




F M A
Data Wrangling
with pandas
Cheat Sheet
http://pandas.pydata.org
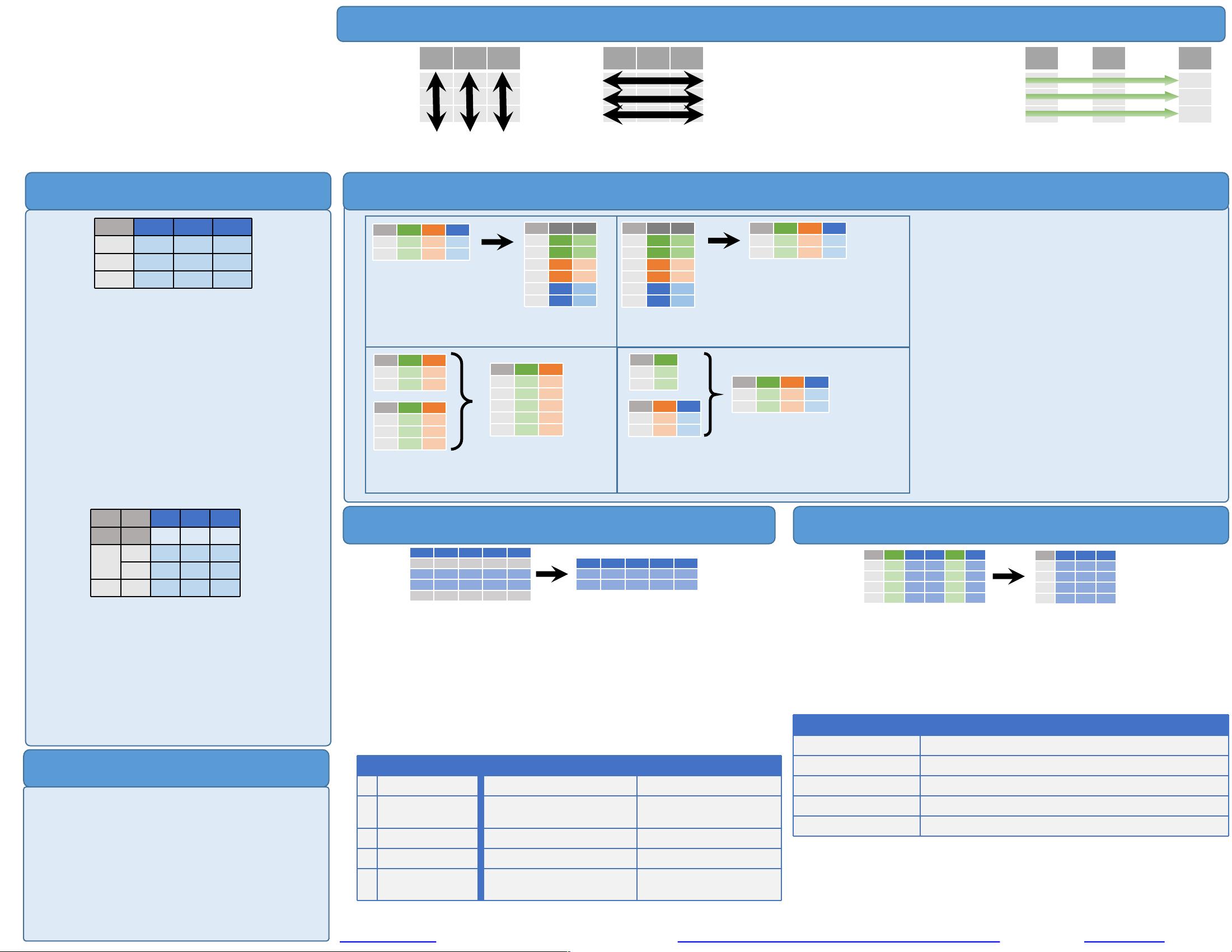
文法 – DataFrameの作成
整然データ(Tidy Data) – pandasにおける議論の基盤
整然データ
において:
F M A
各変数は自身の列に
保存されます
&
各observation は自身の行
に保存されます
整然データはベクトル操作を補完する。
pandasは、あなたが変数を扱うがままに観測を保
存します。他のどのフォーマットもpandasでは直
感的に動きません。
データの整形(Reshaping Data) – データセットのレイアウト変更
M A F
*
M A
*
pd.melt(df)
各column(列)をrow(行)へ.
df.pivot(columns='var', values='val')
各row(行)をcolumn(列)へ
pd.concat([df1,df2])
DataFrameのrow(行)を連結
pd.concat([df1,df2], axis=1)
DataFrameのcolumn(列)を連結
df.sort_values('mpg')
column(列)の値を使ってrow(行)をソート(昇順)
df.sort_values('mpg',ascending=False)
column(列)の値を使ってrow(行)をソート(降順)
df.rename(columns = {'y':'year'})
DataFrameのcolumn(列)名を変更
df.sort_index()
DataFrameのindexを使ってソート
df.reset_index()
DataFrameのindexをリセット
df.drop(columns=['Length','Height'])
指定した長さのcolumn(列)を削除
Observations(行)の一部を抜き出し
変数(列)からの一部取得
a b c
1 4 7 10
2 5 8 11
3 6 9 12
df = pd.DataFrame(
{"a" : [4 ,5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = [1, 2, 3])
各column(列)の値をセットする
df = pd.DataFrame(
[[4, 7, 10],
[5, 8, 11],
[6, 9, 12]],
index=[1, 2, 3],
columns=['a', 'b', 'c'])
各row(行)の値をセットする
a b c
n v
d
1 4 7 10
2 5 8 11
e 2 6 9 12
df = pd.DataFrame(
{"a" : [4 ,5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = pd.MultiIndex.from_tuples(
[('d',1),('d',2),('e',2)],
names=['n','v']))
MultiIndexでDataframeを作成する
メソッドチェーン
pandasにおける多くのメソッドはDataframeを
返します。そのため、メソッドの返り値にそ
のまま別のメソッドを適用するメソッドチェ
ーンが便利に使えます。この手法はコードの
可動性を大いにあげます。
df = (pd.melt(df)
.rename(columns={
'variable' : 'var',
'value' : 'val'})
.query('val >= 200')
)
df[df.Length > 7]
与えられた条件に合った行を抜き出す
df.drop_duplicates()
値の重複するrow(行)を除外
df.head(n)
最初のn行を取得
df.tail(n)
最初のn行を取得
Logic in Python (and pandas)
<
より小さい
!=
等しくない
>
より大きい
df.column.isin(values)
valuesが含まれているcolumn
に場合trueを返す
==
と等しい
pd.isnull(obj)
nullである
<=
以下
pd.notnull(obj)
nullでない
>=
以上
&,|,~,^,df.any(),df.all()
Logical and, or, not, xor, any, all
http://pandas.pydata.org/ This cheat sheet inspired by Rstudio Data Wrangling Cheatsheet (https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf) Written by Irv Lustig, Princeton Consultants
df[['width','length','species']]
複数column(列)を列名を指定して取得
df['width'] or df.width
1つのcolumn(列)を列名を指定して取得
df.filter(regex='regex')
column(列)を正規表現でフィルタリング
df.loc[:,'x2':'x4']
x2からx4までの全てのcolumn(列)を取得
df.iloc[:,[1,2,5]]
1,2,5番目(indexが5番目)の列を取得(indexは0から数える)
df.loc[df['a'] > 10, ['a','c']]
与えられた条件に合ったrow(行)で且つ指定されたcolumn(列)を取得
regex (正規表現) の例
'\.'
ピリオド’.’を含む文字列にマッチ
'Length$'
末尾に’Length’のある文字列にマッチ
'^Sepal'
冒頭に’Sepal’のある文字列にマッチ
'^x[1-5]$'
‘x’で始まり且つ末尾が1~5のいずれかである文字列にマッチ
'^(?!Species$).*'
Species’以外の文字列とマッチ
df.sample(frac=0.5)
行を[frac]ランダムで行を取得
※fracは割合(1 = 100%)
df.sample(n=10)
n行をランダムで取得
df.iloc[10:20]
指定位置の行を取得
df.nlargest(n, 'value')
‘value’列のn行を降順で取得
df.nsmallest(n, 'value')
‘value’列のn行を昇順で取得













