[] - 2023-12-10 一文搞懂SQL执行顺序.pdf

需积分: 0 59 浏览量
更新于2023-12-11
收藏 488KB PDF 举报
SQL执行顺序是数据库查询中非常关键的一个概念,它决定了数据如何被处理和返回。这篇2023-12-10的文章详细介绍了SQL语句的执行流程,帮助读者理解如何构建高效的查询。
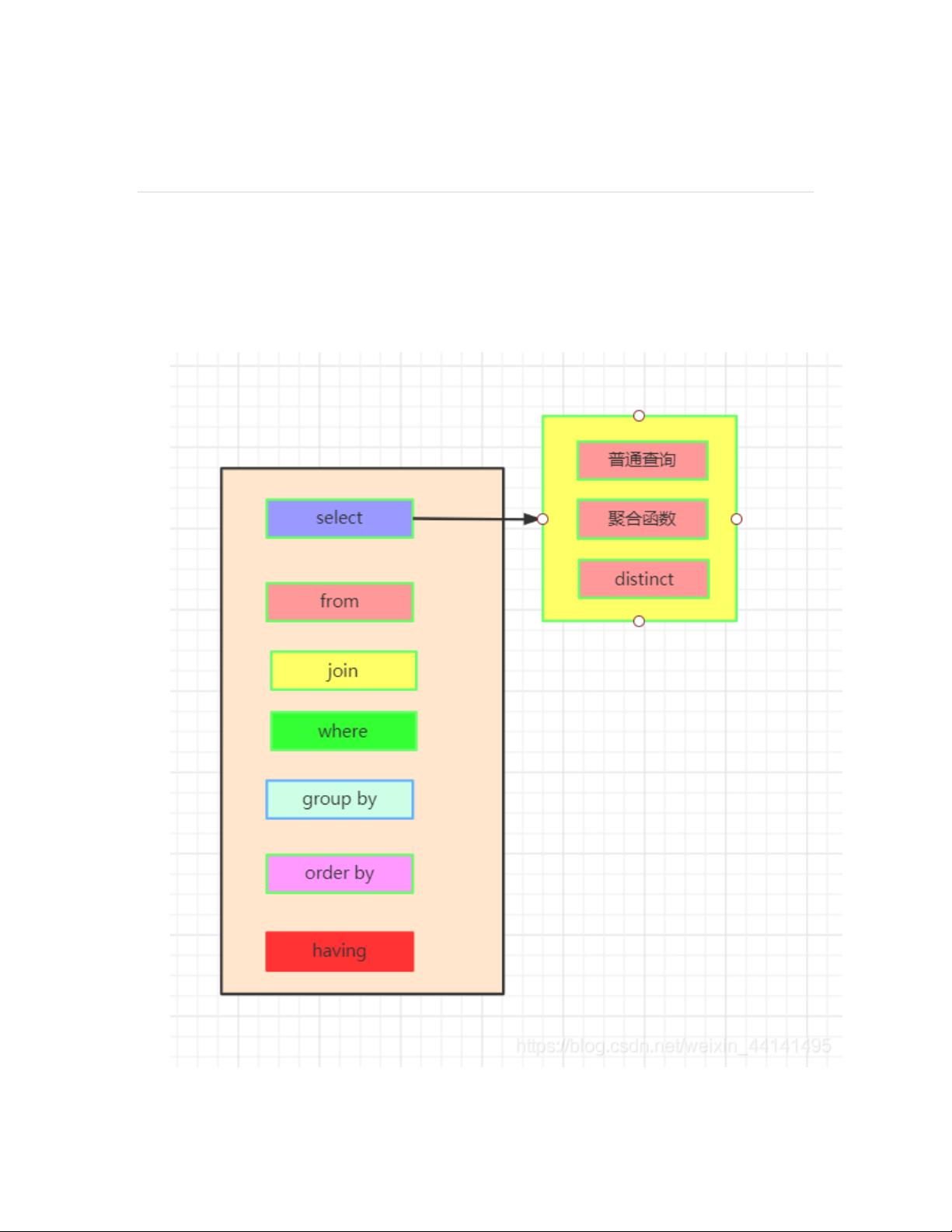
从SQL语句的结构出发,执行顺序如下:
1. FROM或JOIN:这部分用于确定查询涉及的表以及它们之间的连接关系。例如,通过`FROM table1 JOIN table2 ON table1.id = table2.id`,我们可以连接两个表,并基于指定的条件(如ID相等)来组合数据。如果省略JOIN,直接列出多个表,如`FROM table1, table2`,则会生成一个笛卡尔积,即所有可能的表间行组合。
2. WHERE:这个阶段用于过滤不符合特定条件的行。WHERE子句通常包含比较操作符,如等于、大于、小于等,用于限制返回的结果集。
3. GROUP BY:这一部分用于将数据按一个或多个列进行分组。GROUP BY允许我们对每个分组应用聚合函数(如SUM, AVG, COUNT等),但不会直接删除不符合条件的行。
4. HAVING:HAVING与WHERE类似,但它用于过滤GROUP BY后的结果。HAVING可以包含普通条件,但更重要的是,它可以与聚合函数一起使用,而WHERE则不能。
5. SELECT:SELECT用于定义要从数据库中检索的列。在这个步骤中,聚合函数(如AVG, SUM)会为每个分组创建一个新的结果列。如果存在重复的列名,需要明确指定其来源,避免命名冲突。
6. DISTINCT:DISTINCT关键字用于去除查询结果中的重复行,确保返回的每一行都是唯一的。
7. ORDER BY:ORDER BY用于对查询结果进行排序。可以按照一个或多个列进行升序或降序排列。如果使用LIMIT来限制返回的行数,应确保ORDER BY在LIMIT之前执行,否则可能会得到错误的排序结果。
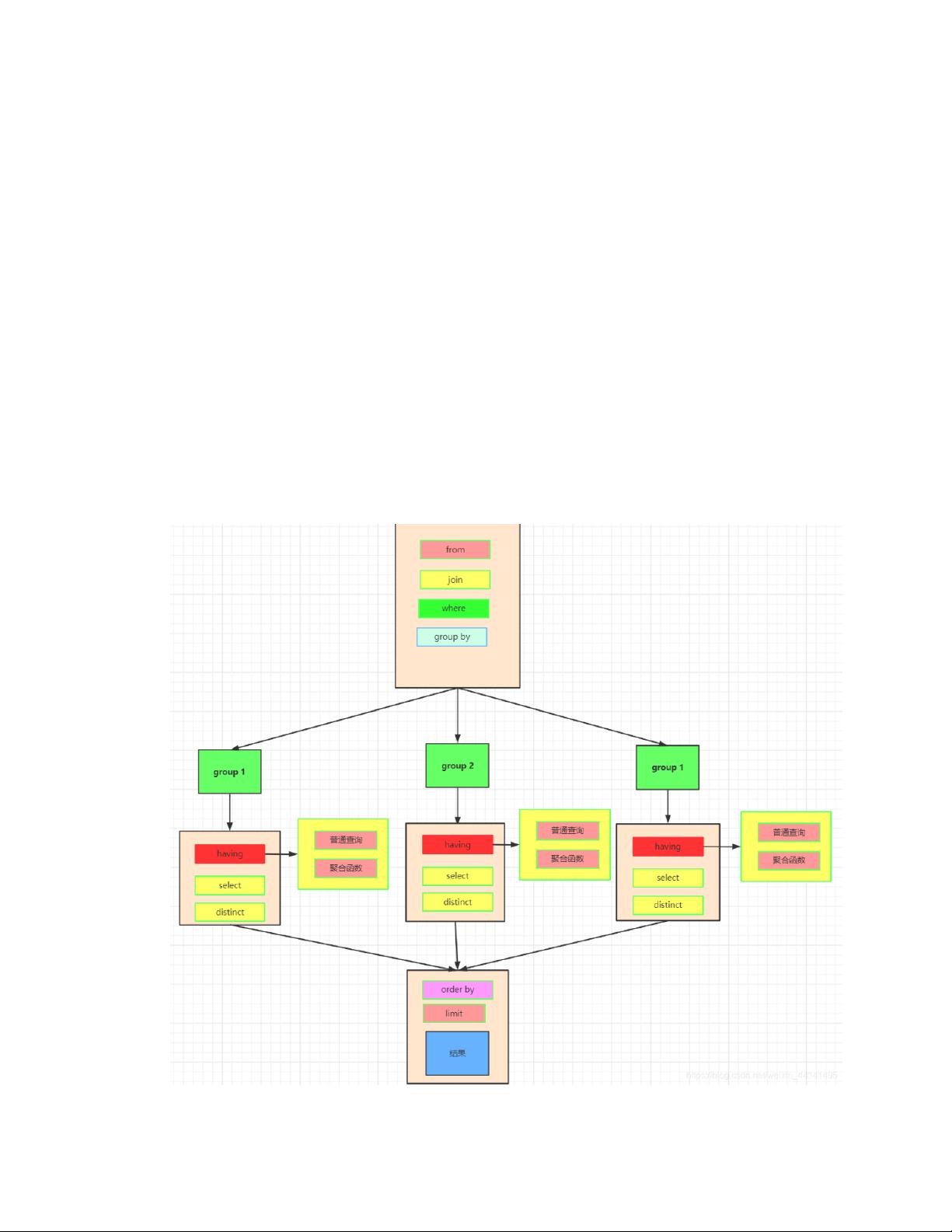
举例来说,如果我们有一个包含员工工资的数据集,要找出每个部门中工资低于平均值的员工,可以先使用GROUP BY按部门分组,然后用HAVING筛选出工资低于各自部门平均工资的员工。
在实际应用中,理解SQL执行顺序对于优化查询性能至关重要。正确地使用JOIN、WHERE、GROUP BY和HAVING可以帮助减少处理的数据量,提高查询效率。同时,ORDER BY和LIMIT的正确使用可以确保返回的数据满足预期的顺序和数量,避免不必要的计算。通过掌握这些基本原理,开发者可以更好地设计和调试复杂的SQL查询,以适应不断变化的数据库需求。
剩余9页未读,继续阅读
133 浏览量
151 浏览量
2024-07-28 上传
2021-09-03 上传
174 浏览量
113 浏览量
2020-05-28 上传
199 浏览量
2024-05-05 上传
176 浏览量
资源评论


毕业小助手
- 粉丝: 2762
- 资源: 5583









最新资源
- java毕设项目之ssm基于Vue.js的在线购物系统的设计与实现+vue(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm汽车养护管理系统+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm简易版营业厅宽带系统+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm绿色农产品推广应用网站+vue(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm人事管理信息系统+jsp(完整前后端+说明文档+mysql+lw).zip
- 自考04741《计算机网络原理》试题及答案2016-2018
- java毕设项目之ssm社区管理与服务的设计与实现+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm社区文化宣传网站+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm实验室耗材管理系统设计与实现+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm网络游戏公司官方平台设计与实现+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm蜀都天香酒楼的网站设计与实现+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm网上医院预约挂号系统+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm网上花店设计+vue(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm网上服装销售系统+jsp(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm小型企业办公自动化系统的设计和开发+vue(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之ssm物流管理系统设计与实现+jsp(完整前后端+说明文档+mysql+lw).zip
