
什么是正则表达式?
正则表达式是⼀组由字⺟和符号组成的特殊⽂本,它可以⽤来从⽂本中找出满⾜你想要的格式的句
⼦。
⼀个正则表达式是⼀种从左到右匹配主体字符串的模式。
“Regular expression”这个词⽐较拗⼝,我们常使⽤缩写的术语“regex”或“regexp”。
正则表达式可以从⼀个基础字符串中根据⼀定的匹配模式替换⽂本中的字符串、验证表单、提取字符串
等等。
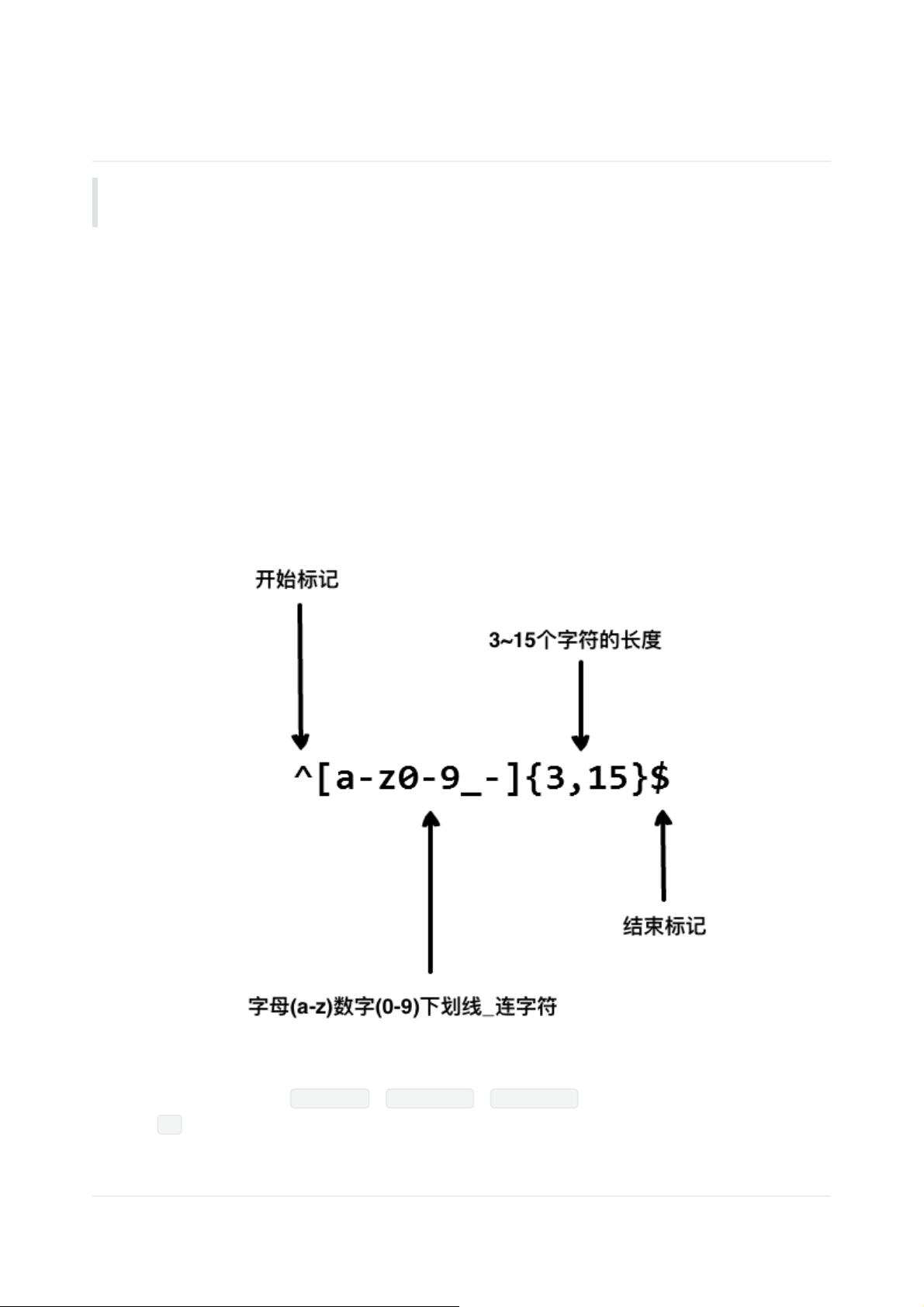
想象你正在写⼀个应⽤,然后你想设定⼀个⽤户命名的规则,让⽤户名包含字符、数字、下划线和连字
符,以及限制字符的个数,好让名字看起来没那么丑。
我们使⽤以下正则表达式来验证⼀个⽤户名:
以上的正则表达式可以接受 john_doe 、 jo-hn_doe 、 john12_as 。
但不匹配 Jo ,因为它包含了⼤写的字⺟⽽且太短了。
⽬录

剩余10页未读,继续阅读
资源评论


lnnocenceevil
- 粉丝: 4
- 资源: 6









最新资源
- 基于LSTM的淘宝商品评论分析系统详细文档+全部资料+优秀项目.zip
- 基于MKR模型的图书推荐系统 torch+flask+mysql——NLP详细文档+全部资料+优秀项目.zip
- 基于NLP的微博舆情分析系统详细文档+全部资料+优秀项目.zip
- 基于nlp的医疗问答系统详细文档+全部资料+优秀项目.zip
- 基于NLP和KNN的任务推荐系统详细文档+全部资料+优秀项目.zip
- 基于检索的问答系统详细文档+全部资料+优秀项目.zip
- 基于开放域事件提取的社会心态交互式挖掘与引导系统详细文档+全部资料+优秀项目.zip
- 基于篇章结构自动作文评分系统详细文档+全部资料+优秀项目.zip
- 基于实现一个舆情监控系统,具体基于对知乎热榜话题的数据抓取、分析与可视化。详细文档+全部资料+优秀项目.zip
- 基于文档的问答系统详细文档+全部资料+优秀项目.zip
- 基于医药知识图谱的智能问答系统详细文档+全部资料+优秀项目.zip
- 基于一个NLP旅游景点问答系统,基于BM25,Fuzzy算法实现详细文档+全部资料+优秀项目.zip
- 基于自然语言处理的智能医疗诊断系统详细文档+全部资料+优秀项目.zip
- 餐具包装纸袋包装机(sw12可编辑+CAD+说明书)全套技术开发资料100%好用.zip
- 岚精灵扫码挪车系统(移动端)(用户端-管理端)
- QWG(RZ)22-2004 高强度焊接结构用热连轧钢板和钢带.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


