
HBase 在阿里搜索中的应用
HBase 在阿里搜索中的应用在阿里搜索中的应用
HBase 在阿里搜索的历史、规模和服务能力在阿里搜索的历史、规模和服务能力
历史:阿里搜索于 2010 年开始使用 HBase,从最早到目前已经有十余个版本。目前使用的版本是在社区版本的基础上经
过大量优化而成。社区版本建议不要使用 1.1.2版本,有较严重的性能问题,1.1.3 以后的版本体验会好很多。
集群规模:目前,仅在阿里搜索节点数就超过 3000 个,最大集群超过 1500 个。阿里集团节点数远远超过这个数量。
服务能力:去年双11,阿里搜索离线集群的吞吐峰值一秒钟访问超过 4000 万次,单机一秒钟吞吐峰值达到 10 万次。还
有在 CPU 使用量超过 70% 的情况下,单 cpu core 还可支撑 8000+ QPS。
HBase 在阿里搜索的角色和主要应用场景在阿里搜索的角色和主要应用场景
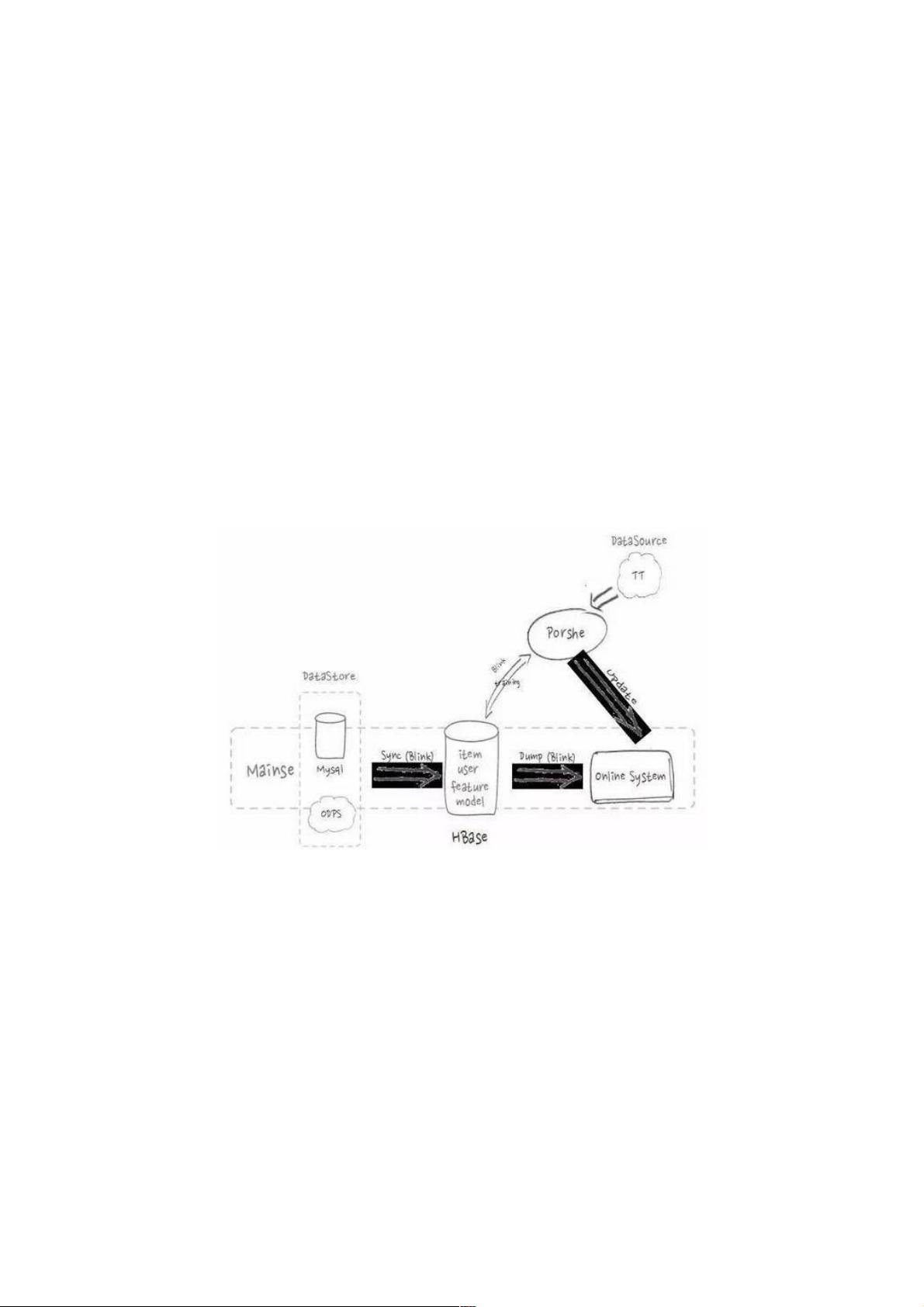
角色:HBase 是阿里搜索的核心存储系统,它和计算引擎紧密结合,主要服务搜索和推荐的业务。
上图是 HBase 在搜索和推荐的应用流程。在索引构建流程中,会从线上 MySQL 等数据库中存储的商品和用户产生的所有
线上数据,通过流式的方式导入到 HBase 中,并提供给搜索引擎构建索引。
在推荐流程中,机器学习平台 Porshe 会将模型和特征数据存储在 HBase 里,并将用户点击数据实时的存入 HBase,通过
在线 training 更新模型,提高线上推荐的准确度和效果。
应用场景一应用场景一
索引构建索引构建
淘宝和天猫有各种各样的的线上数据源,这取决于淘宝有非常多不同的线上店铺和各种用户访问。
剩余7页未读,继续阅读
资源评论

- #完美解决问题
- #运行顺畅
- #内容详尽
- #全网独家
- #注释完整

futengft
- 粉丝: 2









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈













