

基于 Hadoop数据分析系统
设计毕业论文
目录
第一章 某某企业数据分析系统设计需求分析 ........................... 1
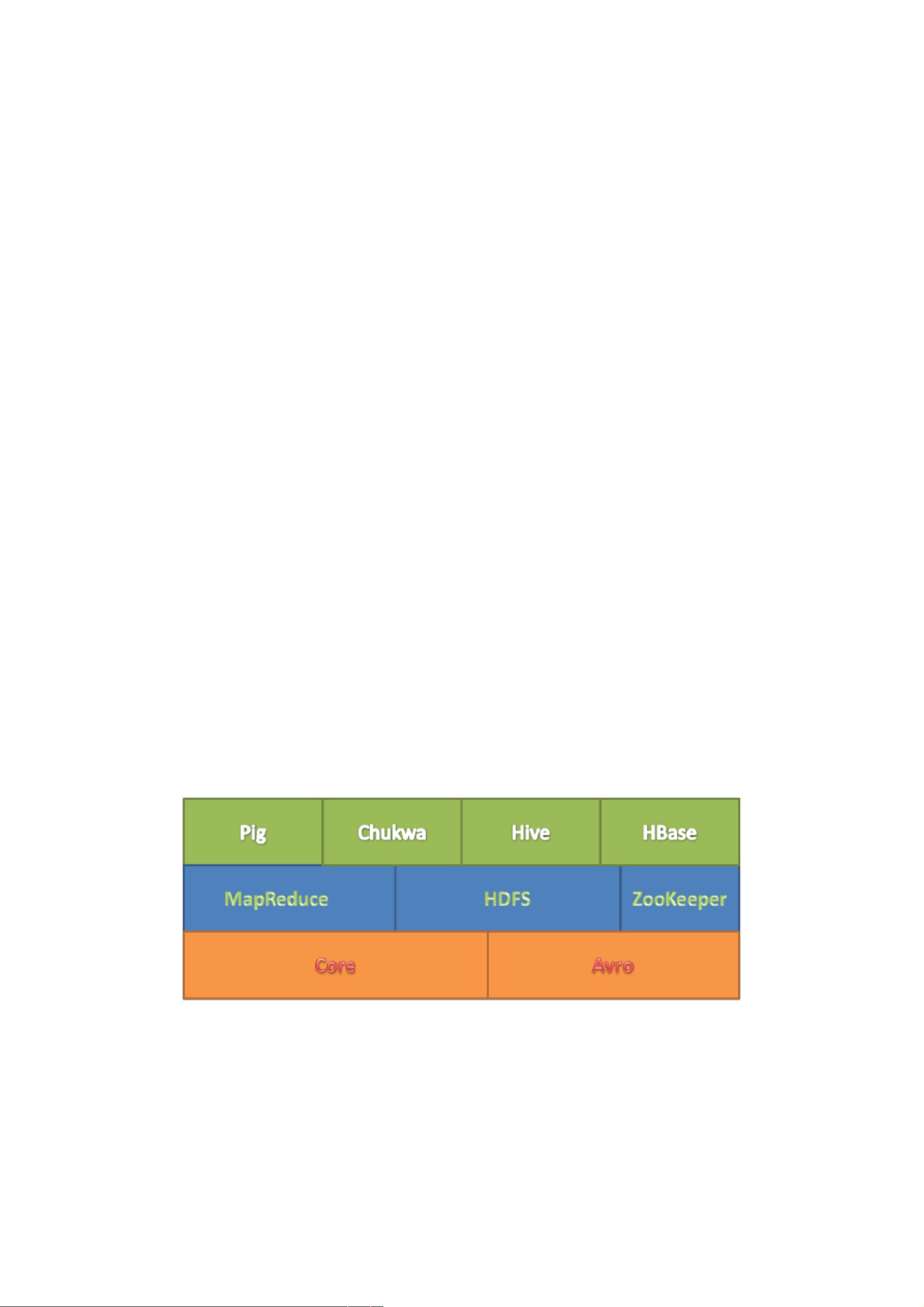
第二章 HADOOP简介 ................................................ 2
第三章 HADOOP单一部署 ............................................ 5
3.1 H
ADOOP
集群部署拓扑图 ......................................... 5
3.2 安装操作系统 C
ENTOS
........................................... 6
3.3 H
ADOOP
基础配置 .............................................. 12
3.4 SSH免密码登录 .............................................. 16
3.5 安装 JDK .................................................... 17
3.6 安装 H
ADOOP
.................................................. 17
3.6.1安装 32 位 Hadoop .......................................... 18
3.6.2安装 64 位 Hadoop .......................................... 27
3.7 H
ADOOP
优化 .................................................. 31
3.8 H
IVE
安装与配置 .............................................. 32
3.8.1 Hive 安装................................................. 32
3.8.2 使用MySQL存储Metastore.................................. 32
3.8.3 Hive 的使用............................................... 35
3.9 H
BASE
安装与配置 ............................................. 36
9.1 Hbase 安装.................................................. 36
9.2 Hbase 的使用................................................ 38
3.10 集群监控工具 G
ANGLIA
......................................... 41
第四章 HADOOP批量部署 ........................................... 47
4.1
安装操作系统批量部署工具 C
OBBLER
............................... 47



剩余68页未读,继续阅读
资源评论













