在 ChatGPT 发布之初,我同许多 AI 从业者一样对这个被媒体号称要取代搜索引
擎的聊天机器人产品是持怀疑态度的,但在深度体验之后,发现 ChatGPT 跟以往
昙花一现的产品并不一样,它对于回答成熟的知识确实已经大有替代搜索引擎的
能力,而其对上下文层层递进的连续交互能力简直颠覆了人们对大语言模型能力
的想象。
尽管 OpenAI 没有公布 ChatGPT 的论文和相关的训练和技术细节,但我们可以从
其兄弟模型 InstructGPT 以及网络上公开的碎片化的情报中寻找到实现 ChatGPT
的蛛丝马迹。根据 OpenAI 所言,ChatGPT 相对于 InstructGPT 的主要改进在于收
集标注数据的方法上,而整个训练过程没有什么区别,因此,可以推测 ChatGPT
的训练过程应该与 InstructGPT 的类似,大体上可分为 3 步:
1.预训练一个超大的语言模型;
2.收集人工打分数据,训练一个奖励模型;
3.使用强化学习方法微调优化语言模型。
预训练一个超大的语言模型
从 GPT/Bert 开始,预训练语言模型基本遵循这样一个两段式范式,即通过自监
督方式来预训练大模型。然后再在此基础上,在下游具体任务上进行 fine-tuning
(微调)。其中 GPT 因为用的是单向 Transformer 解码器,因此偏向于自然语言
生成,而 Bert 用的是双向 Transformer 编码器,因此偏向于自然语言理解。因为
Bert 的及时开源和 Google 在业界的强大影响力,外加业务导向的 AI 应用公司寄
希望的快速落地能力,那个时候绝大多数的从业者都更加看好 Bert,哪怕是
openai 发布的 GPT2 也是反响平平,这也为后来的落后埋下了伏笔。
这种两段式的语言模型,其 Capability(能力)是单一的,即翻译模型只能翻译,
填空模型只能填空,摘要模型只能做摘要等等,要在实际任务中使用,需要各自
在各自的数据上做微调训练,这显然很不智能,为了进一步向类似人类思维的通
用语言模型靠齐,GPT2 开始引入更多的任务进行预训练,这里的创新之处在于
它通过自监督的模型来做监督学习的任务。经过这样训练的模型,能在没有针对
下游任务进行训练的条件下,就在下游任务上有很好的表现。也就是说 Capability
有了较大的扩展,但此时的 Alignment(对齐)还相对较弱,实际应用上还不能
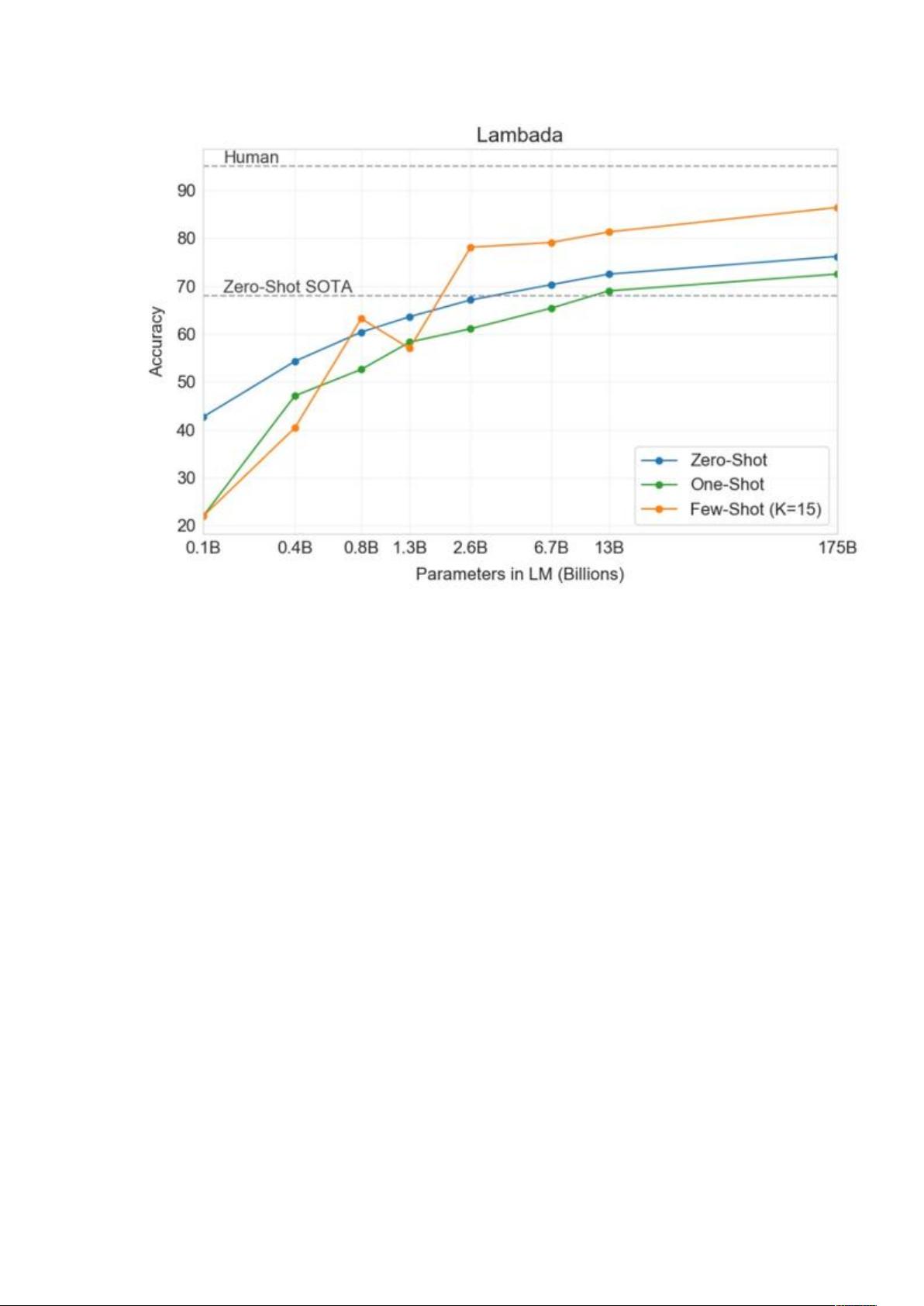
完全去除 fine-tuning,算是为 zero-shot leaning(零样本学习)奠定了基础。为了
解决 Alignment 问题,GPT3 使用了更大的模型,更多的数据,并优化了 in-context
learning(上下文学习)的训练方式,即在训练时去拟合接近人类语言的
Prompt(提示),以指导模型它该做些什么,这进一步提升了模型 zero-shot learning
的能力,总而言之,语言模型在朝着越来越大的方向发展。