

一、 简介
ChatGLM-6B 清华大学实现的一个开源的、支持中英双语、支持图像理解的
对话语言模型。它基于 General Language Model (GLM) 架构,具有 62 亿参数。
用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显
存)。
使用 ChatGLM-6B 可以实现以下基本的问答:
二、 本地安装部署
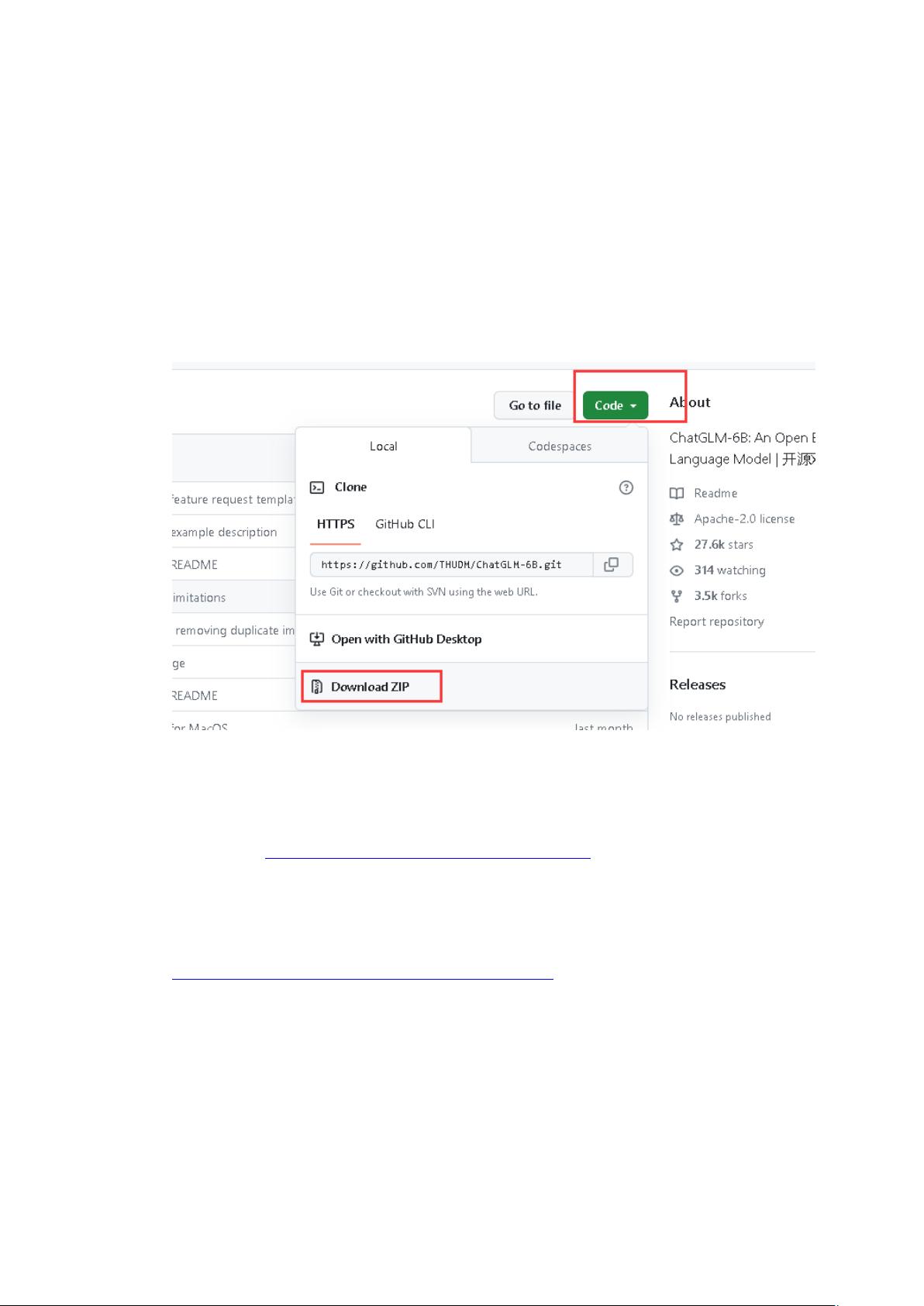
Git 开源地址:https://github.com/THUDM/ChatGLM-6B
1、官方硬件要求
量化等级
最低 GPU 显存(推理)
最低 GPU 显存(高效参数微调)
FP16(无量化)
13 GB
14 GB
INT8
8 GB
9 GB
INT4
6 GB
7 GB
剩余9页未读,继续阅读

阳光宅男xxb
- 粉丝: 1w+
- 资源: 73

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
- 3
- 4
- 5
- 6
前往页