关于ChatGPT的五个最重要问题.pdf
需积分: 1 3 浏览量
2023-05-29
15:55:29
上传
评论
收藏 3.07MB PDF 举报


关于 ChatGPT 的五个最重要问题
我们判断,如果 ChatGPT 不犯大错,两年之内,整个科技行业甚至人类社会都会被颠覆一
遍。倒计时已经开始了。
在 ChatGPT 纪元中,提问题的能力和判断力也许是人类最重要的两个能力。我们这里提出五
个关键问题,并且试图抛开网络上的二手观点,做出基于原理的判断。
更详细的科普文可以参考这篇:了解 AIGC 中的 ChatGPT 和 LLM
其中包含如何在公司快速便捷地使用 ChatGPT
针对中台业务场景的应用:ChatGPT 在中台业务应用的可能性与探索
这篇文章会尽量用准确的说明与类比(如何区分准确的类比和偷换概念的类比)去解读技术。
但是对于这样一个非常新、非常颠覆、大家对原理和应用都还没形成共识的技术,不了解技术
细节就去打比方,难免信口开河。所以我们会先尽量无损地把需要的技术细节都盘清楚,然后
再去进行抽象和提取本质。
哪五个问题?
1. 是什么:ChatGPT 是范式突破吗?和过往 AI 有什么不同?
2. 会怎样:ChatGPT 两年内会达到什么水准?
3. 行业格局:ChatGPT 以及 GPT 有壁垒吗?
4. 如何参与:我们未来应该如何使用 ChatGPT?
5. 人文:人类和 ChatGPT 的本质区别是什么?对人类社会的冲击?
还有一个不需要讨论的重要问题:ChatGPT 不会开源的,因为 AGI 是一个危险品。国内那些依
赖开源+抄的公司可以死心了。指望原子弹开源吗?
我们搞清楚这五个问题,就能判断市面上大多数解读 ChatGPT 的观点,无论从技术、商业、
投资,等等角度,是否靠谱了。其实就两个关键
1. 对 ChatGPT 新能力的认知:这新能力是什么,有什么意义?
2. 对“能力获取难度”的认知:ChatGPT 如何获得的?难度有多大?
文章结尾我们会做一下总结。让你下次见到某大模型,可以判断这是 ChatGPT 的 80%还是



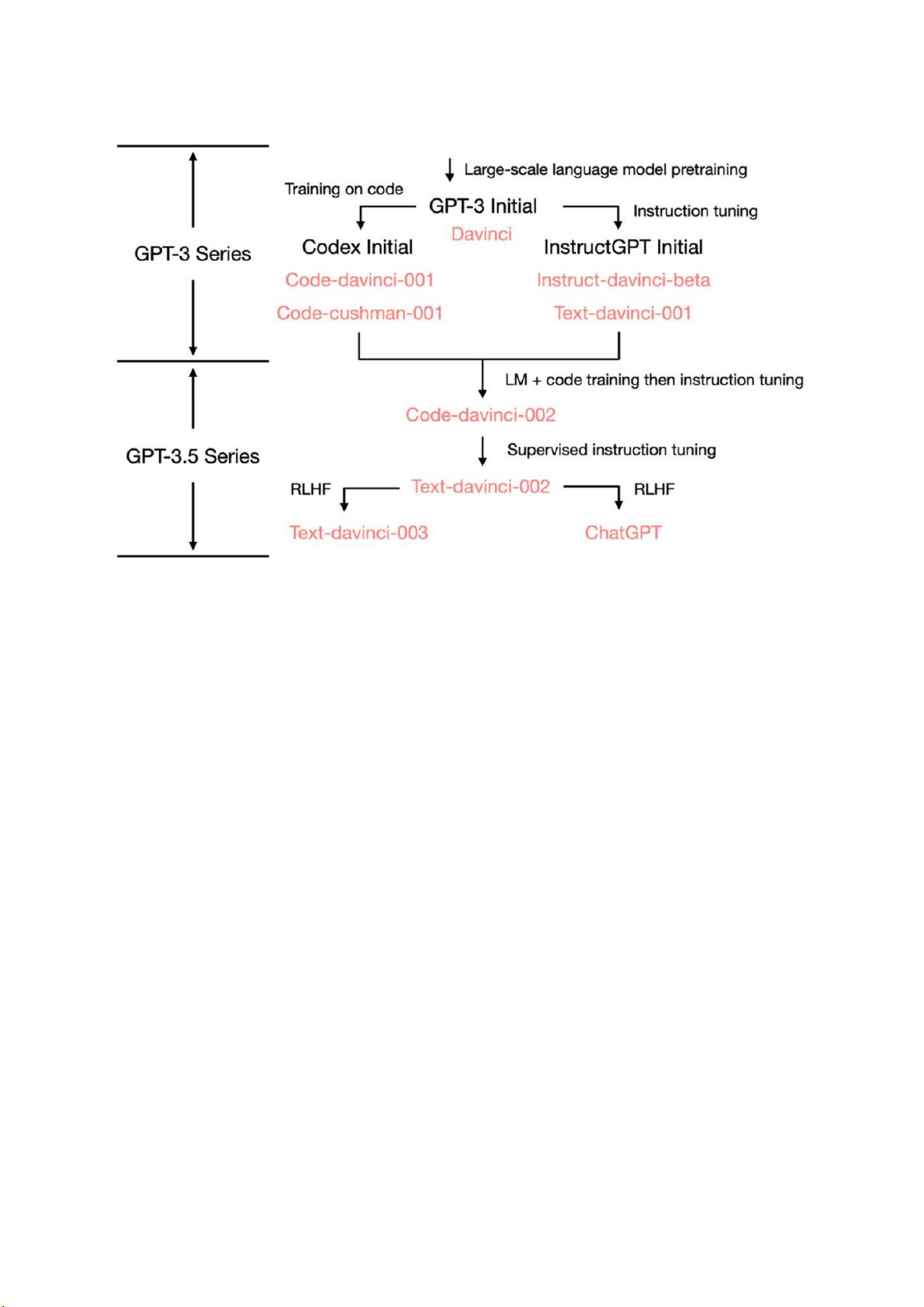
剩余27页未读,继续阅读
资源评论


Wis57
- 粉丝: 304
- 资源: 450









最新资源
- 基于yolov5识别算法实现的DNF自动脚本源码.zip
- 基于Python实现的自动化办公项目.zip
- 基于python实现的基于PyQt5和爬虫的小说阅读系统.zip
- 机械设计整经机上纱自动化sw20非常好的设计图纸100%好用.zip
- Screenshot_20240427_031602.jpg
- 网页PDF_2024年04月26日 23-46-14_QQ浏览器网页保存_QQ浏览器转格式(6).docx
- 直接插入排序,冒泡排序,直接选择排序.zip
- 在排序2的基础上,再次对快排进行优化,其次增加快排非递归,归并排序,归并排序非递归版.zip
- 实现了7种排序算法.三种复杂度排序.三种nlogn复杂度排序(堆排序,归并排序,快速排序)一种线性复杂度的排序.zip
- 冒泡排序 直接选择排序 直接插入排序 随机快速排序 归并排序 堆排序.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


