编译原理是一门研究计算机程序设计语言翻译过程的学科,它包括语言分析、词法分析、语法分析、语义分析、中间代码生成、代码优化以及目标代码生成等过程。编译原理的核心是理解编译器是如何将源代码转换为机器代码的。在学习编译原理的过程中,练习课后习题是加深理解的重要环节,因此,编译原理及实践课后习题的答案自然就成了学习者的重要参考资料。
在本文件提供的内容中,主要涉及了正则表达式的构造、正则表达式描述的语言的英文描述、以及正则表达式的NFA(非确定有限自动机)到DFA(确定有限自动机)的转换。
关于构造正则表达式,文档中给出了几个特定字符集的正则表达式的构造方法,并对无法构造正则表达式的字符集给出了解释。例如:
a. 代表所有由小写字母构成的字符串,并且这些字符串以小写"a"开始和结束。对应的正则表达式为 [a-z]*a[a-z]*。
b. 代表所有由小写字母构成的字符串,这些字符串要么以小写"a"开始,要么以小写"a"结束,或者两者都有。对应的正则表达式为 ([a-z]*a[a-z]*)|([a-z]*a)。
c. 代表所有数字字符串,但不包含以零开头的数字。对应的正则表达式为 [1-9][0-9]*。
d. 代表所有偶数数字字符串。由于正则表达式本身不能计数,无法构造出一个可以识别偶数的正则表达式。
e. 代表所有数字字符串,其中所有的"2"都出现在所有的"9"之前。对应的正则表达式为 ([0-1]|[3-8]|9)*[2]([0-1]|[3-8]|9)*。
g. 代表所有包含奇数个"a"或奇数个"b"的字符串。这里涉及到正则表达式的或运算以及递归。
对于无法用正则表达式描述的语言,文档中明确指出由于正则表达式的局限性(无法计数),因此无法构造出能够准确描述需要计数的语言的正则表达式。
关于正则表达式描述的语言的英文描述部分,文档中给出了几个示例:
a. 描述了所有以小写"a"或小写"b"结尾的字符串集合。
b. 描述了所有以大写字母开头且不包含其他大写字母的英文单词集合。
c. 描述了能够被分为两部分的字符串集合,左边部分连续的"b"被偶数个"a"分开,右边部分连续的"a"被偶数个"b"分开。
d. 描述了所有至少有一个字符长度的十六进制数字字符串。
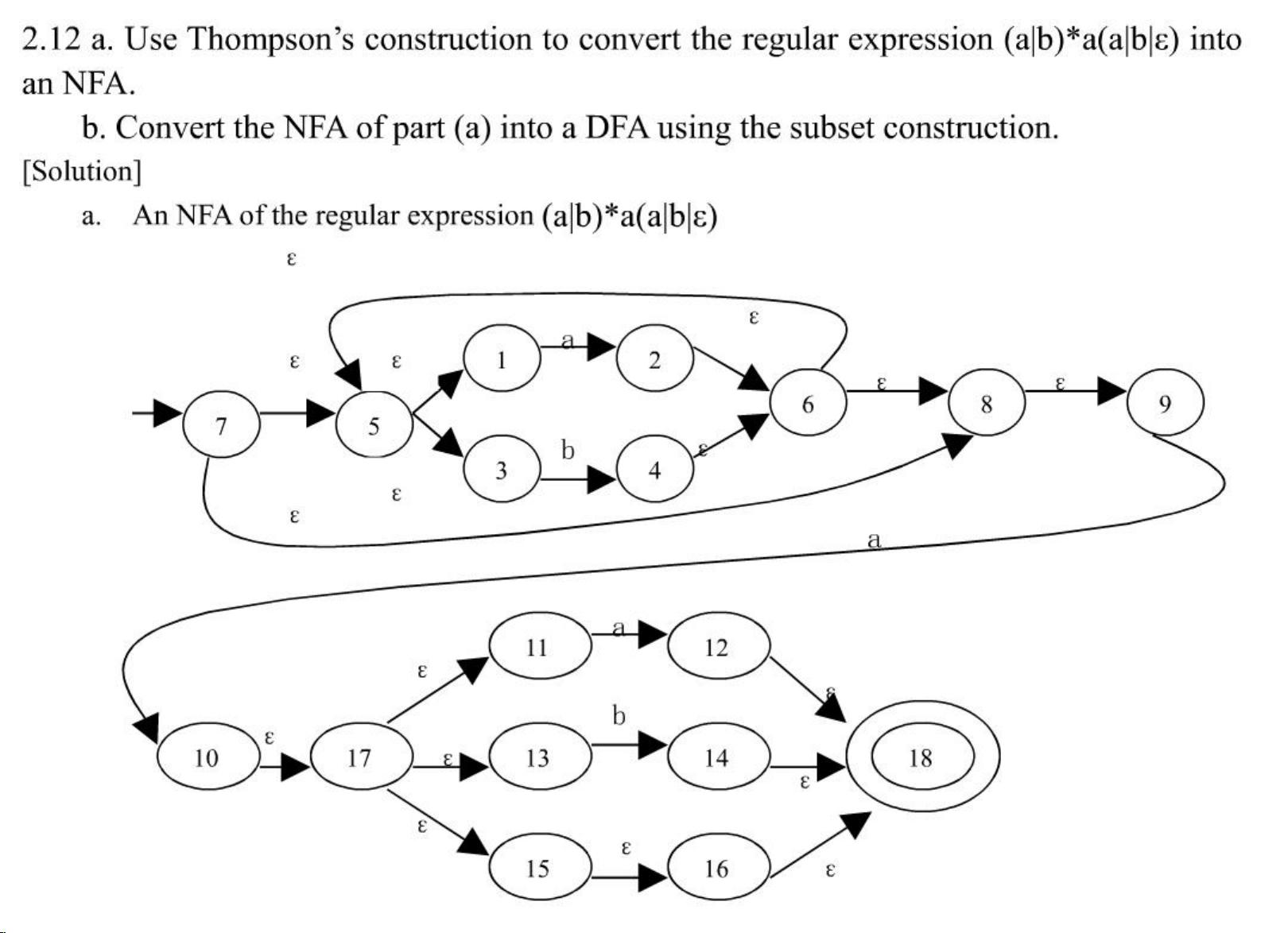
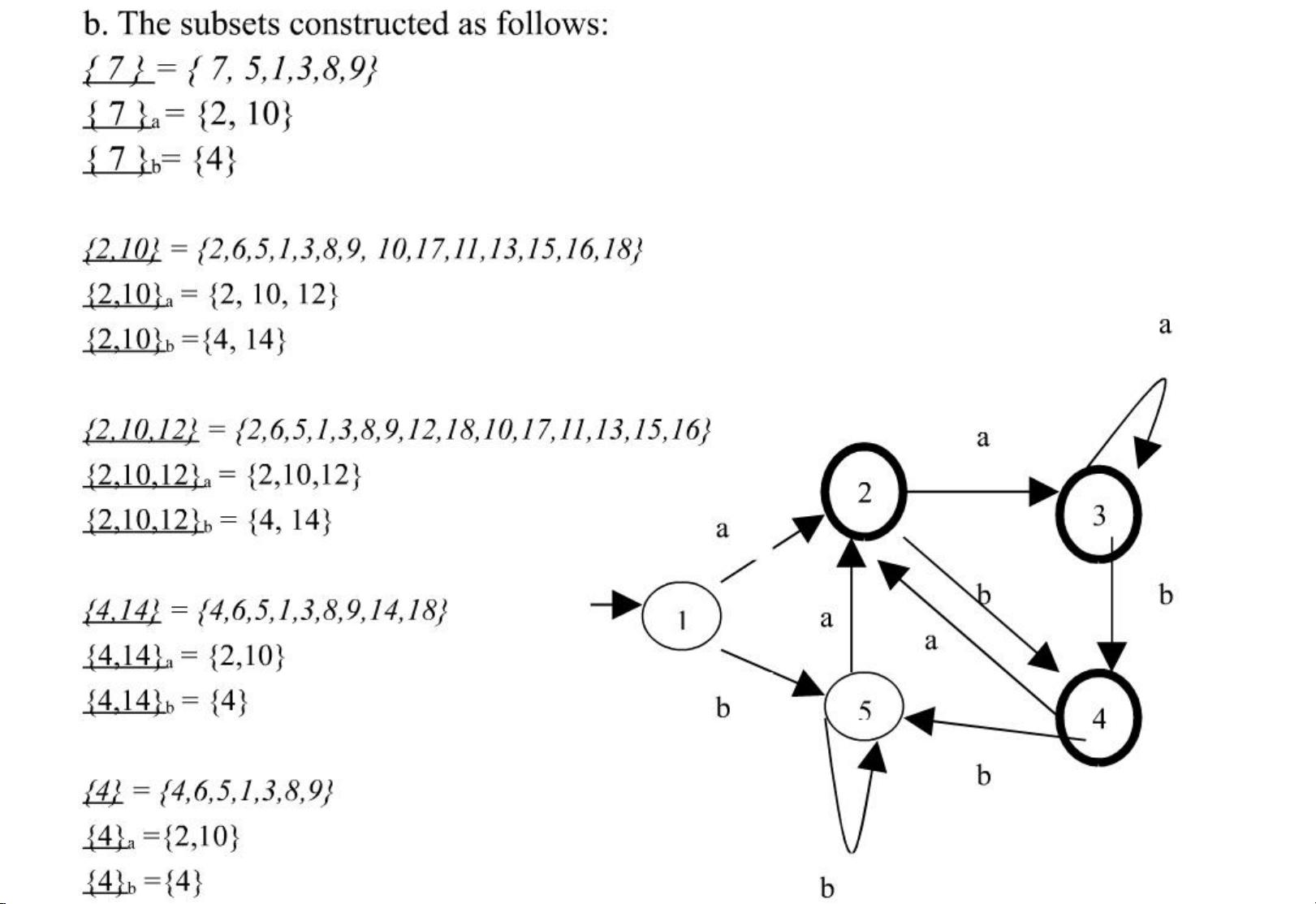
另外,文档中还展示了使用Thompson构造法将正则表达式 (ab)*a(ab|b)* 转换为NFA的过程,以及随后使用子集构造法将NFA转化为DFA的过程。NFA和DFA都是自动机理论中的概念,它们用于描述计算机程序如何识别(或接受)特定的语言。NFA允许从一个状态出发通过一个输入符号达到多个状态,而DFA则在任意时刻每个输入符号只能到达一个状态。
在转换过程中,NFA首先被构造出来,然后基于NFA构造出DFA。DFA通常比NFA需要更多状态,但因为它的确定性,使得DFA在实现时更为高效。文档中展示了相应的转换过程和转换后构造出的DFA状态转移表。
总结来说,该文件涉及了编译原理中的正则表达式构造、自动机转换等多个核心概念,并通过具体的例子加深了对这些概念的理解。对于学习编译原理的人来说,这样的练习答案能极大地帮助他们理解理论知识,并且能够在实际编程中运用所学知识解决实际问题。

















- 1
- 2
- 3
前往页