Bigtable-sql 基本使用
运行环境说明
在 32 位的 windows 运行不起来!
需要 windows 64 位机器!才可以运行起来!无需安装 jdk,因为本软件只能在 jdk1.8 运
行!所以强制安装了一个 jdk1.8!
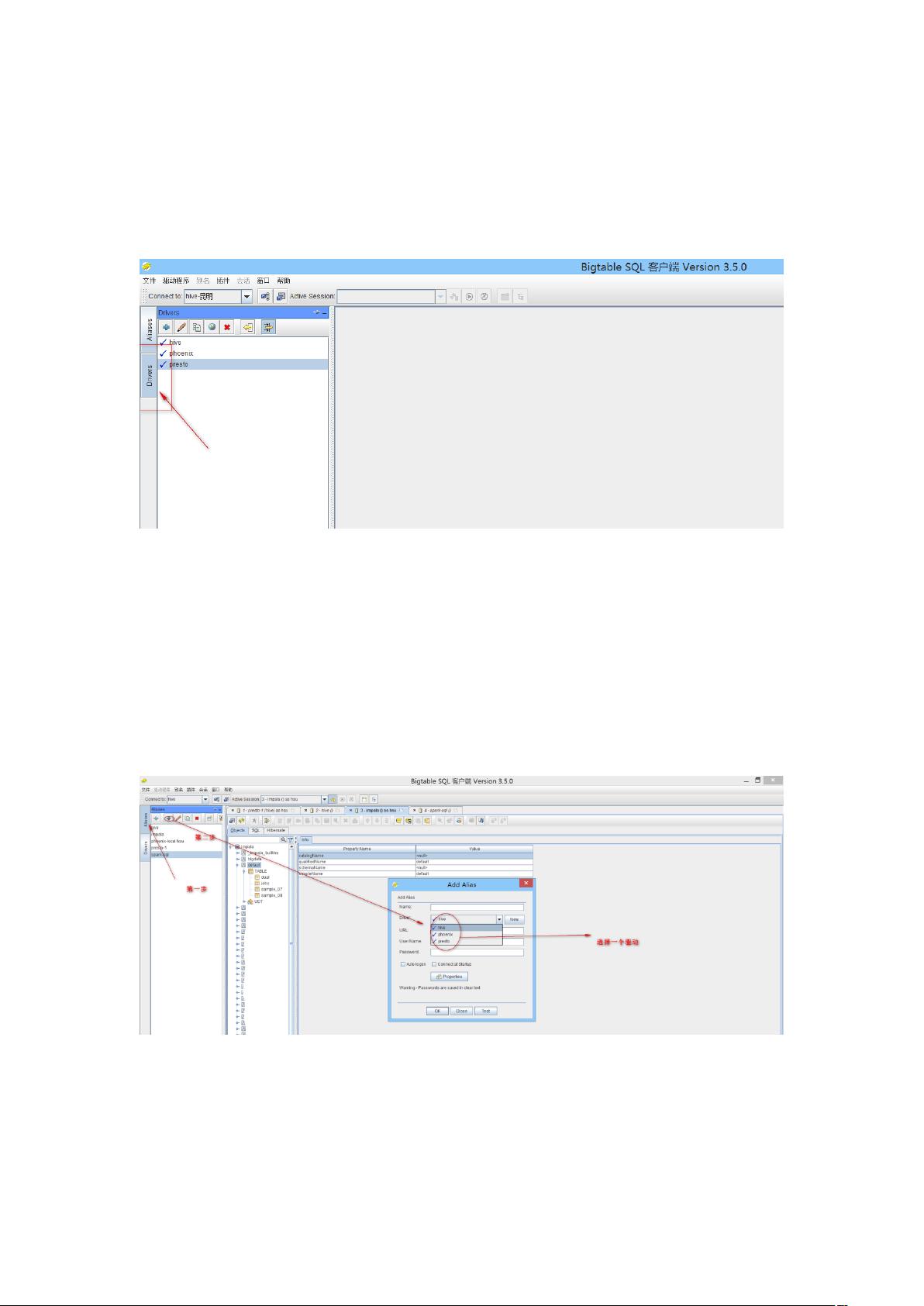
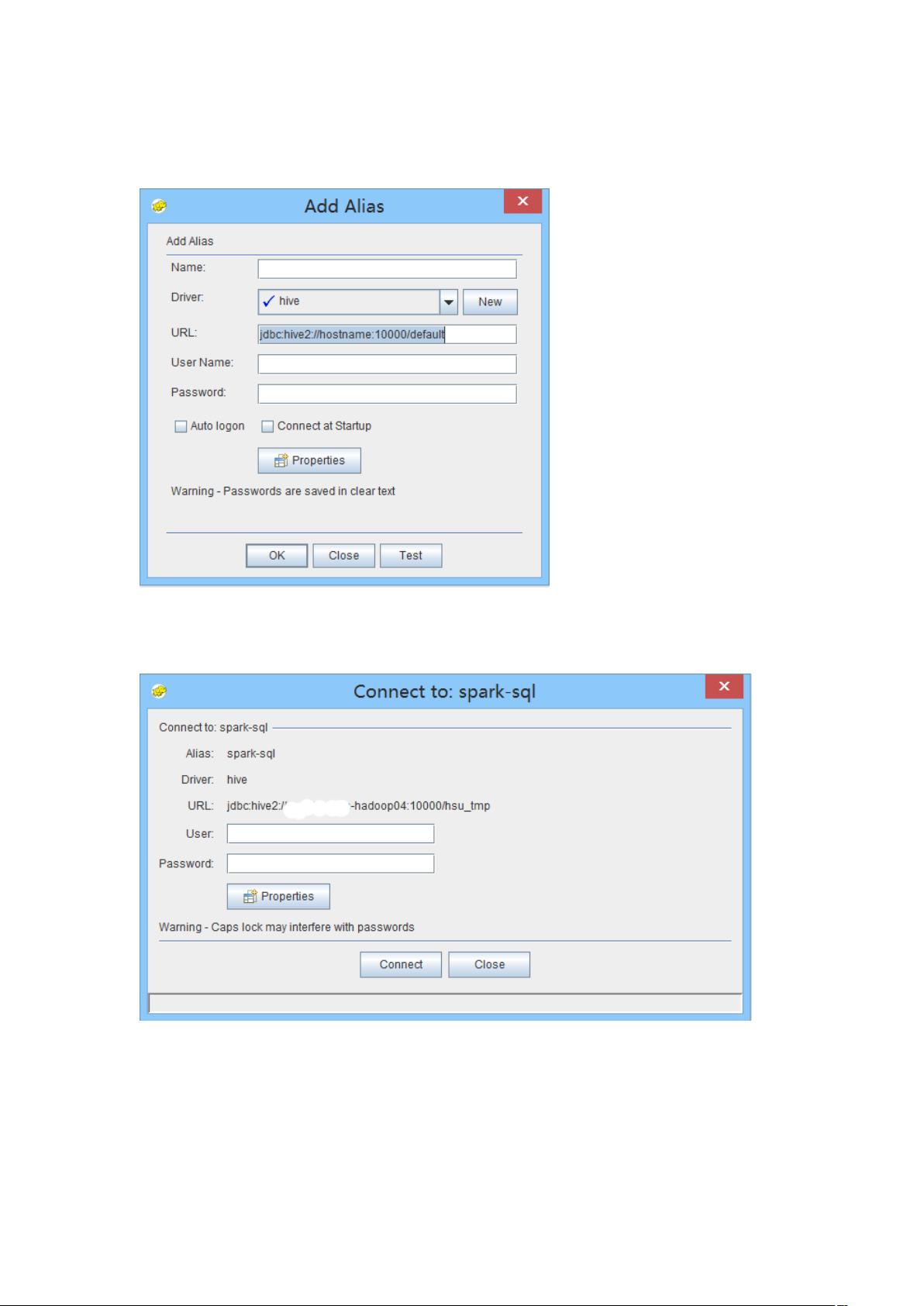
1、解压包
2、运行
 大数据-分布式大数据SQL查询可视化界面设计.zip (1001个子文件)
大数据-分布式大数据SQL查询可视化界面设计.zip (1001个子文件)  bigtable-sql基本使用.docx 1003KB
bigtable-sql基本使用.docx 1003KB Hourglass.gif 987B open16.gif 913B maximizewindows16.gif 902B Exclamation.gif 900B run_exc.gif 900B createresultwindow.gif 891B smallcreatewindow.gif 887B close.gif 883B ok.gif 865B restore.gif 855B maximize.gif 852B copy_to_paste.gif 678B loading_gif.gif 673B About16.gif 644B print_edit.gif 612B new.gif 612B print_edit.gif 612B print_edit.gif 612B paste_edit.gif 605B aliasProperties.gif 604B undo16.gif 597B file_detach_cross.gif 589B history_list.gif 586B greenflag16.gif 583B logs.gif 582B appendfile.gif 582B filter.gif 579B sync.gif 555B Edit16.gif 441B properties16.gif 425B file_detach.gif 363B discovery.gif 362B discovery.gif 362B discovery.gif 362B folder_new.gif 360B print_edit.gif 355B file_obj.gif 354B newfile_wiz.gif 353B newfile_wiz.gif 353B newfile_wiz.gif 353B next_nav.gif 332B find.gif 326B autohideOff.gif 325B prev_nav.gif 323B autohideOn.gif 312B smallFileChanged.gif 288B Copy16.gif 288B smallFile.gif 284B folder_delete.gif 261B refresh16.gif 244B dir_obj.gif 240B Add16.gif 238B home_nav.gif 221B newfile_wiz.gif 219B select.gif 218B open.gif 216B cut_edit.gif 212B Delete16.gif 208B preferences16.gif 207B save.gif 187B plugins.gif 186B prefs_misc.gif 182B prefs_misc.gif 181B saveas.gif 173B properties.gif 171B properties.gif 171B copycont_l_co.gif 170B view.gif 169B toc_open.gif 167B showerr_tsk.gif 167B copy_edit.gif 167B expandall.gif 165B plugin_obj.gif 165B remove.gif 163B go_nav.gif 162B home_nav.gif 160B copy_edit.gif 160B error_st_obj.gif 159B filter_history.gif 159B toc_closed.gif 158B sort.gif 157B collapseall.gif 157B resource_obj.gif 153B resource_obj.gif 153B topic.gif 152B last_edit_pos.gif 150B edittsk_tsk.gif 149B undo_edit.gif 147B last_edit_pos.gif 146B redo_edit.gif 146B delete_edit.gif 143B release_rls.gif 142B release_rls.gif 142B tilevertical16.gif 138B forward_nav.gif 138B exit16.gif 137B cascadewindows16.gif 134B refresh.gif 134B trash.gif 133B
Hourglass.gif 987B open16.gif 913B maximizewindows16.gif 902B Exclamation.gif 900B run_exc.gif 900B createresultwindow.gif 891B smallcreatewindow.gif 887B close.gif 883B ok.gif 865B restore.gif 855B maximize.gif 852B copy_to_paste.gif 678B loading_gif.gif 673B About16.gif 644B print_edit.gif 612B new.gif 612B print_edit.gif 612B print_edit.gif 612B paste_edit.gif 605B aliasProperties.gif 604B undo16.gif 597B file_detach_cross.gif 589B history_list.gif 586B greenflag16.gif 583B logs.gif 582B appendfile.gif 582B filter.gif 579B sync.gif 555B Edit16.gif 441B properties16.gif 425B file_detach.gif 363B discovery.gif 362B discovery.gif 362B discovery.gif 362B folder_new.gif 360B print_edit.gif 355B file_obj.gif 354B newfile_wiz.gif 353B newfile_wiz.gif 353B newfile_wiz.gif 353B next_nav.gif 332B find.gif 326B autohideOff.gif 325B prev_nav.gif 323B autohideOn.gif 312B smallFileChanged.gif 288B Copy16.gif 288B smallFile.gif 284B folder_delete.gif 261B refresh16.gif 244B dir_obj.gif 240B Add16.gif 238B home_nav.gif 221B newfile_wiz.gif 219B select.gif 218B open.gif 216B cut_edit.gif 212B Delete16.gif 208B preferences16.gif 207B save.gif 187B plugins.gif 186B prefs_misc.gif 182B prefs_misc.gif 181B saveas.gif 173B properties.gif 171B properties.gif 171B copycont_l_co.gif 170B view.gif 169B toc_open.gif 167B showerr_tsk.gif 167B copy_edit.gif 167B expandall.gif 165B plugin_obj.gif 165B remove.gif 163B go_nav.gif 162B home_nav.gif 160B copy_edit.gif 160B error_st_obj.gif 159B filter_history.gif 159B toc_closed.gif 158B sort.gif 157B collapseall.gif 157B resource_obj.gif 153B resource_obj.gif 153B topic.gif 152B last_edit_pos.gif 150B edittsk_tsk.gif 149B undo_edit.gif 147B last_edit_pos.gif 146B redo_edit.gif 146B delete_edit.gif 143B release_rls.gif 142B release_rls.gif 142B tilevertical16.gif 138B forward_nav.gif 138B exit16.gif 137B cascadewindows16.gif 134B refresh.gif 134B trash.gif 133B