Hadoop分布式文件系统:结构与设计


Hadoop 分布式文件系统:结构与设计
目录
1. 介绍
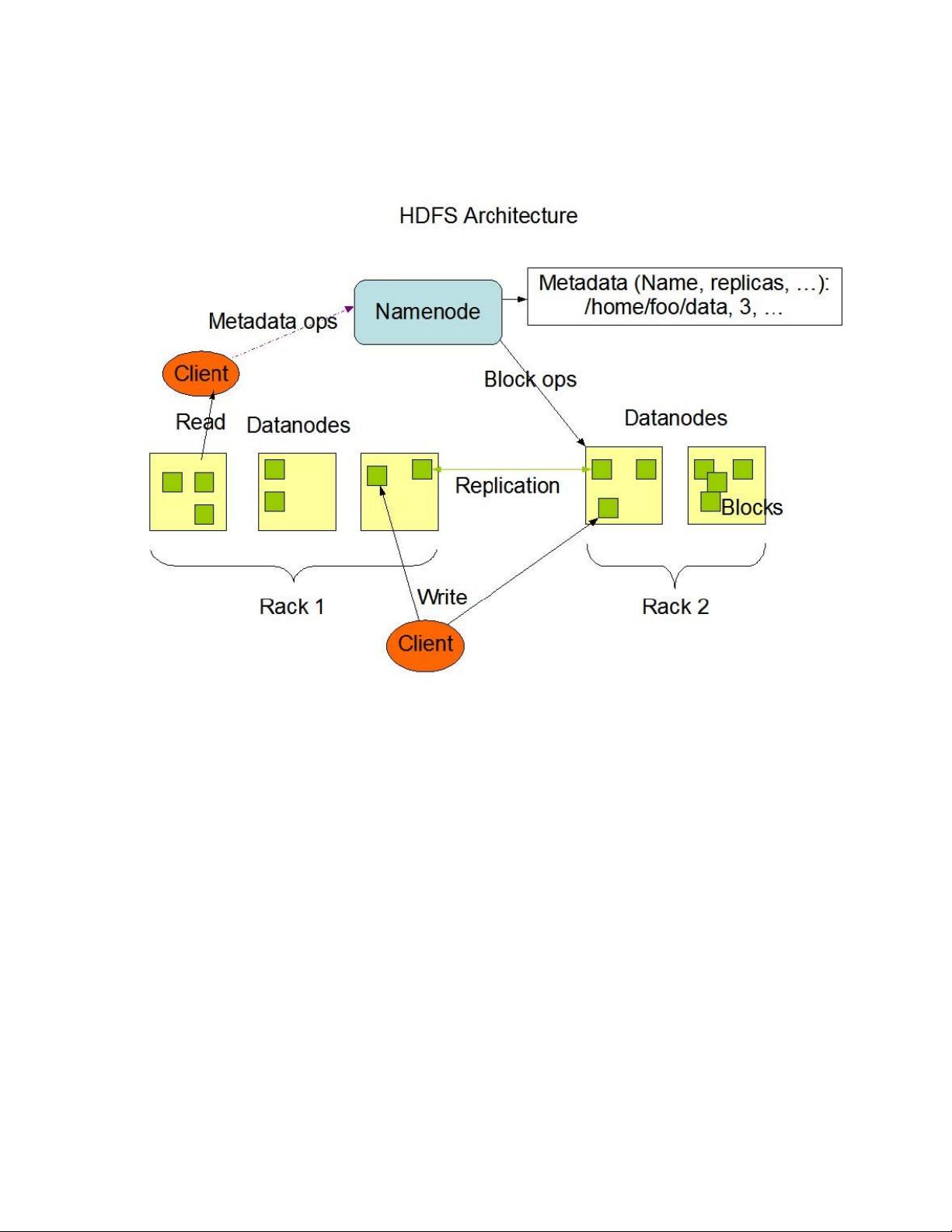
Hadoop 分布式文件系统 (HDFS)是一个设计为用在普通硬件设备上的分布式文件
系统。它与现有的分布式文件系统有很多近似的地方,但又和这些文件系统有很明显的
不同。HDFS 是高容错的,设计为部署在廉价硬件上的。HDFS 对应用程序的数据提供高
吞吐量,而且适用于那些大数据集应用程序。HDFS 开放了一些 POSIX 的必须接口,容
许流式访问文件系统的数据。HDFS 最初是为了 Apache 的 Nutch 网络搜索引擎项目的下
层构件而设计的。是 Hadoop 项目的一部分,而这又是 Apache 的 Lucene 项目的一部分。
本项目的地址是:http://projects.apache.org/projects/hadoop.html。
2. 假设与目标
2.1. 硬件错误
硬件错误是正常的,而不是异常。HDFS 实例由成百上千个服务器组成,每个都
存储着文件系统的一部分数据。事实上,这就会有大量的组件,而每个组件出故障的可
能性都很大,这意味着 HDFS 总有一些组件是不能工作的。因此,检测错误并快速自动
恢复就成了 HDFS 的核心设计目标。
2.2. 流式数据访问
运行在 HDFS 上的应用程序需要流式的访问它们的数据集,它们也不是通常运行
在普通文件系统上的普通应用程序。HDFS 为了那些批量处理而设计的,而不是为普通
用户的交互使用。强调的是数据访问的高吞吐量而不是数据访问的低反应时间。POSIX
强加的很多硬性需求是 HDFS 上应用程序所不需要的, 这些 POSIX 语义在一些关键环
境下被用来提高数据的吞吐频率。
2.3. 大数据集
运行在 HDFS 上的应用程序使用大数据集。HDFS 一个典型的文件可能是几 GB

剩余10页未读,继续阅读
资源评论

 蔚蓝的风2014-02-22这个论文不错,有一定的参考价值
蔚蓝的风2014-02-22这个论文不错,有一定的参考价值












