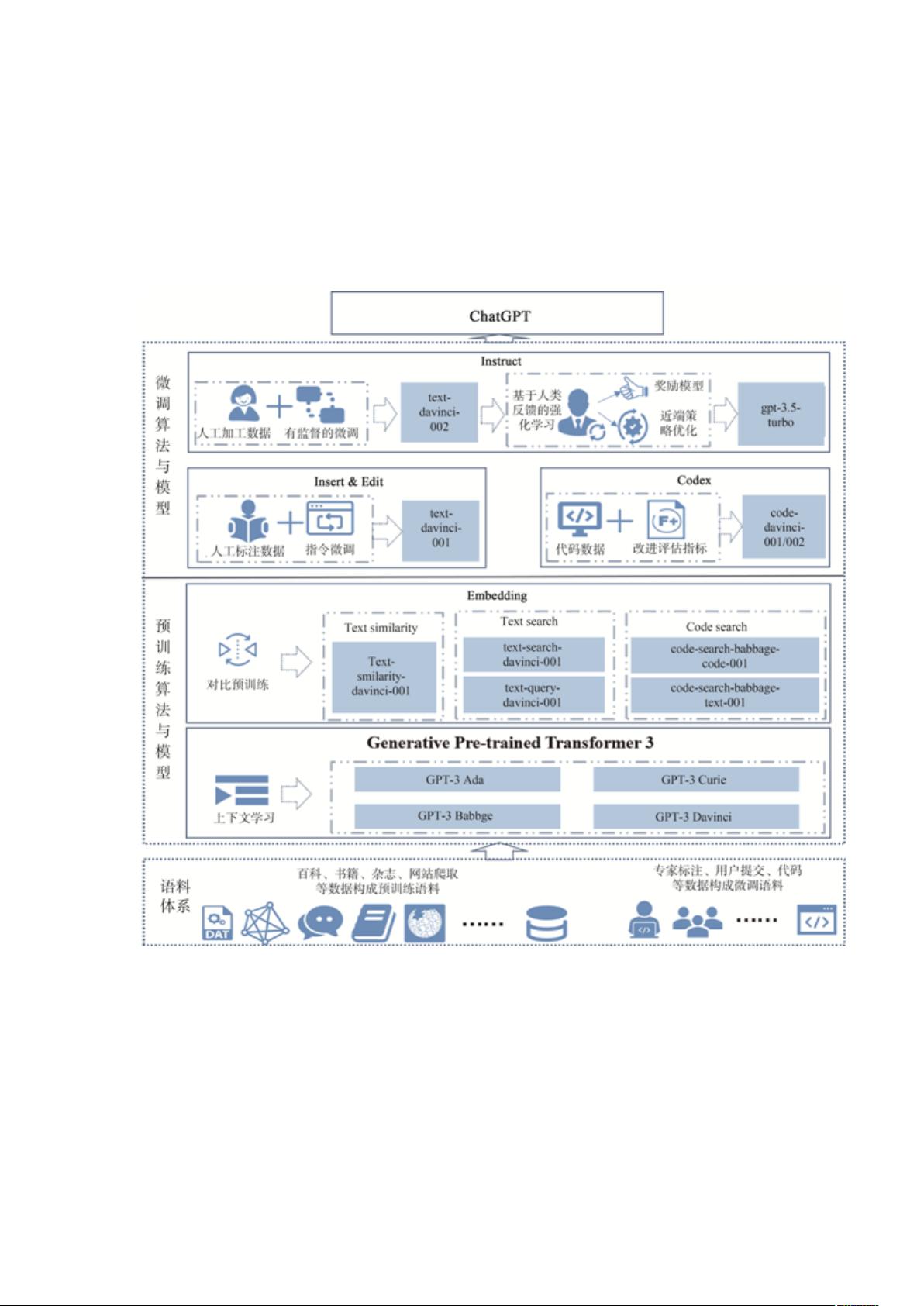
【目的】 梳理分析 ChatGPT 相关的语料、算法与模型,为同行业研究提供体系化的参
考借鉴。【方法】 通过系统梳理 GPT-3 发布至今的相关文献与资料,刻画 ChatGPT 技
术的整体架构,并解释与分析其背后的模型、算法与原理。【结果】 通过文献调研,
根据现有资料还原了支撑 ChatGPT 功能的技术细节,梳理了 ChatGPT 技术的整体架构,
解释了 ChatGPT 整体技术构成。按照 ChatGPT 的语料体系、预训练算法与模型、微调算
法与模型三个层次分析 ChatGPT 各技术组件的算法原理与模型组成。【局限】 本文调
研 ChatGPT 相关的文献难免存在遗漏,且对部分技术内容的解读还不够深入,一些由笔
者推断的内容甚至可能存在错误。【结论】 ChatGPT 技术应用的突破,是语料、模型、
算法,通过迭代训练不断积累的结果,也是各类算法模型有效组合与集成的结果。
关键词: ChatGPT ChatGPT 技术 生成式预训练模型 人工智能
DOI:10.11925/infotech.2096-3467.2023.0229
引用本文:钱力, 刘熠, 张智雄等. ChatGPT 的技术基础分析[J]. 数据分析与知识
发现, 2023, 7(3):6-15. ( Qian Li, Liu Yi, Zhang Zhixiong,et al. An Analysis on the Basic
Technologies of ChatGPT[J]. Data Analysis and Knowledge Discovery, 2023, 7(3): 6-15.)
01
引言
ChatGPT[1]是由 OpenAI 公司研发的对话系统,能够通过理解和学习人类
的语言进行对话,自推出后不仅在学术界与产业界得到广泛关注,也推动了人工
智能生成技术(Artificial Intelligence Generated Content,AIGC)的快速发展与市
场应用。
ChatGPT 可以从 5 个方面来把握[2]:(1)对外表现是一个聊天机器人:
能够通过学习和理解人类语言与人进行对话,具有依据对话的上下文环境回答问
题的能力,就像人一样与人类进行聊天交流;(2)本质是 AIGC:能够在学习人
类语言和相关领域知识的基础之上,具备智能化的内容创作能力,从而自动生成
特定的内容;(3)关键基础是生成式预训练的转换器(Generative Pre-trained
Transformer,GPT):以生成式的自监督学习为基础,从 TB 级训练数据中学习
隐含的语言规律和模式,训练出千亿级别参数量的大规模语言模型;(4)核心
技术是 InstructGPT:采用基于人类反馈的强化学习(Reinforcement Learning with
Human Feedback,RLHF),让人工智能模型的产出和人类的常识、认知、需求、
价值观保持一致;(5)与前期类似产品相比,主要特点是编造事实大幅下降,
生成的毒内容更少:在一定程度上解决了传统语言模型在复杂多领域的知识利用、
演绎推理、欺骗性反应等方面的缺陷,使回答更具有用性和真实性。
OpenAI 官方在 arXiv 与 GitHub 中公开了 ChatGPT 模型相关的技术内容,很多
学者根据开源信息,从不同的角度对 ChatGPT 技术进行解析[3-4]。本文在这
些研究基础上,广泛收集相关资料,从中理出 ChatGPT 的技术架构,揭示其主要
组成、关键技术及主要原理,对于理解 ChatGPT 所表现出的各项能力有一定的意
义。
本文尝试从技术的整体架构、实施的数据基础、核心的模型算法三个方面进
行探讨性分析,为同行业研究提供体系化的参考借鉴。本文部分内容是在当前公