






如何开网店 http://www.shangjiawang.com/ 减肥药排行榜 http://www.syaoo.com/
DedeCMSV5.6 版自动采集功能规则使用基本知识讲解教程 (一)
2011-05-05 17:09:01 来源 : 作者 : 【大 中 小】 浏览 :5026 次 评论 :0 条 ★★我要投稿★★
将此页添加到网摘:
DedeCMS采集功能使用基本知 识讲 解
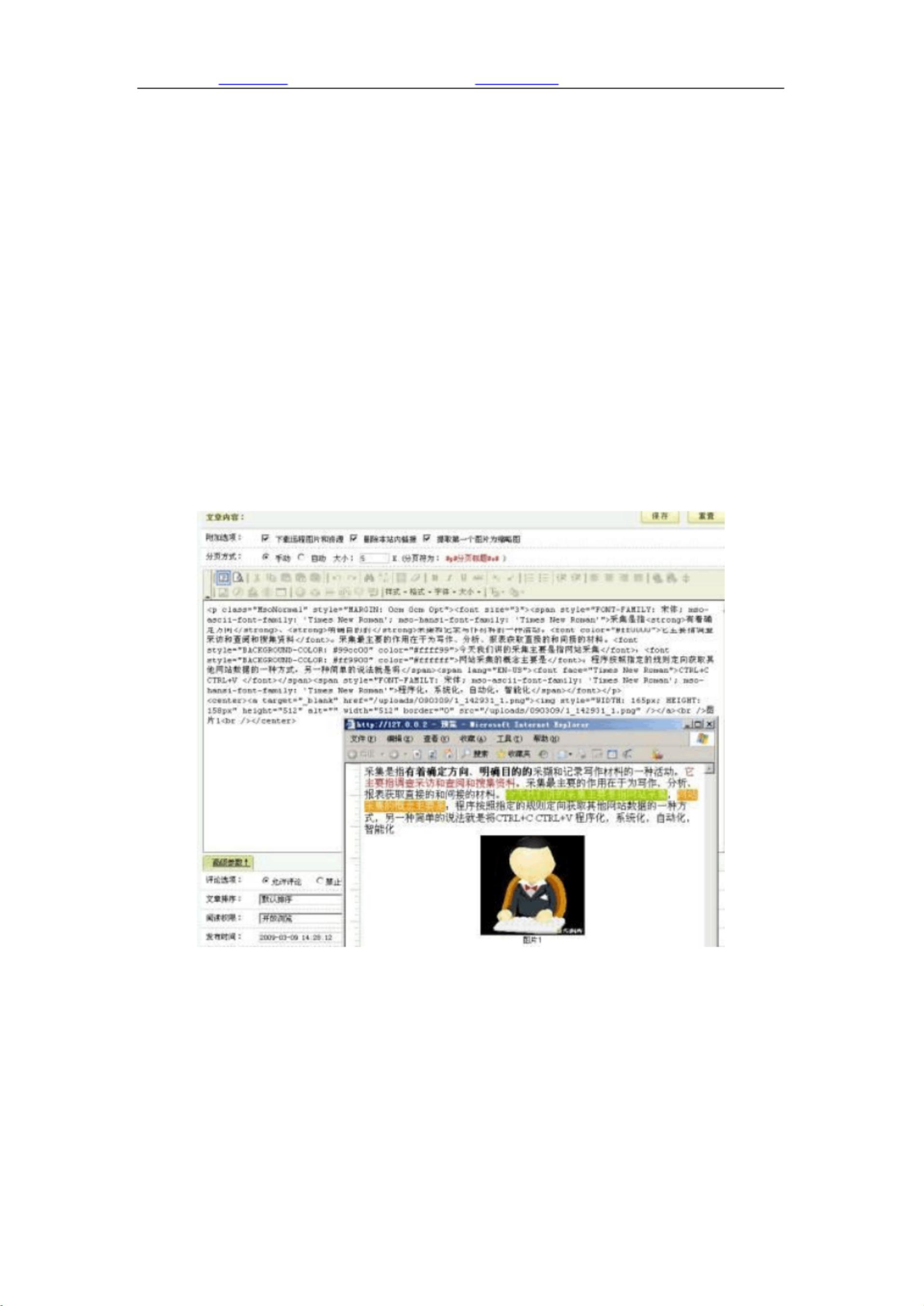
采集是指有着确定方向、 明确目的的采撷和记录写作材料的一种活动。 它主要指
调查采访和查阅和搜集资料。 采集最主要的作用在于为写作、 分析、 报表获取直
接的和间接的材料。 今天我们讲的采集主要是指网站采集, 网站采集的概念主要
是:程序按照指定的规则定向获取其他网站数据的一种方式, 另一种简单的说法
就是将 CTRL+C CTRL+V 程序化,系统化,自动化,智能化
DedeCMS 早期就已经加入了这个采集的功能,以前我们添加网站内容一般都是
通过复制、粘贴、编辑然后再发布,这样对于少量的文章还是可以,但如果对于
一个新站,什么内容都没有,那就需要复制粘提大量的文章,这是一个重复、枯
燥的过程, 内容采集就是解决这个问题, 将这个重复的操作简化成规则, 通过规
则进行批量操作。
当然采集还可以通过一些专门的采集器来进行采集, 国内比较出名的采集器有火
车头。
今天我们这里以 DedeCMS 程序自带的采集功能来讲解如何使用采集,并介绍如
何对采集的内容进行一些批量的管理。


剩余30页未读,继续阅读
资源评论

- #完美解决问题
- #运行顺畅
- #内容详尽
- #全网独家
- #注释完整

XWJcczq
- 粉丝: 2
- 资源: 7万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- HCIP作业1 这里面是完成的ensp的拓扑图
- 9月最新H5爆点火箭源码竞猜区块链修复推广完美+免公众号接口+防风+完整搭建视频
- DC靶场系列-DC1靶场-渗透测试靶场
- WordPress插件微信公众号涨粉插件
- linux下 jq 截取json文件信息
- 2001-2023年 中国证券期货统计年鉴.zip
- 价值29800元最新商业版陪玩3.0独立版本系统最新公众号h5版源码
- linux下 jq 截取json文件信息
- DeepSeek入门宝典系列.zip
- HTML+CSS学习笔记.pdf
- 簡易瀏覽器python
- HTML+CSS+JavaScript学习笔记.pdf
- [AB PLC例程源码][MMS_042504]Logix5000 interface to Atlas-Copco Tool Controller over EtherNet-IP.zip
- [AB PLC例程源码][MMS_042497]Using Phase Manager to Build a Scalable Batching Solution.zip
- [AB PLC例程源码][MMS_043071]Phase Manager and a Scalable Batching Solution.zip
- [AB PLC例程源码][MMS_039839]Copying a DINT variable to Ebool array, Count n.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈
























