Visibility-Aware_Point-Based_Multi-View_Stereo_Network.pdf

需积分: 0 125 浏览量
更新于2024-11-19
收藏 6.54MB PDF 举报
多视图立体三维重建MVS论文

Visibility-Aware Point-Based
Multi-View Stereo Network
Rui Chen , Songfang Han, Jing Xu , and Hao Su
Abstract—We introduce VA-Point-MVSNet, a novel visibility-aware point-based deep framework for multi-view stereo (MVS). Distinct
from existing cost volume approaches, our method directly processes the target scene as point clouds. More specifically, our method
predicts the depth in a coarse-to-fine manner. We first generate a coarse depth map, convert it into a point cloud and refine the point cloud
iteratively by estimating the residual between the depth of the current iteration and that of the ground truth. Our network leverages 3D
geometry priors and 2D texture information jointly and effectively by fusing them into a feature-augmented point cloud, and processes the
point cloud to estimate the 3D flow for each point. This point-based architecture allows higher accuracy, more computational efficiency
and more flexibility than cost-volume-based counterparts. Furthermore, our visibility-aware multi-view feature aggregation allows the
network to aggregate multi-view appearance cues while taking into account visibility. Experimental results show that our approach
achieves a significant improvement in reconstruction quality compared with state-of-the-art methods on the DTU and the Tanks and
Temples dataset. The code of VA-Point-MVSNet proposed in this work will be released at https://github.com/callmeray/PointMVSNet.
Index Terms—Multi-view stereo, 3D deep learning
Ç
1INTRODUCTION
M
ULTI-VIEW stereo (MVS) aims to reconstruct the dense
geometry of a 3D object from a sequence of images and
corresponding camera poses and intrinsic parameters. MVS
has been widely used in various applications, including
autonomous driving, robot navigation, and remote sens-
ing [1], [2]. Recent learning-based MVS methods [3], [4], [5]
have shown great success compared with their traditional
counterparts as learning-based approaches are able to learn to
take advantage of scene global semantic information, includ-
ing object materials, specularity, 3D geometry priors, and
environmental illumination, to get more robust matching and
more complete reconstruction. Most of these approaches
apply dense multi-scale 3D CNNs to predict the depth map
or voxel occupancy. However, 3D CNNs require memory
cubic to the model resolution, which can be potentially pro-
hibitive to achieving optimal performance. While Tatarch-
enko et al. [6] addressed this problem by progressively
generating an Octree structure, the quantization artifacts
brought by grid partitioning still remain, and errors may
accumulate since the tree is generated layer by layer. More-
over, MVS fundamentally relies on finding photo-consistency
across the input images. However, image appearance cues
from invisible views, which includes being occluded and out
of FOV (Field of View), are not consistent with those from visi-
ble views, which is misguiding for accurate depth prediction
and therefore needs robust handling.
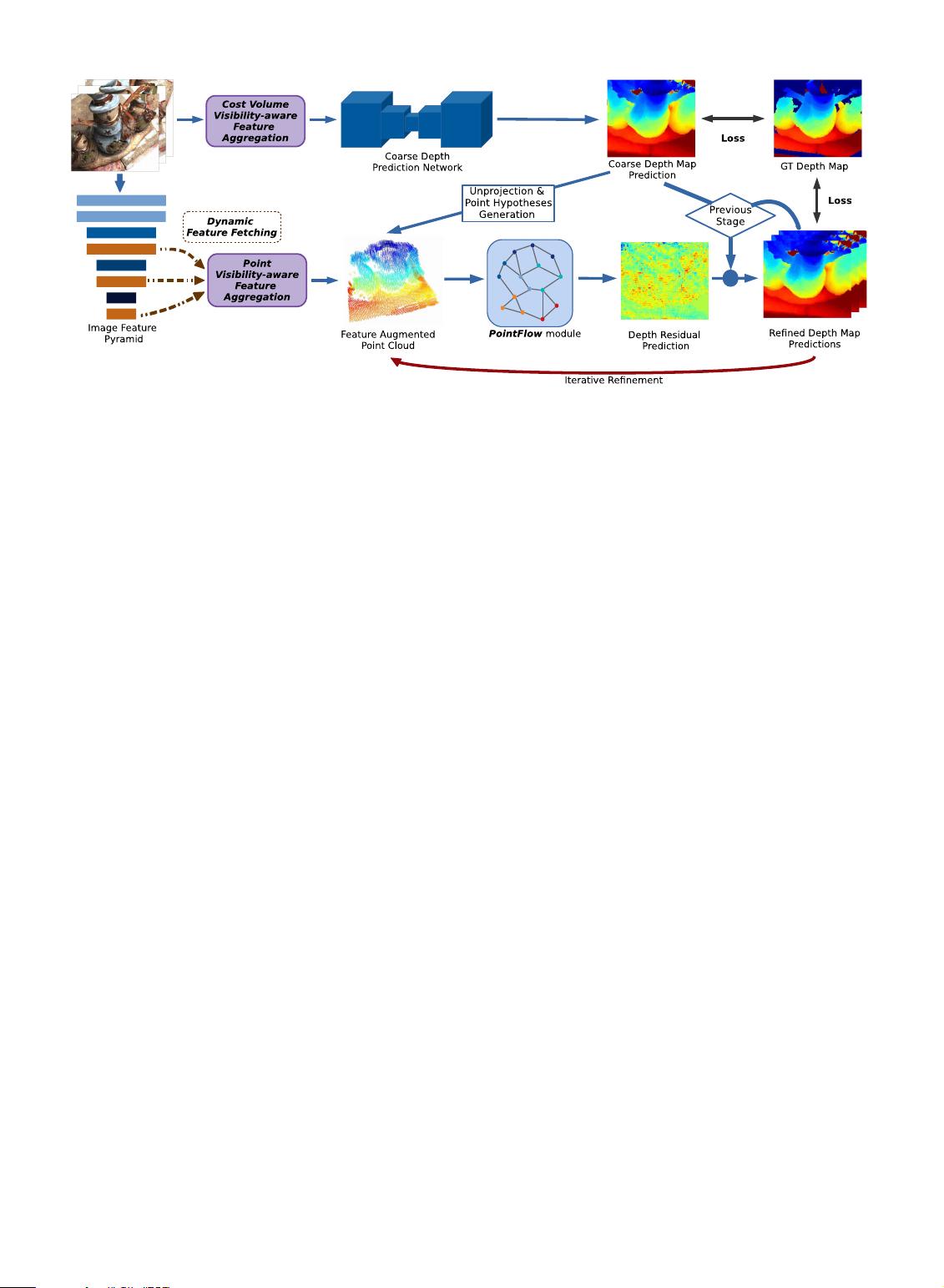
In this work, we propose a novel Visibility-Aware Point-
based Multi-View Stereo Network (VA-Point-MVSNet),
where the target scene is directly processed as a point cloud,
a more efficient representation, particularly when the 3D
resolution is high. Our framework is composed of two steps:
first, in order to carve out the approximate object surface
from the whole scene, an initial coarse depth map is gener-
ated by a relatively small 3D cost volume and then con-
verted to a point cloud. Subsequently, our novel PointFlow
module is applied to iteratively regress accurate and dense
point clouds from the initial point cloud. Similar to
ResNet [7], we explicitly formulate the PointFlow to predict
the residual between the depth of the current iteration and
that of the ground truth. The 3D flow is estimated based on
geometry priors inferred from the predicted point cloud
and the 2D image appearance cues dynamically fetched
from multi-view input images (Fig. 1). Moreover, in order
to take into account visibility, including occlusion and out
of FOV, for accurate MVS reconstruction, we propose a
number of network structure alternatives that infer the visi-
bility of each view for the multi-view feature aggregation.
We find that our VA-Point-MVSNet framework enjoys
advantages in accuracy, efficiency, and flexibility when it is
compared with previous MVS methods that are built upon
a predefined 3D cost volume with a fixed resolution to
aggregate information from views. Our method adaptively
samples potential surface points in the 3D space. It keeps
the continuity of the surface structure naturally, which is
necessary for high precision reconstruction. Furthermore,
because our network only processes valid information near
R. Chen and J. Xu are with the State Key Laboratory of Tribology, the
Beijing Key Laboratory of Precision/Ultra-Precision Manufacturing
Equipment Control, Department of Mechanical Engineering, Tsinghua
University, Beijing 100084, China.
E-mail: callmeray@163.com, jingxu@tsinghua.edu.cn.
S. Han is with The Hong Kong University of Science and Technology,
Hong Kong. E-mail: hansongfang@gmail.com.
H. Su is with the Department of Computer Science a nd Eng ineering,
University of California, San Diego, San Diego, CA 92093 USA.
E-mail: haosu@eng.ucsd.edu.
Manuscript received 13 Oct. 2019; revised 2 Apr. 2020; accepted 15 Apr. 2020.
Date of publication 22 Apr. 2020; date of current version 2 Sept. 2021.
(Corresponding author: Jing Xu.)
Recommended for acceptance by T. Hassner.
Digital Object Identifier no. 10.1109/TPAMI.2020.2988729
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 43, NO. 10, OCTOBER 2021 3695
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see https://creativecommons.org/licenses/by/4.0/

剩余13页未读,继续阅读
2022-11-14 上传
183 浏览量
185 浏览量
173 浏览量
115 浏览量
176 浏览量
2015-01-29 上传
144 浏览量
2021-06-03 上传
2023-06-06 上传
110 浏览量
2020-03-05 上传
2022-07-15 上传
149 浏览量
2021-09-30 上传
143 浏览量
2021-09-03 上传
2018-03-21 上传
2021-10-10 上传
189 浏览量
2018-08-22 上传
2021-09-30 上传
192 浏览量
2022-01-09 上传
133 浏览量
2021-10-01 上传
124 浏览量
资源评论



GL_Rain
- 粉丝: 2015
- 资源: 36









