种⽅法都在ALBERT中应⽤了,对速度基本没有提升,主要是减少了内存占⽤。但通过ALBRET⽅式预训练出来的
Transformer理论上⽐BERT中的层更通⽤,可以直接拿来初始化浅层transformer模型,相当于提升了速度。
3. 剪枝:通过去掉模型的⼀部分减少运算。最细粒度为权重剪枝,即将某个连接权重置为0,得到稀疏矩阵;其次为神经元剪
枝,去掉矩阵中的⼀个vector;模型层⾯则为结构性剪枝,可以是去掉attention、FFN或整个层,典型的⼯作是
LayerDrop
[1]
。这两种⽅法都是同时对速度和内存进⾏优化。
4. 蒸馏:训练时让⼩模型学习⼤模型的泛化能⼒,预测时只是⽤⼩模型。⽐较有名的⼯作是DistillBERT
[2]
和TinyBERT
[3]
。
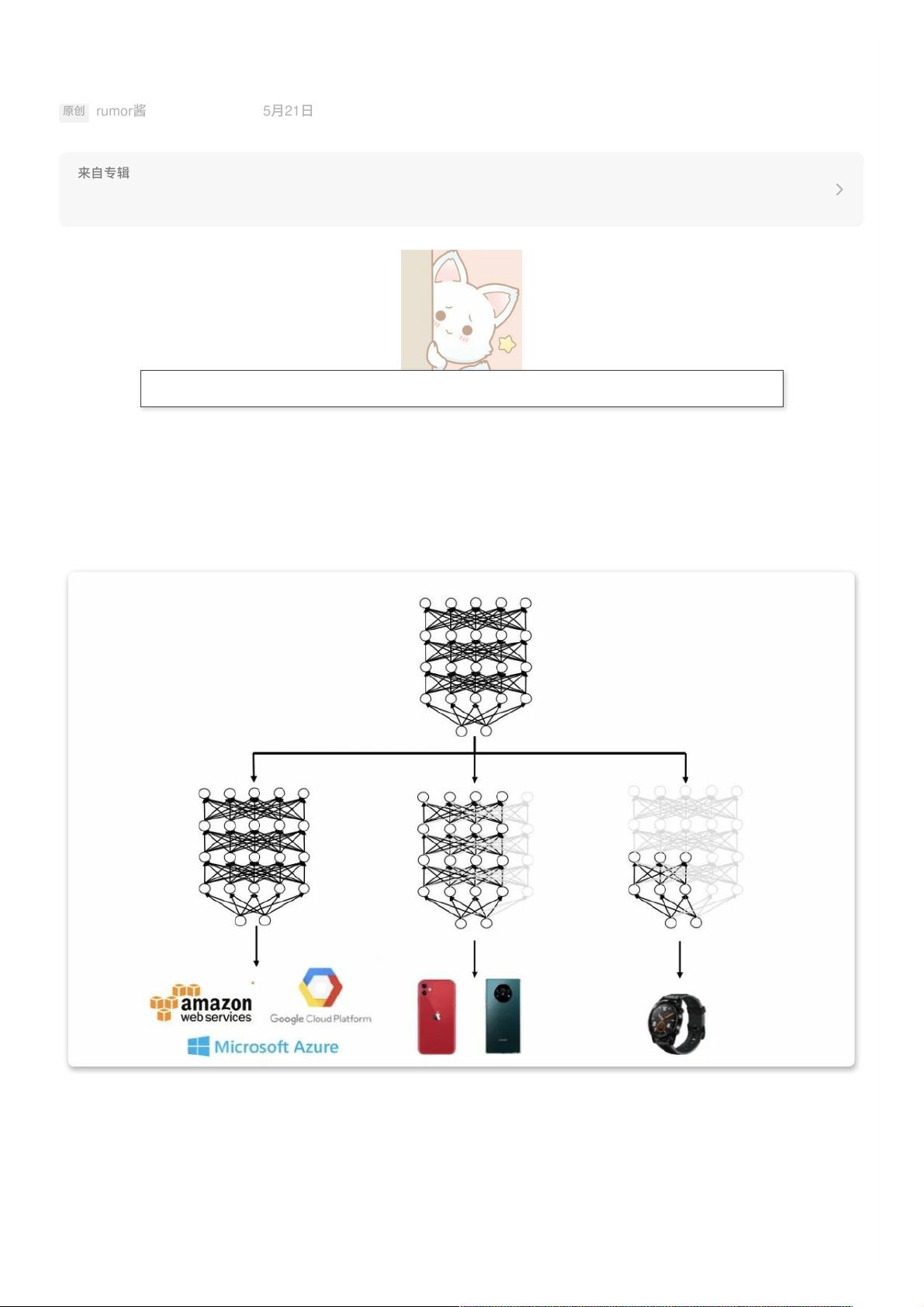
实际⼯作中,减少BERT层数+蒸馏是⼀种常⻅且有效的提速做法。但由于不同任务对速度的要求不⼀样,可能任务A可以⽤6层
的BERT,任务B就只能⽤3层的,因此每次都要花费不少时间对⼩模型进⾏调参蒸馏。
有没有办法⼀次获得多个尺⼨的⼩模型呢?
今天rumor就给⼤家介绍⼀篇论⽂《DynaBERT: Dynamic BERT with Adaptive Width and Depth》
[4]
。论⽂中作者提出了新
的训练算法,同时对不同尺⼨的⼦⽹络进⾏训练,通过该⽅法训练后可以在推理阶段直接对模型裁剪。依靠新的训练算法,本⽂
在效果上超越了众多压缩模型,⽐如DistillBERT、TinyBERT以及LayerDrop后的模型。
Arxiv访问慢的⼩伙伴也可以在订阅号后台回复关键词【0521】下载论⽂PDF。
原理
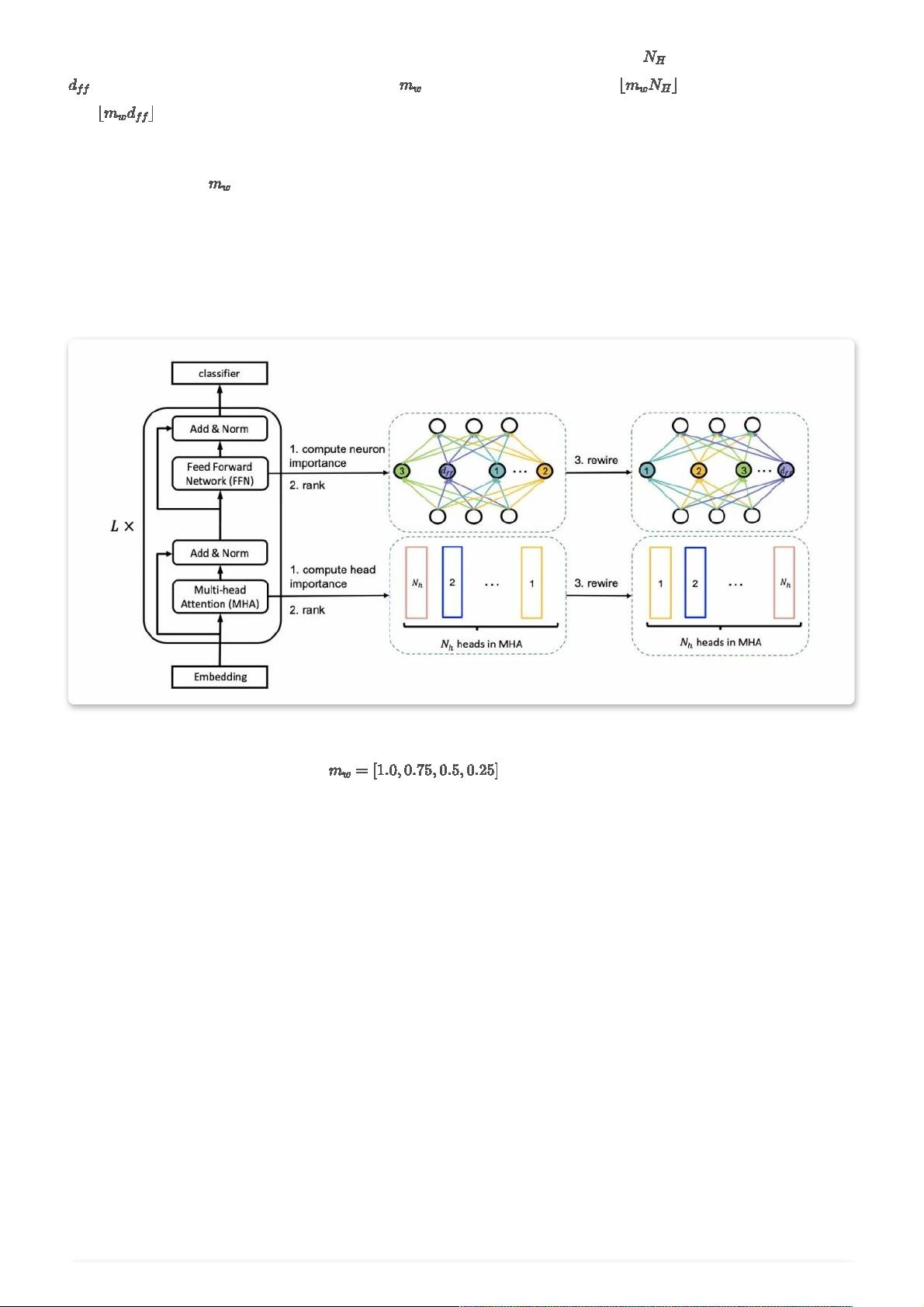
论⽂对于BERT的压缩流程是这样的:
训练时,对宽度和深度进⾏裁剪,训练不同的⼦⽹络
推理时,根据速度需要直接裁剪,⽤裁剪后的⼦⽹络进⾏预测
想法其实很简单,但如何能保证更好的效果呢?这就要看炼丹功⼒了 (..•˘_˘•..),请听我下⾯道来〜
整体的训练分为两个阶段,先进⾏宽度⾃适应训练,再进⾏宽度+深度⾃适应训练。
宽度⾃适应 Adaptive Width
宽度⾃适应的训练流程是:
1. 得到适合裁剪的teacher模型,并⽤它初始化student模型
2. 裁剪得到不同尺⼨的⼦⽹络作为student模型,对teacher进⾏蒸馏
最重要的就是如何得到适合裁剪的teacher。先说⼀下宽度的定义和剪枝⽅法。Transformer中主要有Multi-head Self-