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


