决策树及应用.docx
版权申诉
76 浏览量
2021-09-13
17:09:05
上传
评论
收藏 1016KB DOCX 举报


各个领域的人工智能实现,常常要涉及这样的问题:从实际问题中提取数据,并从数据中提炼一组数据规
则,以支持知识推理实现智能的功能。知识规则一般以“原因—结果"形式表示。一般地,获取知识规则可以
建模实现.由于推理结果是有限个,即 的取值是有限的,所以这样的建模属于分类问题.利用神经网络可
以实现分类问题建模,但当影响因素变量 的个数较大时,建模后的知识规则不易表示,特别地,当默写变量
的取值缺失时,即使神经网络具有容错性,也会在一定程度上影响分类结果的不确定性 .实际应用中,决定
分类结果可能只是几个主要影响因素取值,不依赖全部因素变量,因此,知识规则的提取,可以转换为这样的
问题:某一分类下哪些变量是主要的影响因素,这些主要影响因素与分类结果的因素规则表示如何获取?决
策树就是解决这些问题的方法之一.
决策树学习算法是一组样本数据集(一个样本数据也可以称为实例)为基础的一种归纳学习算法,它着
眼于从一组无次序、无规则的样本数据(概念)中推理出决策树表示形式的分类规则。假设这里的样本数据
应该能够用“属性-结论”。
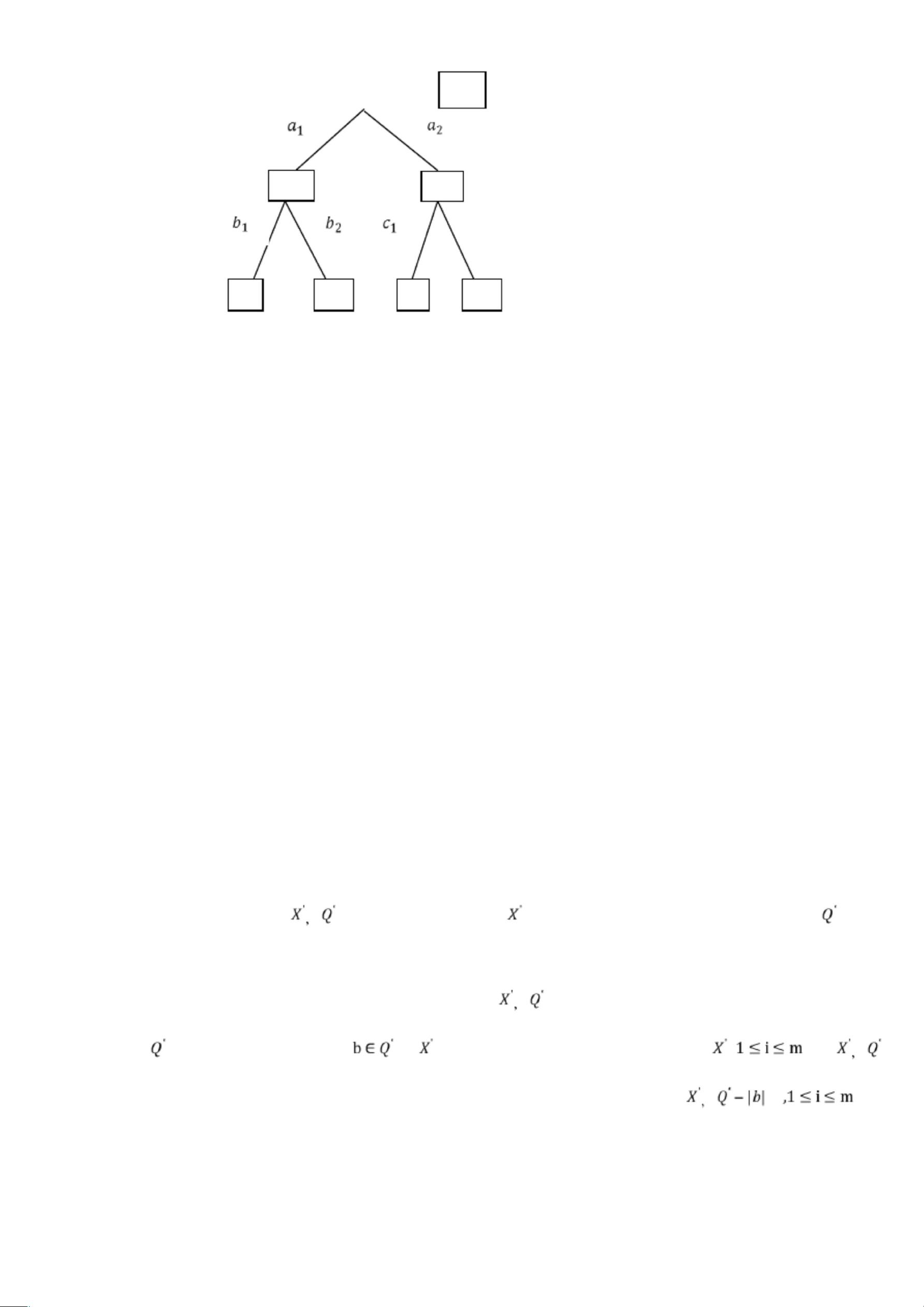
决策时是一个可以自动对数据进行分类的树形结构,是树形结构的知识表示,可以直接转换为分类规则.
它能被看做基于属性的预测模型,树的根节点是整个数据集空间,每个分结点对应一个分裂问题,它是对某个
单一变量的测试,该测试将数据集合空间分割成两个或更多数据块,每个叶结点是带有分类结果的数据分割。
决策树算法主要针对“以离散型变量作为属性类型进行分类”的学习方法。对于连续性变量,必须被离散化
才能被学习和分类。
基于决策树的决策算法的最大的有点就在于它在学习过程中不需要了解很多的背景知识,只从样本数据
及提供的信息就能够产生一颗决策树,通过树结点的分叉判别可以使某一分类问题仅与主要的树结点对应的
变量属性取值相关,即不需要全部变量取值来判别对应的范类。
一颗决策树的内部结点是属性或属性的集合,儿叶结点就是学习划分的类别或结论,内部结点的属性称
为测试属性或分裂属性。
当通过一组样本数据集的学习产生了一颗决策树之后,就可以对一组新的未知数据进行分类。使用决策
树对数据进行分类的时候 ,采用自顶向下的递归方法 ,对决策树内部结点进行属性值的判断比较并根据不同
的属性值决定走向哪一条分支,在叶节点处就得到了新数据的类别或结论。
从上面的描述可以看出从根结点到叶结点的一条路径对应着一条合取规则 ,而整棵决策树对应着一组合
取规则.

剩余14页未读,继续阅读
资源评论













