DB2HADR概述DB2高可用DB2双机热备.pdf
版权申诉
19 浏览量
2022-07-13
22:21:18
上传
评论
收藏 496KB PDF 举报

DB2 HADR 概述
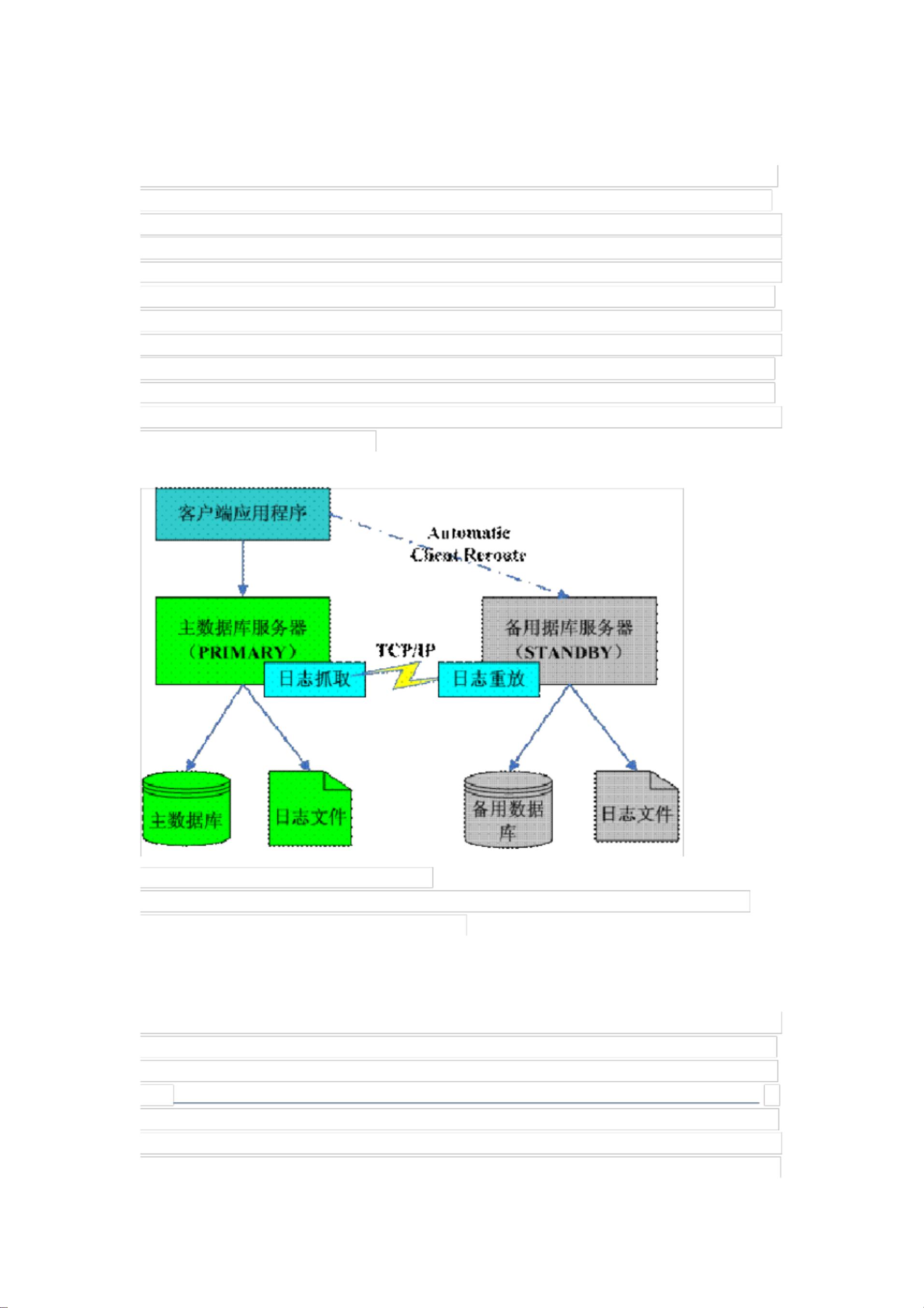
High Availability Disaster Recovery (HADR) 是数据库级别的高可用性数据复制机制,最初
被应用于 Informix 数据库系统中,称为 High Availability Data Replication (HDR )。 IBM
收购 Informix 之后, 这项技术就应用到了新的 DB2 发行版中。 一个 HADR 环境需要两台数
据库服务器:主数据库服务器( primary )和备用数据库服务器( standby )。当主数据库中
发生事务操作时,会同时将日志文件通过 TCP/IP 协议传送到备用数据库服务器,然后备用
数据库对接受到的日志文件进行重放( Replay ),从而保持与主数据库的一致性。当主数
据库发生故障时, 备用数据库服务器可以接管主数据库服务器的事务处理。 此时, 备用数据
库服务器作为新的主数据库服务器进行数据库的读写操作, 而客户端应用程序的数据库连接
可以通过自动客户端重新路由( Automatic Client Reroute )机制转移到新的主服务器。当
原来的主数据库服务器被修复后,又可以作为新的备用数据库服务器加入 HADR 。通过这
种机制, DB2 UDB 实现了数据库的灾难恢复和高可用性,最大限度的避免了数据丢失。下
图为 DB2 HADR 的工作原理图:
注:处于备用角色的数据库不能被访问。
下面我们首先从一个配置实例入手来了解 DB2 HADR 环境的基本配置过程,然后再对
HADR 环境涉及到的一些技术要点展开讨论。
回页首
快速实例上手
要进行这个实例配置过程,你必须拥有 DB2 UDB Enterprise Server Edition (ESE) ,笔者使
用的是 DB2 ESE v8.2.2 for Linux 32bit (在 v8.2 的基础上打了 Fixpack9a )。如果您没有
这个版本,可以到 IBM 官方网站下载试用版(可能需要花点时间填写一些信息),下载链
接: https://www14.software.ibm.com/webapp/iwm/web/preLogin.do?source=db2udbdl 。
另外,笔者使用的是两台 DELL PowerEdge 2850 作为数据库服务器,安装 Redhat Linux
Enterprise Server v4.0 。这两台机器的主机名和 IP 地址分别为: DBSERV1(192.168.1.162 )
和 DBSERV2 (192.168.1.163 )。在下面的配置过程中我们将 DBSERV1 作为主数据库服
资源评论


cjd13107639592
- 粉丝: 0
- 资源: 5万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











