2023/6/28 17:15
双塔模型的最强出装,谷歌又开始玩起“老古董”了?
https://mp.weixin.qq.com/s/MF3NVyLBh0xIVCEMltzBgw
1/5
双塔模型的最强出装,谷歌又开始玩起“老古董”了?
文 | 兔 子 酱
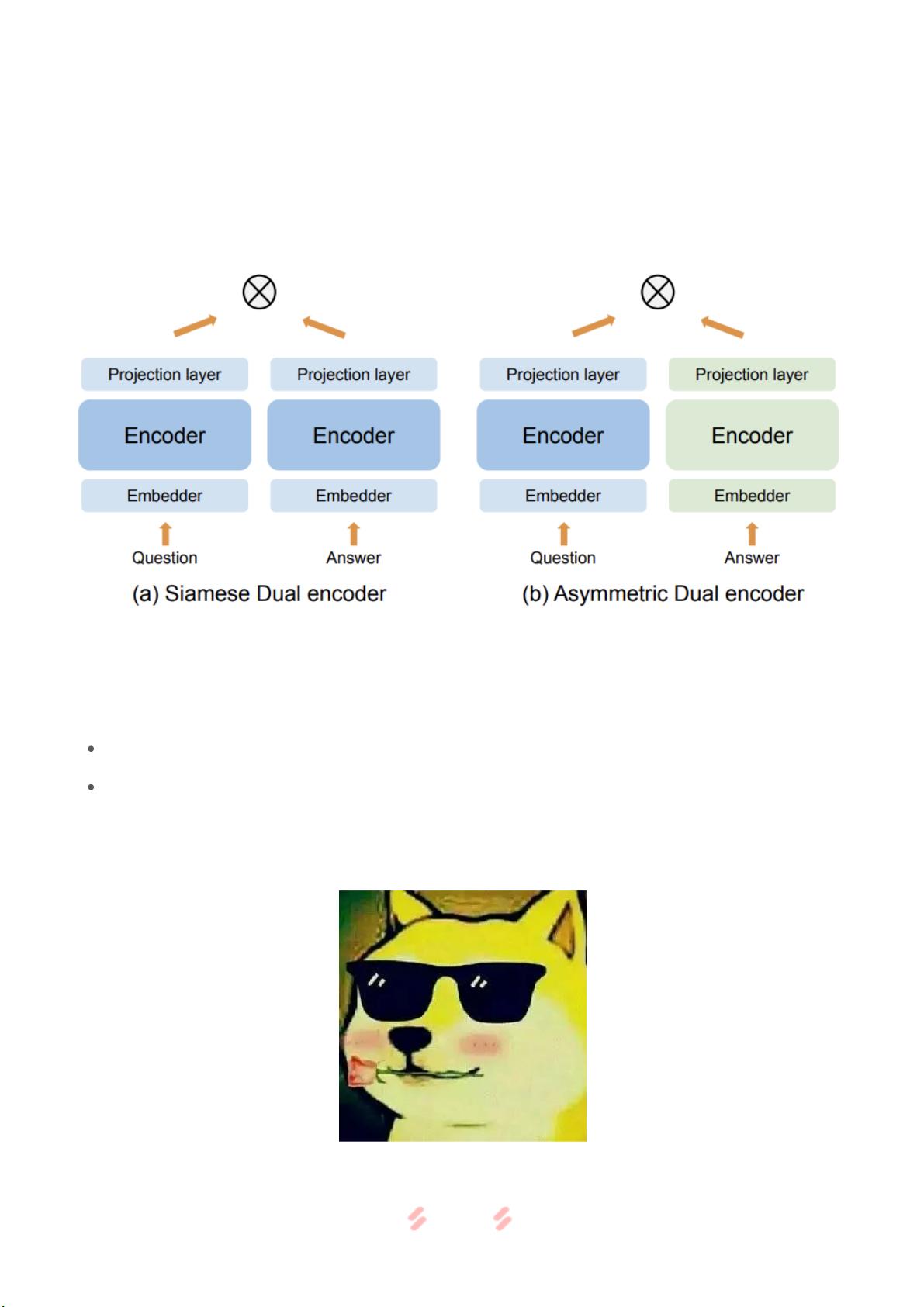
双塔模型已经证明在搜索和问答任务中是非常有效的建模方法,理论和业务落地已相当成熟。
双 塔根 据 参 数共 享 程 度不 同 , 通常 会 归 纳成 两 类 :Simese dual encoder 和 Asymmetric dual
encoder,前者参数结构完全对称,后者则是不完全对称(下文简称SDE和ADE)。
本篇论文是继双塔沉寂许久之后,谷歌再次将它推到宇宙中心,并打开双塔的最强出装,详细
地探索两者的区别和关联,也通过实验给出了双塔结构的更多经验性结论。适合老司机再次回
味经典和小白做深刻且系统地入门~
论 文 题 目 :
Exploring Dual Encoder Architectures for Question Answering
论 文 链 接 :
https://arxiv.org/abs/2204.07120
背景
兔子酱 2022-07-07 12:05 发表于四川
原创
夕小瑶科技说