
浏览器如何工作?
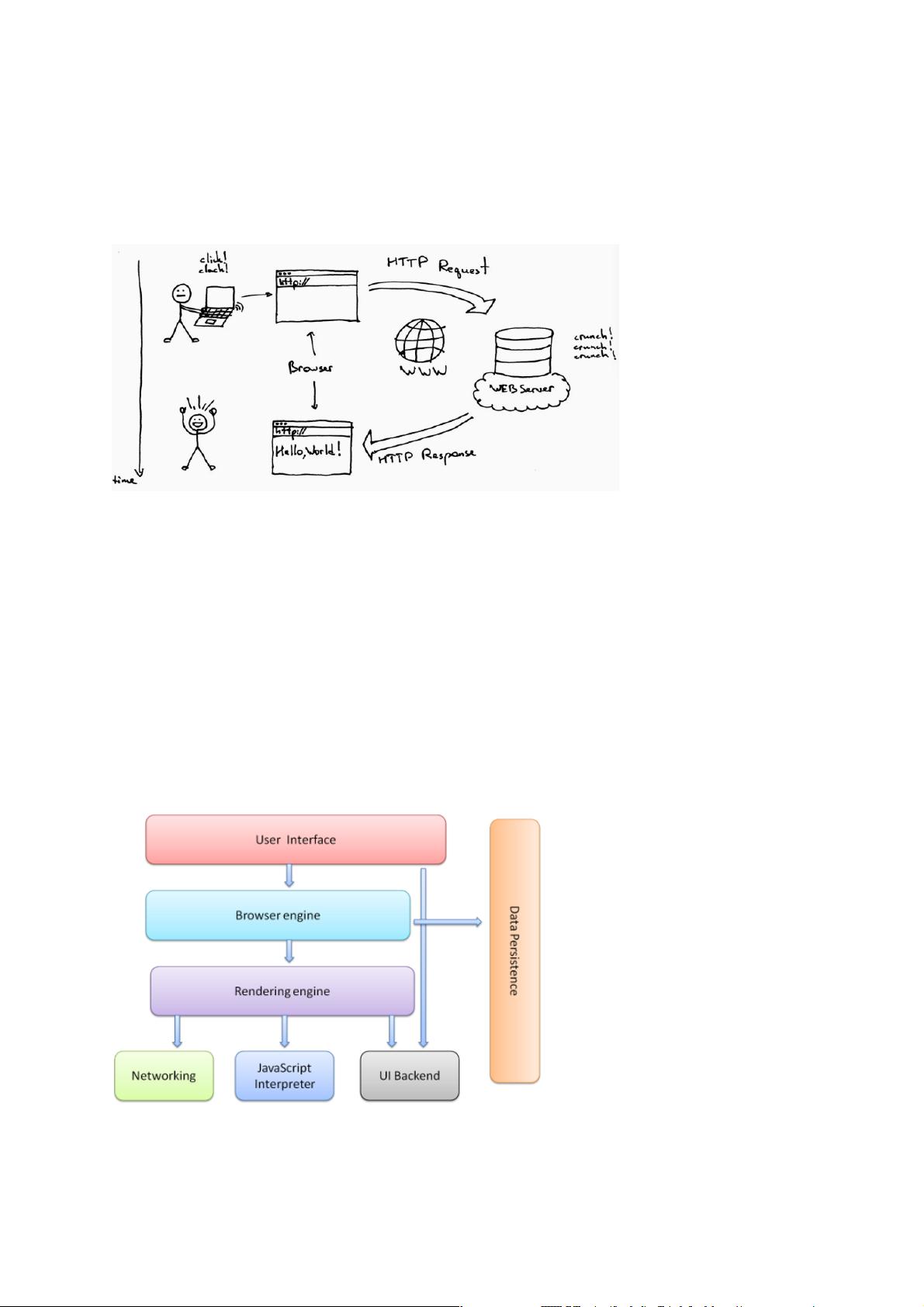
浏览器是网络世界里至关重要的工具之一。下图是一个用户使用浏览器的基本用户场
景:
但浏览器究竟是如何能够做到这些的呢?理解浏览器的工作流程和原理,所谓知其然
而知其所以然,一定会对我们的工作有所裨益。
首先我们了解下常用的浏览器和浏览器的组成部分。
常用浏览器
常用的桌面浏览器有 Chrome,Internet Explorer, Firefox,Safari, Opera。
常用的移动设备浏览器: Android 浏览器,iPhone 浏览器,Chrome,Opera Mini,
Opera Mobile, UC 浏览器等等。
浏览器组成
浏览器主要分成以下 7 部分:
1) UI – The User Interface

剩余8页未读,继续阅读
资源评论













