// segmentGranularity(可选):指定每个segment包含的时间戳的范围。默认为day,用来确定每个
segment包含的时间戳的范围,可以为"SECOND"、"MINUTE"
、"HOUR"、"DAY"、"DOW"、"DOY"、"WEEK"、"MONTH"、"QUARTER"、"YEAR"、"EPOCH"、"DECADE"
、"CENTURY"、"MILLENNIUM"等。
// queryGranularity(可选):默认为None,允许查询的时间粒度,单位与segmentGranularity相
同,如果为None那么允许以任意时间粒度进行查询。
// rollup(可选):是否使用预计算算法,默认为true,推荐true,比较快。
// intervals:用于指定上传时间限制时间段。只有时间段内的数据可以上传。批量数据导入需要设置/流
式导入无需设置。示例:
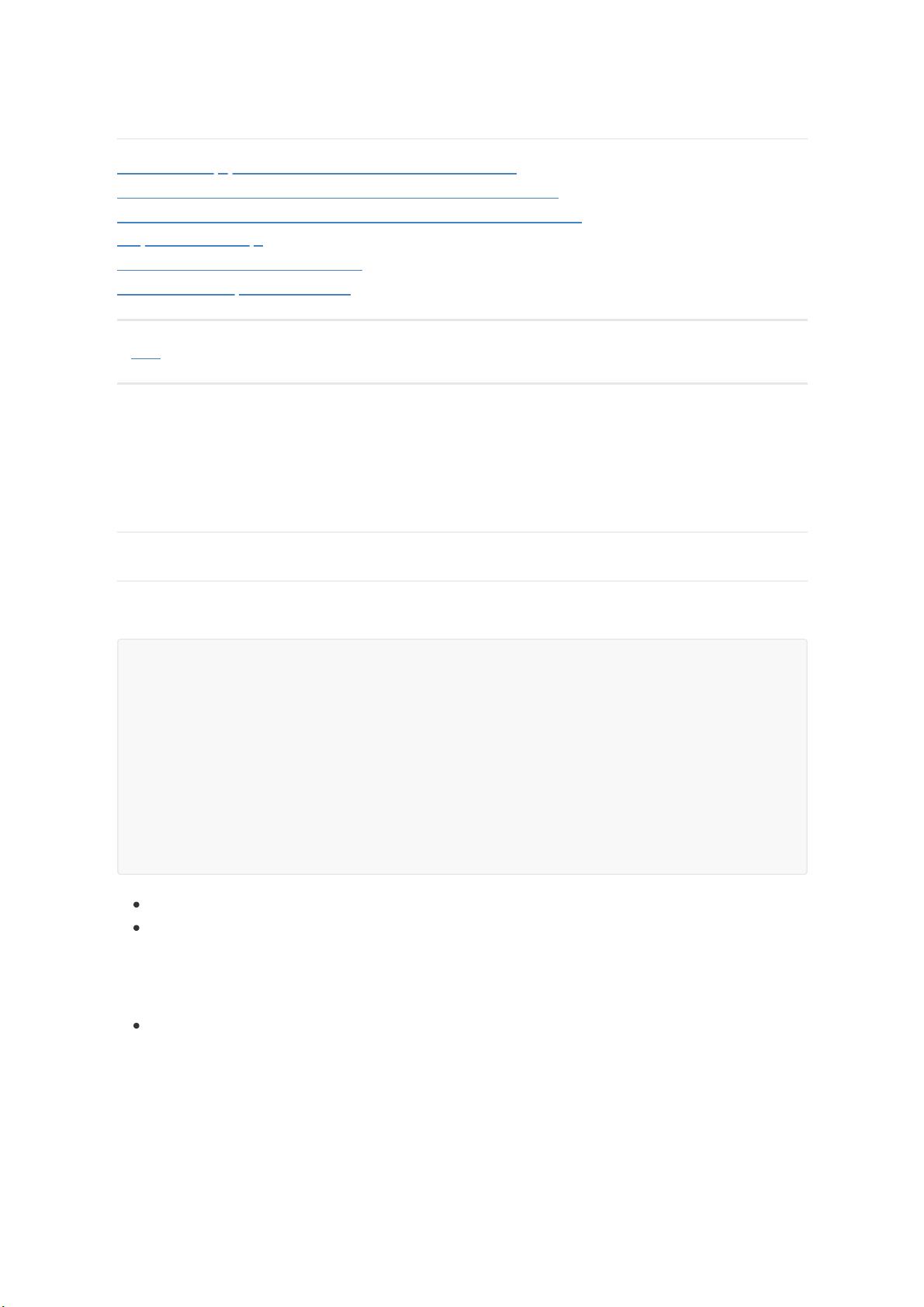
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "DAY",
"queryGranularity" : { "type" : "none"},
"rollup" : "true",
"intervals" : [ "2017-11-15T00:00:00.000Z/2017-11-18T00:00:00.000Z"
]
}
//4、metricsSpec:包含了一系列的aggregators转换
//type可以为:count、longSum、doubleSum、doubleMin\doubleMax、longMin\longMax、
doubleFirst\doubleLast、longFirst\longLast
//除count外其他都需要指定name和fieldName两个参数,name表示最后输出的,也就是在表中体现
的名称,而fieldName则代表源数据中的列名。
//更多说明参考:http://druid.io/docs/0.10.1/querying/aggregations.html
//示例:
"metricsSpec":
[
{"type":"count","name":"count"},
{"type":"doubleSum","name":"added","fieldName":"added"},
{"type":"doubleSum","name":"deleted","fieldName":"deleted"},
{"type":"doubleSum","name":"delta","fieldName":"delta"}
]
//数据摄取模式
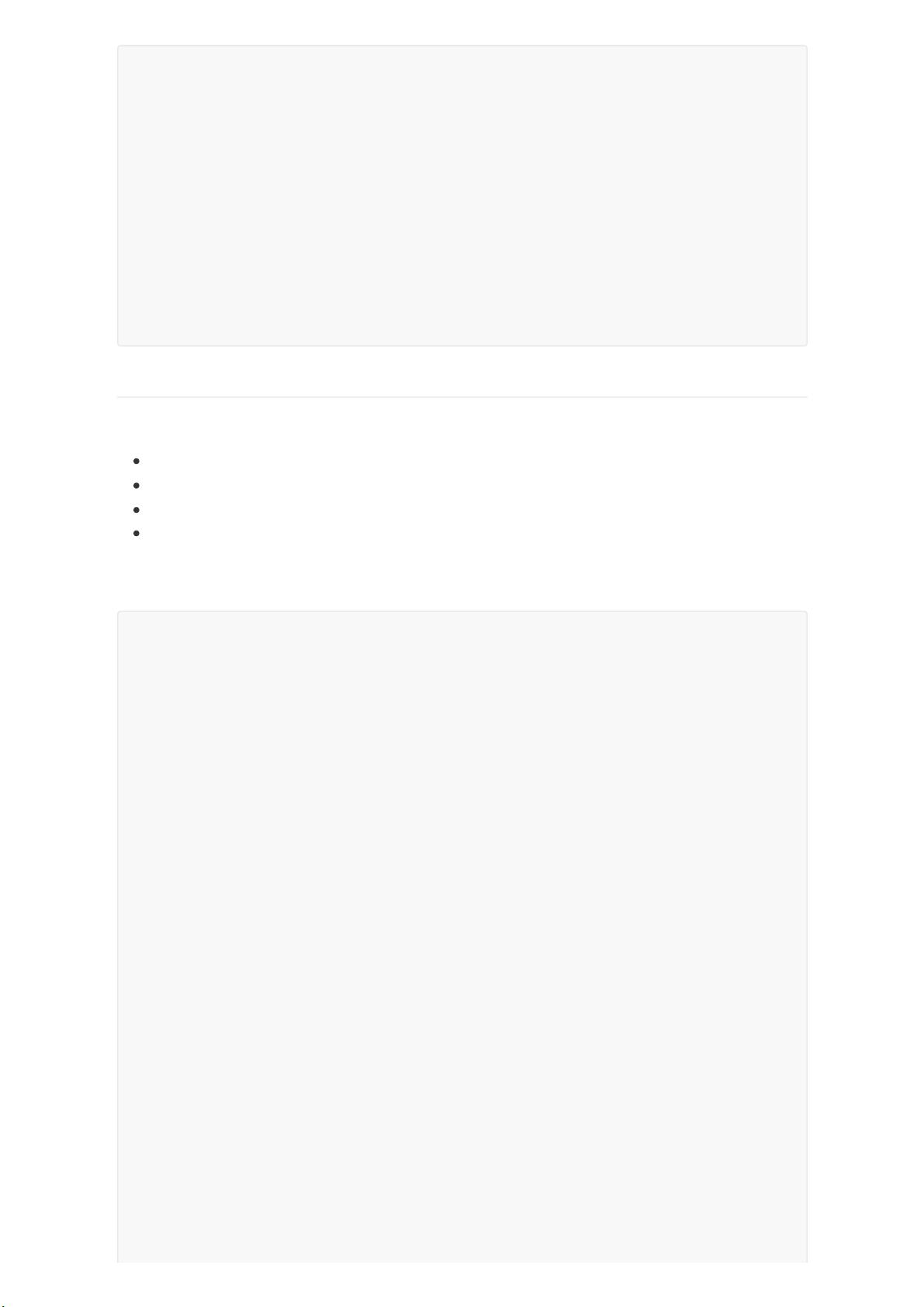
"dataSchema": {
// 数据源(表),数据源名称,用于设置上传数据之后的表名称
"dataSource": "testdata",
// 解析器,用于指定数据怎么被转化,转化为什么格式
"parser": {
// 解析字符串文本
"type": "String",
"parseSpec": {
// 字符串文本格式为JSON
"format": "json",
// 指定维度列名,维度与时间一致,导入时聚合
"dimensionsSpec": {
"dimensions": [
"city",
"platform"
]
},
// 指定时间戳的列,以及时间戳格式化方式