分布式计算开源框架Hadoop入门实践.pdf
版权申诉
43 浏览量
2022-11-18
12:05:57
上传
评论
收藏 822KB PDF 举报


── 分布式计算开源框架 Hadoop 入门实践(一)
在 SIP 项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多
线程处理模式来分析统计,在我从前写的文章《Tiger Concurrent Practice --
日志分析并行分解设计与实现》中有所提到。但是由于统计的内容暂时还是十分
简单,所以就采用 Memcache 作为计数器,结合 MySQL 就完成了访问控制以及统
计的工作。然而未来,对于海量日志分析的工作,还是需要有所准备。现在最火
的技术词汇莫过于“云计算”,在 Open API 日益盛行的今天,互联网应用的数
据将会越来越有价值,如何去分析这些数据,挖掘其内在价值,就需要分布式计
算来支撑海量数据的分析工作。
回过头来看,早先那种多线程,多任务分解的日志分析设计,其实是分布式计算
的一个单机版缩略,如何将这种单机的工作进行分拆,变成协同工作的集群,其
实就是分布式计算框架设计所涉及的。在去年参加 BEA 大会的时候,BEA 和 VMWare
合作采用虚拟机来构建集群,无非就是希望使得计算机硬件能够类似于应用程序
中资源池的资源,使用者无需关心资源的分配情况,从而最大化了硬件资源的使
用价值。分布式计算也是如此,具体的计算任务交由哪一台机器执行,执行后由
谁来汇总,这都由分布式框架的 Master 来抉择,而使用者只需简单地将待分析
内容提供给分布式计算系统作为输入,就可以得到分布式计算后的结果。
Hadoop 是 Apache 开源组织的一个分布式计算开源框架,在很多大型网站上都已
经得到了应用,如亚马逊、Facebook 和 Yahoo 等等。对于我来说,最近的一个
使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也
正好符合了分布式计算的适用场景(日志分析和索引建立就是两大应用场景)。
当前没有正式确定使用,所以也是自己业余摸索,后续所写的相关内容,都是一
个新手的学习过程,难免会有一些错误,只是希望记录下来可以分享给更多志同
道合的朋友。
什么是 Hadoop?
搞什么东西之前,第一步是要知道 What(是什么),然后是 Why(为什么),最
后才是 How(怎么做)。但很多开发的朋友在做了多年项目以后,都习惯是先 How,
然后 What,最后才是 Why,这样只会让自己变得浮躁,同时往往会将技术误用于
不适合的场景。
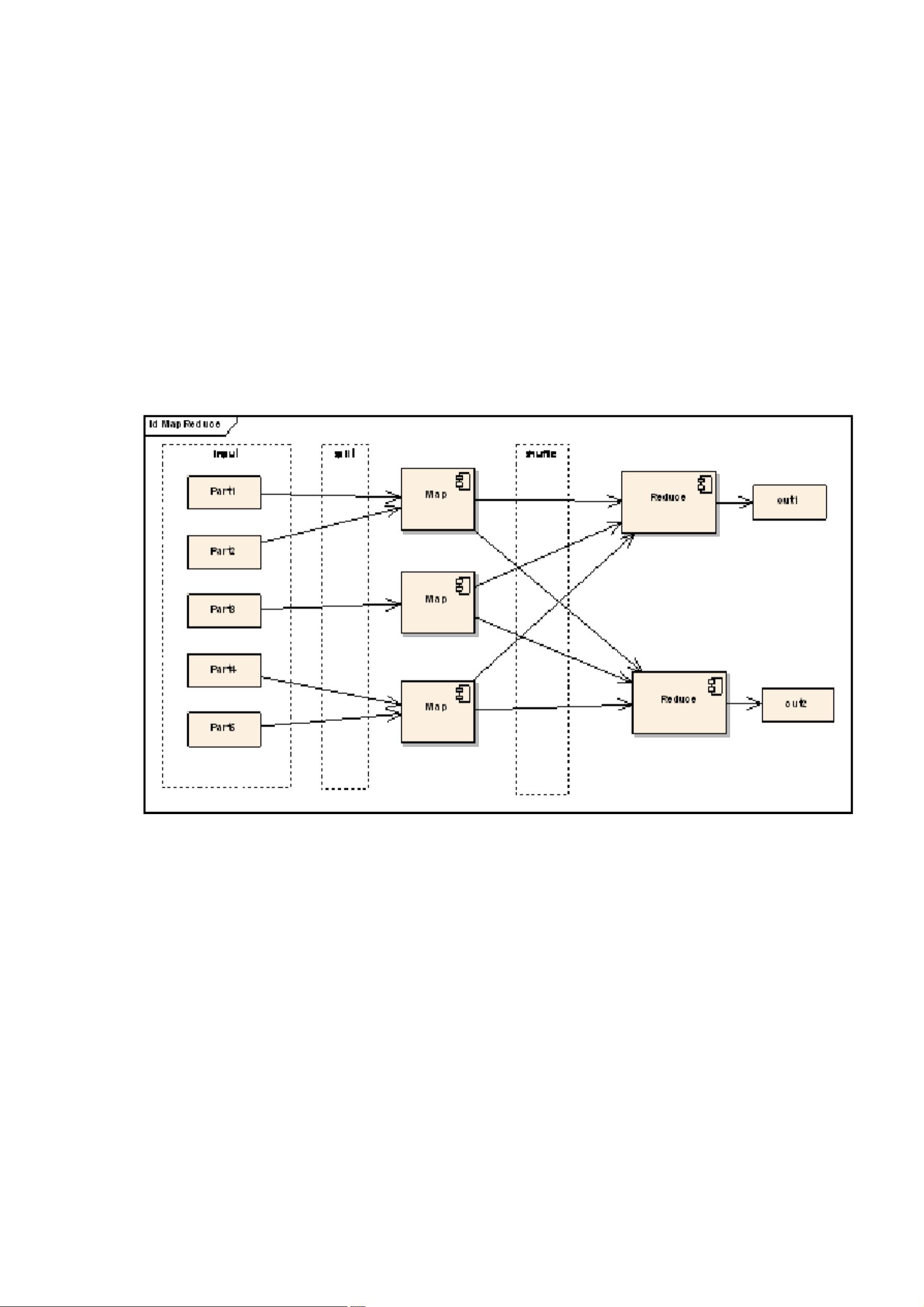
Hadoop 框架中最核心的设计就是:MapReduce 和 HDFS。MapReduce 的思想是由
Google 的一篇论文所提及而被广为流传的,简单的一句话解释 MapReduce 就是
“任务的分解与结果的汇总”。HDFS 是 Hadoop 分布式文件系统(Hadoop
Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce 从它名字上来看就大致可以看出个缘由,两个动词 Map 和 Reduce,
“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后
多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在


剩余18页未读,继续阅读






评论0
最新资源