
仰恩大学毕业设计(论文)
III
目 录
摘 要............................................................ I
Abstract........................................................... I I
引 言............................................................ 1
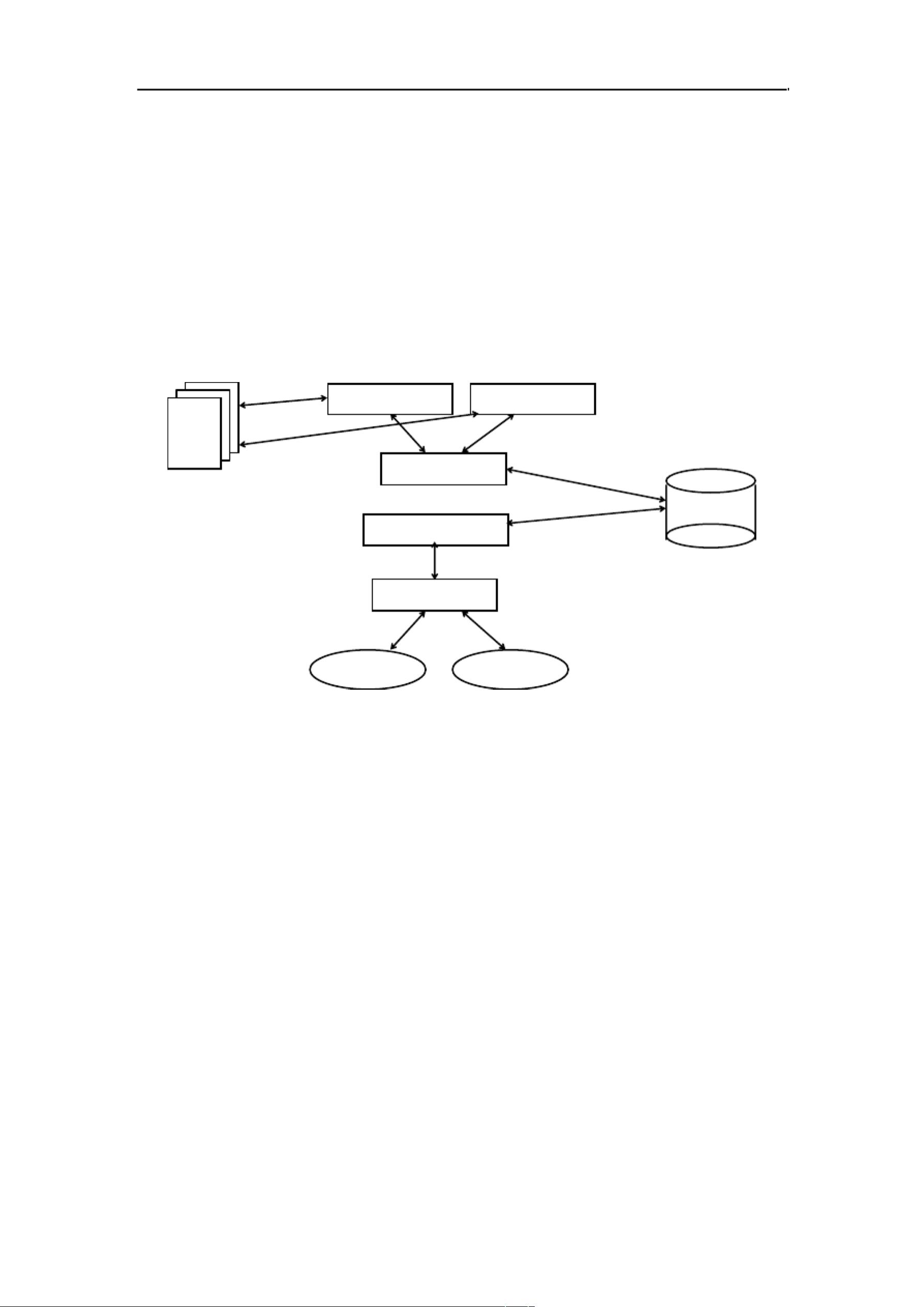
1 搜索引擎的结构.................................................... 2
1.1搜索引擎系统概述........................................................................................... 2
1.2搜索引擎的构成............................................................................................... 2
1.2.1网络蜘蛛................................................................................................. 2
1.2.2索引与搜索............................................................................................. 2
1.2.3 Web 服务器 ............................................................................................ 3
1.3搜索引擎的主要指标及分析........................................................................... 3
2 网络机器人........................................................ 4
2.1什么是网络机器人........................................................................................... 4
2.2网络机器人的结构分析................................................................................... 4
2.2.2 Spider 程序结构 ..................................................................................... 4
2.2.3如何构造 Spider 程序 ............................................................................ 5
2.2.4如何提高程序性能................................................................................. 7
2.2.5网络机器人的代码分析......................................................................... 7
3 基于 lucene 的索引与搜索、tomcat 服务器........................... 10
3.1什么是 L
UCENE
全文检索 .............................................................................. 10
3.2
L
UCENE
的原理分析 ....................................................................................... 10
3.2.1客户端设计........................................................................................... 10
3.2.2全文检索的实现机制........................................................................... 11
3.2.3 Lucene 的索引效率 .............................................................................. 11
3.2.4 中文切分词机制.................................................................................. 13
3.2.5服务端设计........................................................................................... 14
3.3
L
UCENE
与 S
PIDER
的结合 .............................................................................. 15
3.3.1如何解析 HTML .................................................................................. 16
3.4
基于 T
OMCAT
的 W
EB
服务器 ....................................................................... 19
3.5在 T
OMCAT
上部署项目 ................................................................................. 19
4 搜索引擎策略..................................................... 21
4.1简介................................................................................................................. 21
4.2面向主题的搜索策略..................................................................................... 21
4.2.1导向词................................................................................................... 21
4.2.2网页评级............................................................................................... 21
4.2.3权威网页和中心网页........................................................................... 22
结 论........................................................... 23
参考文献........................................................... 24
致 谢........................................................... 25





 2301_816709782024-01-22实在是宝藏资源、宝藏分享者!感谢大佬~
2301_816709782024-01-22实在是宝藏资源、宝藏分享者!感谢大佬~














