





1. Java 进程基础
1.1. JPS
首先使用 jps 命令查看 Java 进程 PID
1.2. Dump
使用 jmap -dump:format=b,live,file=文件名 进程 PID,文件名可以使 txt,bin,hprof 等
1.3. 分析工具
下载完 dump 文件之后,需要使用工具来对 dump 文件进行分析,常用的工具有:
Memory Analyzer(mat)——免费
下载地址:https://www.eclipse.org/mat/downloads.php
如果最新版本提示 jdk 版本比较低,而你本机还是 jdk8 的话,可以下载 1.8.1
的版本进行使用
历史版本下载地址:https://www.eclipse.org/mat/previousReleases.php
JPROFILER——收费,可以试用 10 天
下载地址:https://www.ej-technologies.com/download/jprofiler/files

1.4. 频繁 FGC 解决方案
一、概述
系统上线会出现 GC 相关问题,有 FGC 过于频繁的,有 YoungGC 耗时过长的。
GC 过程会导致其他线程 STW,进一步导致服务器响应超时。
二、解决
1. 通过可视化工具(JvisualVM 或 MAT)或者终端命令行查看每次 GC 之后
的情况
2. 如果每次 GC 之后内存都没有释放空间的话,这就可能是内存泄露的问题。
3. 接下来查看 heap dump 文件,对堆内存中的对象进行查看,进行大小排
序。
4. 观察代码,发现错误。
5. 可以设置扩大 CMS 收集器的分代年龄,YGC 中存活对象转为老年代的对
象次数增多。
三、GC 什么时候发生?
YGC
大多数情况下,对象直接在年轻代中的 Eden 区进行分配,如果 Eden 区域没
有足够的空间,那么就会触发 YGC(Minor GC),YGC 处理的区域只有新生代。
因为大部分对象在短时间内都是可收回掉的,因此 YGC 后只有极少数的对象能
存活下来,而被移动到 S0 区(采用的是复制算法)。当触发下一次 YGC 时,会
将 Eden 区和 S0 区的存活对象移动到 S1 区,同时清空 Eden 区和 S0 区。当再次
触发 YGC 时,这时候处理的区域就变成了 Eden 区和 S1 区(即 S0 和 S1 进行角色
交换)。每经过一次 YGC,存活对象的年龄就会加 1。
FGC
下面四种情况,对象会进入到老年代。当老年代内存不够会触发 FGC:
� YGC 时,To Survivor 区不足以存放存活的对象,对象会直接进入到老年代。
� 经过多次 YGC 后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。
� 动态年龄判定规则,To Survivor 区中相同年龄的对象,如果其大小之和占到了 To
Survivor 区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达
到默认的分代年龄。
� 大对象:由-XX:PretenureSizeThreshold 启动参数控制,若对象大小大于此值,就会绕
过新生代, 直接在老年代中分配。

除此之外,以下情况也会触发 FGC:
� System.gc() 或者 Runtime.gc() 被显式调用时,触发 FGC。
� Metaspace(元空间)在空间不足时会进行扩容,当扩容到了-XX:MetaspaceSize 参
数的指定值时,也会触发 FGC。
� 老年代的内存使用率达到了一定阈值(可通过参数调整),直接触发 FGC。
� 空间分配担保:在 YGC 之前,会先检查老年代最大可用的连续空间是否大于新生代
所 有 对 象 的 总 空 间 。 如 果 小 于 , 说 明 YGC 是 不 安 全 的 , 则 会 查 看 参 数
HandlePromotionFailure 是否被设置成了允许担保失败,如果不允许则直接触发 Full
GC;如果允许,那么会进一步检查老年代最大可用的连续空间是否大于历次晋升到
老年代对象的平均大小,如果小于也会触发 Full GC。
四、什么情况下 GC 会对程序造成影响
不管 YGC 还是 FGC,都会造成一定程度的程序卡顿(即 Stop The World 问题:
GC 线程开始工作,其他工作线程被挂起),即使采用 ParNew、CMS 或者 G1 这
些更先进的垃圾回收算法,也只是在减少卡顿时间,而并不能完全消除卡顿。
那到底什么情况下,GC 会对程序产生影响呢?根据严重程度从高到底,我
认为包括以下 4 种情况:
�
FGC 过于频繁:FGC 通常是比较慢的,少则几百毫秒,多则几秒,正常情
况 FGC 每隔几个小时甚至几天才执行一次,对系统的影响还能接受。但
是,一旦出现 FGC 频繁(比如几十分钟就会执行一次),这种肯定是存
在问题的,它会导致工作线程频繁被停止,让系统看起来一直有卡顿现象,
也会使得程序的整体性能变差。
�
� YGC 耗时过长:一般来说,YGC 的总耗时在几十或者上百毫秒是比较正常的,虽然
会引起系统卡顿几毫秒或者几十毫秒,这种情况几乎对用户无感知,对程序的影响
可以忽略不计。但是如果 YGC 耗时达到了 1 秒甚至几秒(都快赶上 FGC 的耗时
了),那卡顿时间就会增大,加上 YGC 本身比较频繁,就会导致比较多的服务超时
问题。
� FGC 耗时过长:FGC 耗时增加,卡顿时间也会随之增加,尤其对于高并发服务,可
能导致 FGC 期间比较多的超时问题,可用性降低,这种也需要关注。
� YGC 过于频繁:即使 YGC 不会引起服务超时,但是 YGC 过于频繁也会降低服务的整
体性能,对于高并发服务也是需要关注的。
其中,「FGC 过于频繁」和「YGC 耗时过长」,这两种情况属于比较典型的
GC 问题,大概率会对程序的服务质量产生影响。剩余两种情况的严重程度低一
些,但是对于高并发或者高可用的程序也需要关注。
五、实践指南

通过上面的案例分析以及理论介绍,再总结下 FGC 问题的排查思路,作为
一份实践指南供大家参考。
1. 清楚从程序角度,有哪些原因导致 FGC?
� 大对象:系统一次性加载了过多数据到内存中(比如 SQL 查询未做分页),导致大
对象进入了老年代。
� 内存泄漏:频繁创建了大量对象,但是无法被回收(比如 IO 对象使用完后未调用 close
方法释放资源),先引发 FGC,最后导致 OOM.
� 程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会
进入老年代,最后引发 FGC. (即本文中的案例)
� 程序 BUG
� 代码中显式调用了 gc 方法,包括自己的代码甚至框架中的代码。
� JVM 参数设置问题:包括总内存大小、新生代和老年代的大小、Eden 区和 S 区的大
小、元空间大小、垃圾回收算法等等。
2. 清楚排查问题时能使用哪些工具
� 公司的监控系统:大部分公司都会有,可全方位监控 JVM 的各项指标。
� JDK 的自带工具,包括 jmap、jstat 等常用命令:
# 查看堆内存各区域的使用率以及 GC 情况
jstat -gcutil -h20 pid 1000
# 查看堆内存中的存活对象,并按空间排序
jmap -histo pid | head -n20
# dump 堆内存文件
jmap -dump:format=b,file=heap pid
� 可视化的堆内存分析工具:JVisualVM、MAT 等
3. 排查指南
� 查看监控,以了解出现问题的时间点以及当前 FGC 的频率(可对比正常情况看频率
是否正常)
� 了解该时间点之前有没有程序上线、基础组件升级等情况。
� 了解 JVM 的参数设置,包括:堆空间各个区域的大小设置,新生代和老年代分别采
用了哪些垃圾收集器,然后分析 JVM 参数设置是否合理。
� 再对步骤 1 中列出的可能原因做排除法,其中元空间被打满、内存泄漏、代码显式
调用 gc 方法比较容易排查。
� 针对大对象或者长生命周期对象导致的 FGC,可通过 jmap -histo 命令并结合 dump
堆内存文件作进一步分析,需要先定位到可疑对象。
� 通过可疑对象定位到具体代码再次分析,这时候要结合 GC 原理和 JVM 参数设置,
弄清楚可疑对象是否满足了进入到老年代的条件才能下结论。
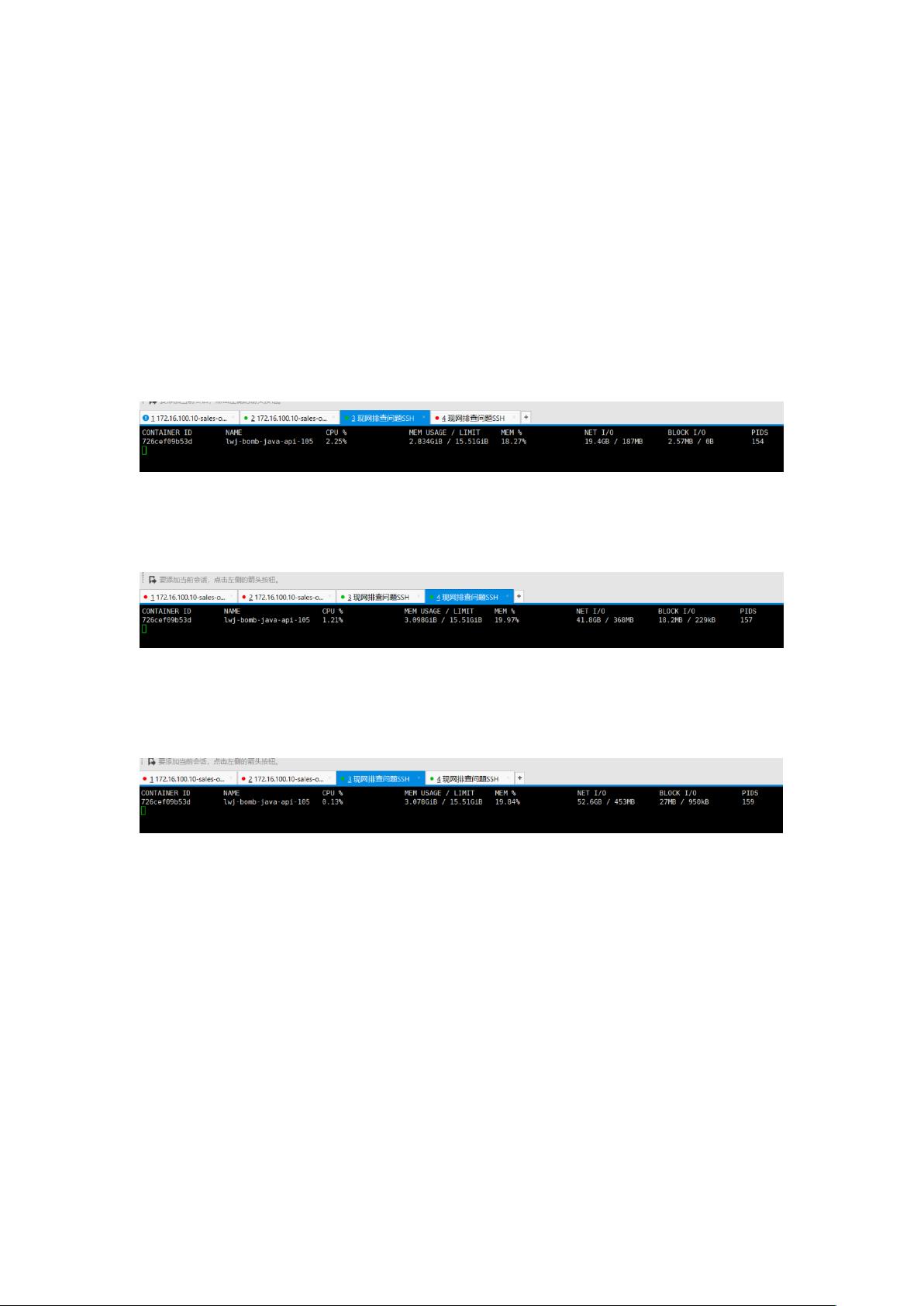
2. 容器相关输出
2.1. Stats---LIMIT 默认 15.51GB 默认不受限
sudo docker stats lwj-bomb-java-api-105
2.1.1. 11:30
2.1.2. 14:26
2.1.3. 15:48
2.2. inspect 检查信息
sudo docker inspect lwj-bomb-java-api-105
2.2.1. 11:30
[
{
"Id": "726cef09b53d8923abebb4403a3bb76e7dc0f7dc0fd8b6218073216e40178e9e",
"Created": "2022-11-11T01:10:26.852675421Z",













