



WORD 格式整理
专业资料 值得拥有
高级数据挖掘期末大作业

WORD 格式整理
专业资料 值得拥有
基于协同过滤算法的电影推荐系统
本电影推荐系统中运用的推荐算法是基于协同过滤算法(Collaborative
Filtering Recommendation)。协同过滤是在信息过滤和信息系统中正迅速成为一
项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过
滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似
用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
电影推荐系统中引用了 Apache Mahout 提供的一个协同过滤算法的推荐引擎
Taste,它实现了最基本的基于用户和基于内容的推荐算法,并提供了扩展接口,
使用户方便的定义和实现自己的推荐算法。
电影推荐系统是基于用户的推荐系统,即当用户对某些电影评分之后,系统
根据用户对电影评分的分值,判断用户的兴趣,先运用 UserSimilarity 计算用户
间的相似度.UserNeighborhood 根据用户相似度找到与该用户口味相似的邻居,
最后由 Recommender 提供推荐个该用户可能感兴趣的电影详细信息。将用户评
过分的电影信息和推荐给该用户的电影信息显示在网页结果页中,推荐完成。
一、Taste 介绍
Taste 是 Apache Mahout 提供的一个个性化推荐引擎的高效实现,该引擎基
于 java 实现,可扩展性强,同时在 mahout 中对一些推荐算法进行了 MapReduce
编程模式转化,从而可以利用 hadoop 的分布式架构,提高推荐算法的性能。
在 Mahout0.5 版本中的 Taste, 实现了多种推荐算法,其中有最基本的基于
用户的和基于内容的推荐算法,也有比较高效的 SlopeOne 算法,以及处于研究
阶段的基于 SVD 和线性插值的算法,同时 Taste 还提供了扩展接口,用于定制化
开发基于内容或基于模型的个性化推荐算法。
Taste 不仅仅适用于 Java 应用程序,还可以作为内部服务器的一个组件以
HTTP 和 Web Service 的形式向外界提供推荐的逻辑。Taste 的设计使它能满足
企业对推荐引擎在性能、灵活性和可扩展性等方面的要求。
下图展示了构成 Taste 的核心组件:
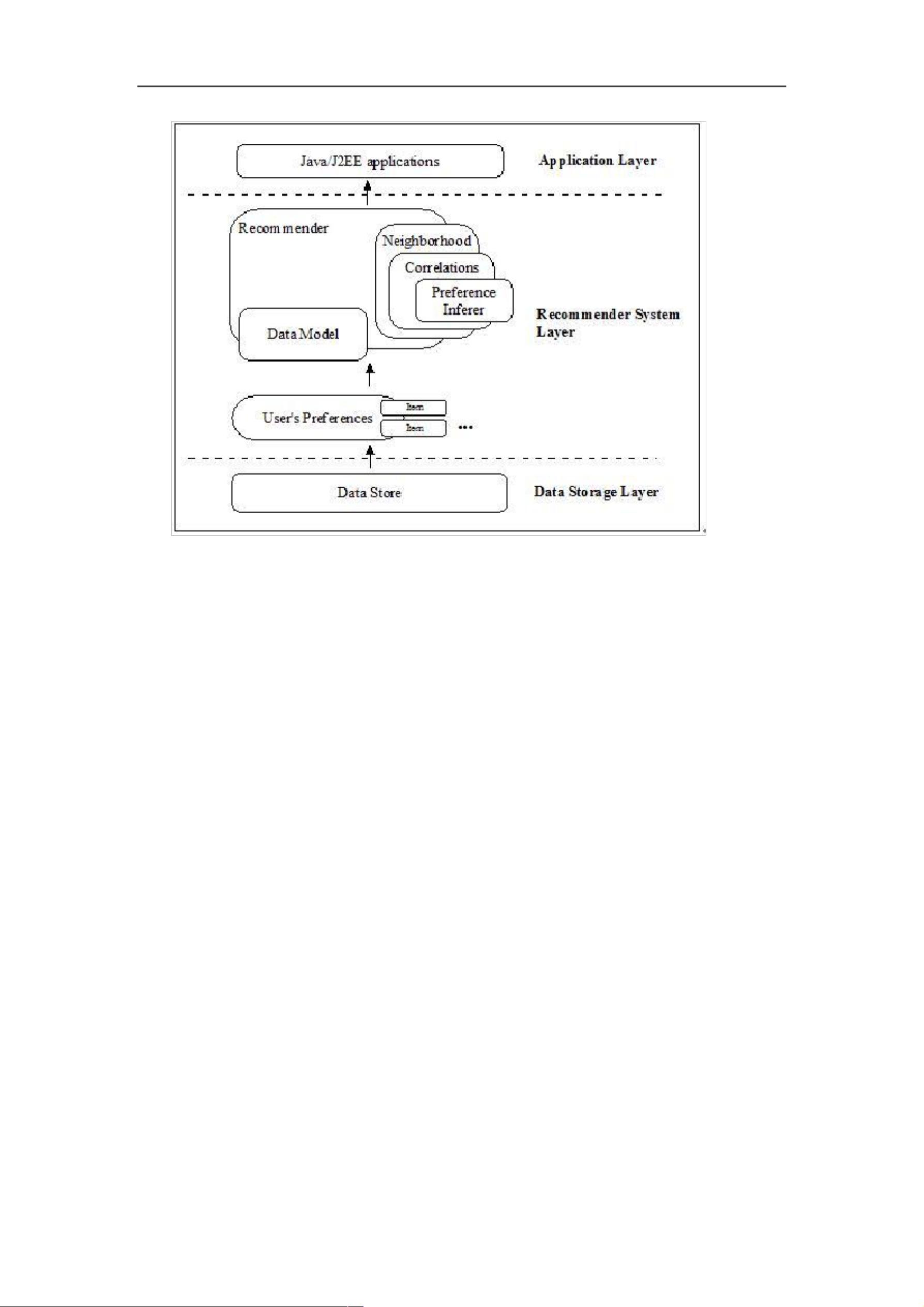
WORD 格式整理
专业资料 值得拥有
从上图可见,Taste 由以下几个主要组件组成:
DataModel:DataModel 是用户喜好信息的抽象接口,它的具体实现支持从指
定 类 型 的 数 据 源 抽 取 用 户 喜 好 信 息 。 在 Mahout0.5 中 , Taste 提 供
JDBCDataModel 和 FileDataModel 两种类的实现,分别支持从数据库和文件文
件系统中读取用户的喜好信息。对于数据库的读取支持,在 Mahout 0.5 中只提
供了对 MySQL 和 PostgreSQL 的支持,如果数据存储在其他数据库,或者是把
数据导入到这两个数据库中,或者是自行编程实现相应的类。
UserSimilarit 和 ItemSimilarity:前者用于定义两个用户间的相似度,后者用
于定义两个项目之间的相似度。Mahout 支持大部分驻留的相似度或相关度计算
方法,针对不同的数据源,需要合理选择相似度计算方法。
UserNeighborhood:在基于用户的推荐方法中,推荐的内容是基于找到与当
前用户喜好相似的“邻居用户”的方式产生的,该组件就是用来定义与目标用户
相邻的“邻居用户”。所以,该组件只有在基于用户的推荐算法中才会被使用。
Recommender:Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。
利用该组件就可以为指定用户生成项目推荐列表。

WORD 格式整理
专业资料 值得拥有
二、相似性度量
本章节将系统中用到的几个相似性度量函数作以介绍,taste 中已经具体实现
了各相似性度量类。User CF 和 Item CF 都依赖于相似度的计算,因为只有通
过衡量用户之间或物品之间的相似度,才能找到用户的“邻居”,才能完成推荐。
下面就对常用的相似度计算方法进行详细的介绍:
1. 基于皮尔森相关性的相似度 —— Pearson correlation-based similarity
皮尔森相关系数反应了两个变量之间的线性相关程度,它的取值在[-1, 1]之
间。当两个变量的线性关系增强时,相关系数趋于 1 或-1;当一个变量增大,另
一个变量也增大时,表明它们之间是正相关的,相关系数大于 0;如果一个变量
增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于 0;如果相
关系数等于 0,表明它们之间不存在线性相关关系。
用数学公式表示,皮尔森相关系数等于两个变量的协方差除于两个变量的标
准差。
Pearson correlation-based similarity
协方差(Covariance):在概率论和统计学中用于衡量两个变量的总体误差。
如果两个变量的变化趋于一致,也就是说如果其中一个大于自身的期望值,另一
个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的
变化趋势相反,则协方差为负值。
Covariance
其中 u 表示 X 的期望 E(X), v 表示 Y 的期望 E(Y)

WORD 格式整理
专业资料 值得拥有
标准差(Standard Deviation):标准差是方差的平方根
Standard Deviation
方差(Variance):在概率论和统计学中,一个随机变量的方差表述的是它的离
散程度,也就是该变量与期望值的距离。
Variance
即方差等于误差的平方和的期望
基于皮尔森相关系数的相似度有两个缺点:
(1) 没有考虑(take into account)用户间重叠的评分项数量对相似度的影响;
(2) 如果两个用户之间只有一个共同的评分项,相似度也不能被计算
Table1
上表中,行表示用户(1~5)对项目(101~103)的一些评分值。直观来看,
User1 和 User5 用 3 个共同的评分项,并且给出的评分走差也不大,按理他们之
间的相似度应该比 User1 和 User4 之间的相似度要高,可是 User1 和 User4 有一
个更高的相似度 1。
同样的场景在现实生活中也经常发生,比如两个用户共同观看了 200 部电影,
虽然不一定给出相同或完全相近的评分,他们之间的相似度也应该比另一位只观
看了 2 部相同电影的相似度高吧!但事实并不如此,如果对这两部电影,两个用













