





[原创]Apache Pig的一些基础概念及用法总结(1)
转载必须注明出处:http://www.codelast.com/ [http://www.codelast.com/]
本文可以让刚接触pig的人对一些基础概念有个初步的了解。
本文大概是互联网上第一篇公开发表的且涵盖大量实际例子的Apache Pig中文教程(由Google搜索可知),文中的大量实例都是作
者Darran Zhang(website: codelast.com)在工作、学习中总结的经验或解决的问题,并且添加了较为详尽的说明及注解,此
外,作者还在不断地添加本文的内容,希望能帮助一部分人。
Apache pig [http://pig.apache.org/] 是用来处理大规模数据的高级查询语言,配合Hadoop使用,可以在处理海量数据时达到事半
功倍的效果,比使用Java,C++等语言编写大规模数据处理程序的难度要小N倍,实现同样的效果的代码量也小N倍。Twitter就大
量使用pig来处理海量数据——有兴趣的,可以看Twitter工程师写的这个PPT [http://www.slideshare.net/kevinweil/hadoop-
pig-and-twitter-nosql-east-2009] 。
但是,刚接触pig时,可能会觉得里面的某些概念以及程序实现方法与想像中的很不一样,甚至有些莫名,所以,你需要仔细地研究
一下基础概念,这样在写pig程序的时候,才不会觉得非常别扭。
本文基于以下环境:
pig 0.8.1
先给出两个链接:pig参考手册1 [http://pig.apache.org/docs/r0.8.1/piglatin_ref1.html] ,pig参考手册2
[http://pig.apache.org/docs/r0.8.1/piglatin_ref2.html] 。本文的部分内容来自这两个手册,但涉及到翻译的部分,也是我自己翻
译的,因此可能理解与英文有偏差,如果你觉得有疑义,可参考英文内容。
【配置Pig语法高亮】
在正式开始学习Pig之前,你首先要明白,配置好编辑器的Pig语法高亮是很有用的,它可以极大地提高你的工作效率。
如果你在Windows下编写Pig代码,好像还真没有什么轻量级的编辑器插件(例如Notepad++的插件之类的)可以实现对.pig文件
的语法高亮显示,我建议你使用Notepad++,在“User Define Language”中自定义Pig语法高亮方案(我这样做之后感觉效果很
好);如果你觉得麻烦,那么你可以直接用Notepad++以SQL的语法高亮来查看Pig代码,这样的话可以高亮Pig中的一部分关键
字。
在Linux下,选择就很多了,大分部人使用的是vi,vim,但我是个Emacs控,所以我就先说说如何配置Emacs的Pig语法高亮。此插
件是一个很好的选择:https://github.com/cloudera/piglatin-mode
那么,怎么使用这个插件呢?
下载piglatin.el文件,将它放置在任何地方——当然,为了方便,最好是放在你登录用户的根目录下(也就是与.emacs配置文件在同
一目录下),然后将其重命名为 “.piglatin.el”注意前面是有一个点的,也就是说将这个文件设置成隐藏文件,否则可能会误删了。
然后,在 .emacs 文件中的最后,添加上如下一行:
(load-file "/home/abc/.piglatin.el")
这里假设了你的 .piglatin.el 文件放置的位置是在 /home/abc/ 目录下,也就是说emacs会加载这个文件,实现语法高亮显示。
现在,你再打开一个.pig文件试试看?非常令人赏心悦目的高亮效果就出来了。效果如下图所示:
其实Emacs也有Windows版的,如果你习惯在Windows下工作,完全可以在Windows下按上面的方法配置一下Pig语法高亮(但是
Windows版的Emacs还需要一些额外的配置工作,例如修改注册表等,所以会比在Linux下使用要麻烦一些,具体请看这篇文章
[http://www.codelast.com/?p=4802] )。
文章来源:http://www.codelast.com/ [http://www.codelast.com/]
下面开始学习Pig。
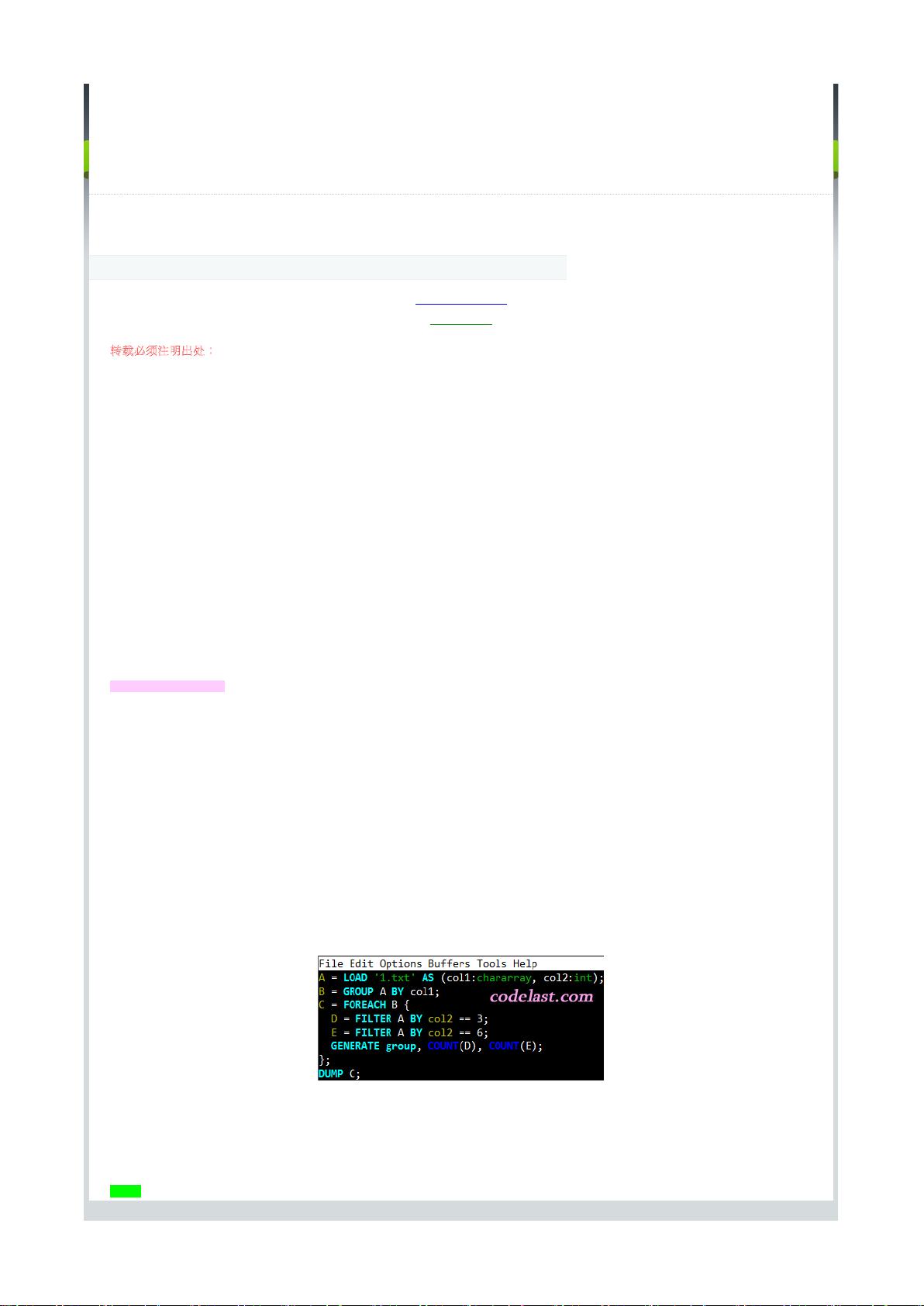
(1)关系(relation)、包(bag)、元组(tuple)、字段(field)、数据(data)的关系
编码无悔 / Intent & Focused
最优化之路
www.firstic.com.tw
页码,
1/20
2012/
10/
30
第
1
页
/
共
20
页

剩余19页未读,继续阅读
资源评论

- #完美解决问题
- #运行顺畅
- #内容详尽
- #全网独家
- #注释完整

stevie
- 粉丝: 63
- 资源: 20









最新资源
- vue3-element-admin-Typescript资源
- cocos图片上传demo,后端代码看博客
- 计算机网络(自顶向下方法)第四版答案(中文版).pdf
- 计算机网络:Ch5 网络层 _A.pdf
- 计算机网络:chapter5 Link Layer.pdf
- 计算机网络_谢希仁第五版课后习题答案.pdf
- 计算机网络:自顶向下方方法.pdf
- PandaX-Go资源
- 计算机网络_电子工业出版社_(谢希仁第五版)课后习题.pdf
- 计算机网络7章.pdf
- 计算机网络_自顶向下方法_第四版_课后习题答案.pdf
- 计算机网络7——网络互连.pdf
- 计算机网络-2022春形考任务三-国开(s)-复习资料.pdf
- 计算机网络-08-11年计算题统计.pdf
- 计算机网络2012-2013题库.pdf
- devtoolset-gcc9-centos 离线安装包
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈
























