



2023/6/28 22:31
击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式
https://mp.weixin.qq.com/s/oMUASBSKe3xgGVLuQz7MGg
2/14

2023/6/28 22:31
击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式
https://mp.weixin.qq.com/s/oMUASBSKe3xgGVLuQz7MGg
3/14
瞬间清醒!
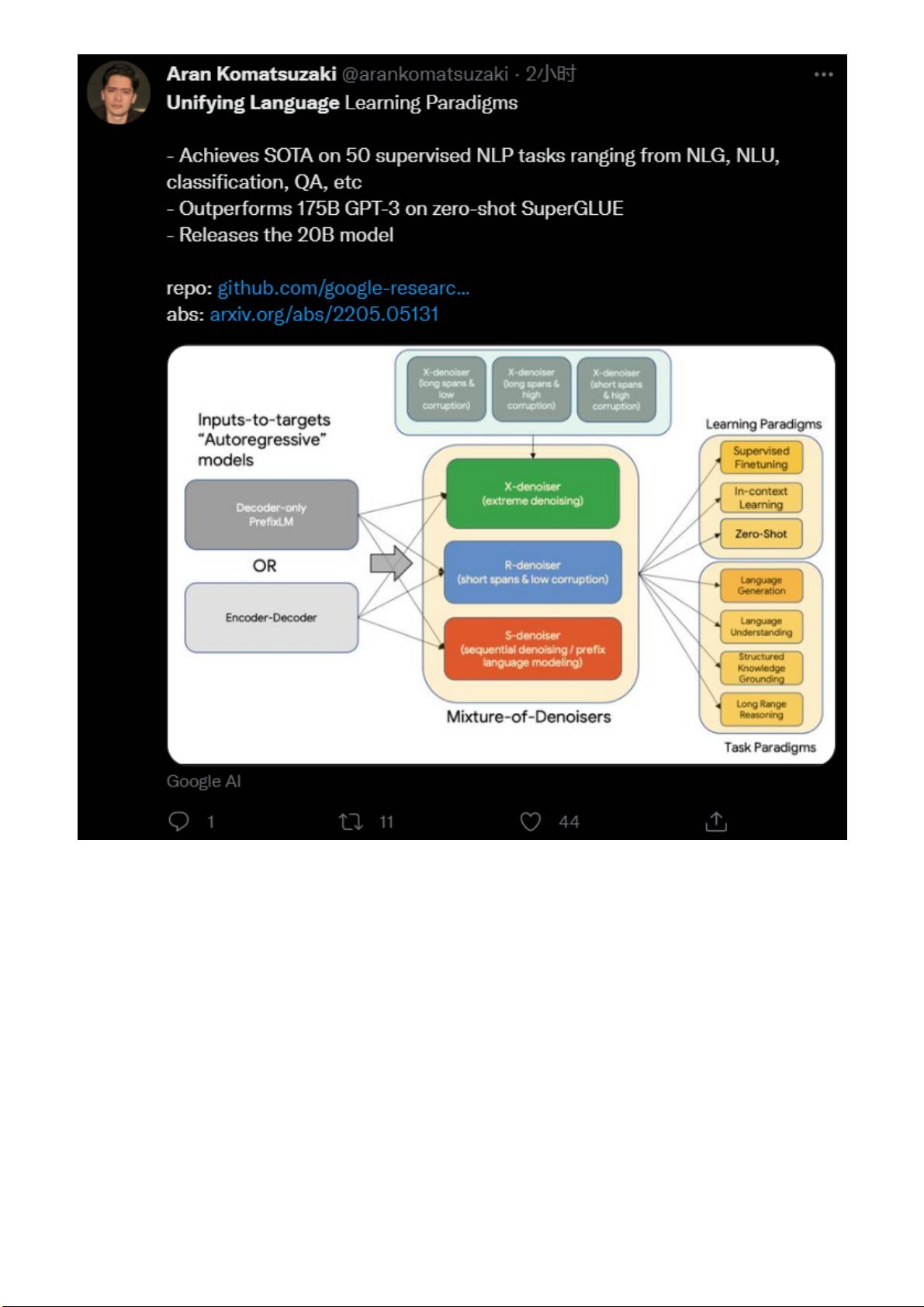
Go ogle 的 Yi Tay (and Mostafa) 团队提 出了 一个 新的 策略 Mixture-of-Denoisers, 统一 了
各大预 训 练 范 式 。
重新思考现在的预训练精调,我们有各种各样的预训练范式: decoder-only or encoder-d
ecoder , span corruption or language model , 等等, 不同的范式建模了不同的上下文
关系,也正是因为如此,不 同 的 预 训 练 范 式 适 配 不 同 类 型 的 下 游 任 务 。例如,基于双向上下
文 的 预 训 练 (span corruption , 如 T5) 更 加 适 用 于 fact completion , 基 于 单 向 上 文
(P refixLM/LM,如GPT等)更加适用于 open ended. 也就是说,具 体 的 下 游 任 务 类 型 需 要 选
用 特 定 的 预 训 练 策 略 ...
准确地说,常见有三套范式:单向文本建模的CausalLM(i.e. LM),双向文本建模的 span
corruption, 前缀文本建模的 PrefixLM.
这是大一统吗?感觉只能是小一统,总感觉还缺少一味菜!
今天,Google 把这道菜补上了!那就是:Mixture-of-Denoisers
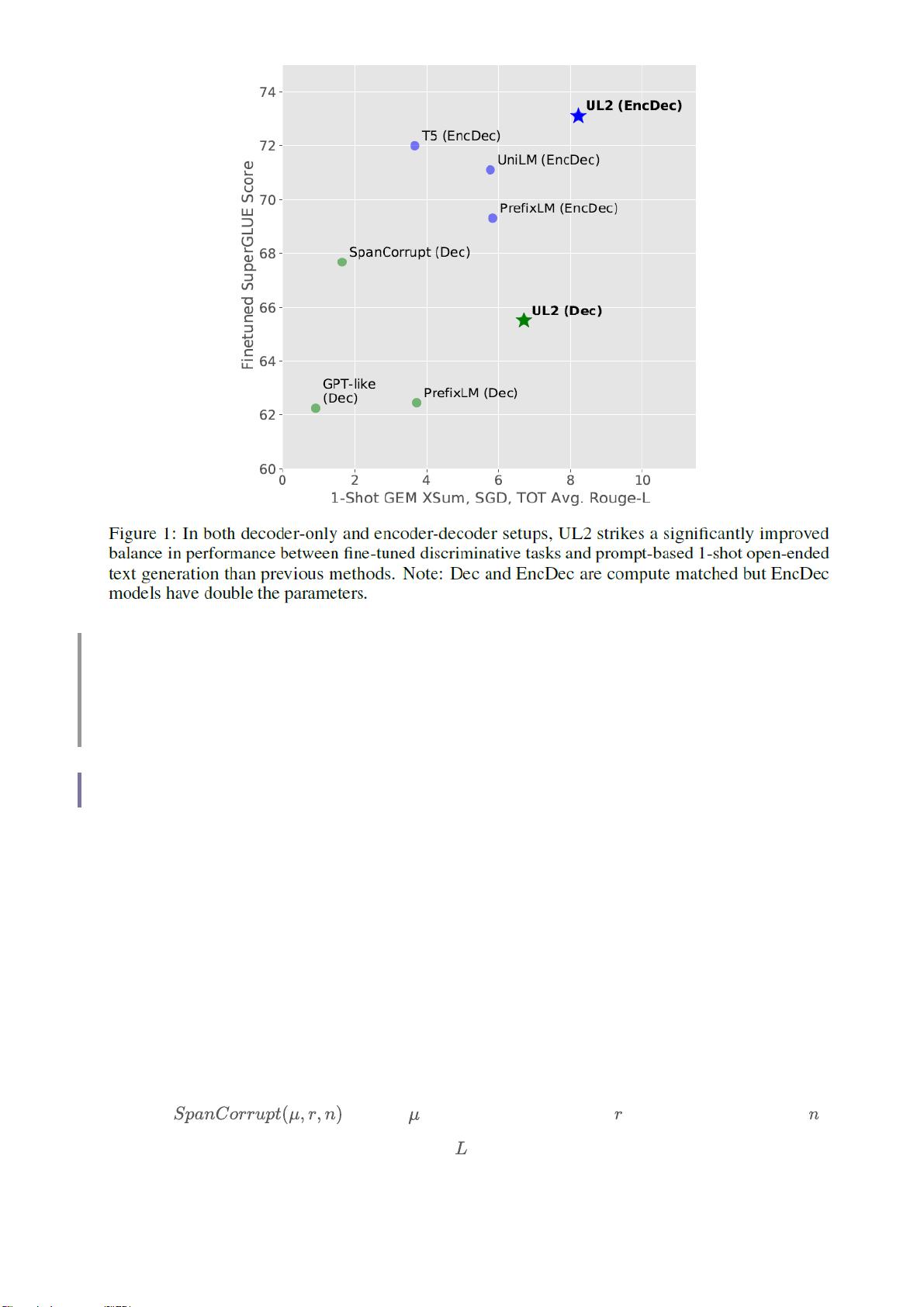
先来感受一下效果:
2023/6/28 22:31
击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式
https://mp.weixin.qq.com/s/oMUASBSKe3xgGVLuQz7MGg
4/14
论 文 标 题 : Unifying Language Learning Paradigms
论 文 作 者 : Yi Tay, Mostafa Dehghani, etc. (Google)
论 文 链 接 : https://arxiv.org/pdf/2205.05131.pdf
方法(UL2)
先说一下本文方法的目的:构建一种独 立 于 模 型 架 构 以 及 下 游 任 务 类 型 的预训练策略,可以
灵活地适配不同类型的下游任务。
整个方法的框架和 UniLM[1] 是很相似的,但是引入了稀疏化。
Mixture-of-Denoisers
首先回顾上文所说的三个预训练范式:CausalLM, Pref ixLM, span corruption,其实都可以统
一 到 spancorruption :
定 义 函 数 , 这 里 为 平 均 span 长 度 , 为 corruption rate, 为
corrupted span 的数量 .定 义输入序列 长度为 ,经过正 态分布或者 均匀分布采 样 corrputed
span 后,训练模型学习恢复这些 span.

2023/6/28 22:31
击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式
https://mp.weixin.qq.com/s/oMUASBSKe3xgGVLuQz7MGg
5/14
可 见 , 对 于 CausalLM , 只 需 要 设 置 ; 对 于 P refixLM, 只 需 要 设 置
( 为前缀长度)。
基于此,作者提出了 Mixture-of-Denoisers :
R-Denoiser : regular denoising. corrupted span 的长度为 2-5 个 tokens, 大约是 15% 的
掩码率。通常用于获得知识而不是生成流畅文本的能力。
S-D enoiser : sequential denoising. 保留严格的序列顺序,通常用于 inputs-to-targets 任
务,如 PrefixLM. 需要注意的是,可见的 Prefix 仍然是上下文建模方式,但是被掩码掉的
长 span 是不可见的。
X-Denoiser : extreme denoising. 可以看作 R-denoiser 和 S-denoiser 的中间体,是一种
极端的情况,也就是 span length 非常长,或者 masking rate 非常大。一般用于长文本生
成任务,因为这类任务一般只有非常有限的上下文记忆信息。
最后,本文使用的七 个 denoiser 设定如下:
Mode Switching
本 文 提 出 通 过 mode-switching 来进行 paradigm-shifting. 首 先 在 预 训 练 的 时 候 , 新 增 三 个
special tokens : ,分别指代三个 paradigms (i.e... denoiser). 然后在下游任务精调
或者小样本学习时,也为特定任务的设定和需要,新增一个 paradigm token, 以触发模型学习
更优的方案。













