# logisticRegression
**logistic Model 对数几率回归模型**
西瓜、鸢尾花分类算法实现
## 1、对数几率回归算法
### 1.1、Logistic回归(LR)
logistic回归是一种常用的处理二分类问题的模型。
二分类问题中,把结果y分成两个类,正类和负类。因变量y∈{0, 1},0是负类,1是正类。线性回归$f(x)=\theta^Tx$的输出值在负无穷到正无穷的范围上,并不好区分是正类还是负类。因此引入非线性变换,把线性回归的输出值压缩到(0, 1)之间,那就成了Logistic回归$h_\theta(x)$,使得$h_\theta(x)$≥0.5时,预测y=1,而当$h_\theta(x)$<0.5时,预测y=0。
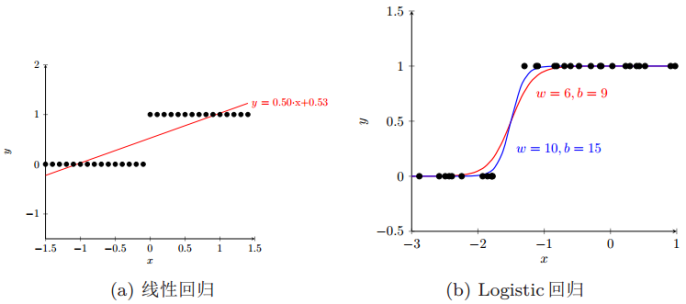
逻辑回归的定义式:
$h_\theta(x)=g(\theta^Tx)$,x代表样本的特征向量。
其中,
$g(x)=\frac{1}{1+e^{-z}}$为sigmoid函数,

$h_\theta(x)$可以理解为预测为正类的概率,即后验概率$h_\theta(x)=p(y=1|x;\theta)$,的取值范围是(0, 1)。
所以Logistic回归模型就是:
$$
h_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{\theta^Tx}}
$$
判断类别:
$h_\theta(x) \geq 0.5$, 即 $\theta^T x>0$ 时, 预测 $y=1$
$h_\theta(x)<0.5$, 即 $\theta^T x<0$ 时, 预测 $y=0$
对loss函数求导得到:
$$
\begin{aligned}
&J(\theta)=\frac{1}{m} \sum_{i=1}^m \operatorname{cost}\left(h_\theta\left(x^i\right), y^i\right) \\
&\operatorname{cost}\left(h_\theta(x), y\right)=\left\{\begin{array}{cc}
-\log \left(h_\theta(x)\right) & \text { if } \mathrm{y}=1 \\
-\log \left(1-h_\theta(x)\right) & \text { if } \mathrm{y}=0
\end{array}\right.
\end{aligned}
$$
当类别y=1时,损失随着$h_\theta(x)$的减小而增大,$h_\theta(x)$为1时,损失为0;
当类别y=0时,损失随着的增大而增大,$h_\theta(x)$为0时,损失为0。
### 1.2、损失函数
$$
J(\theta)=\frac{1}{m} \sum_{i=1}^m\left[-y^{(i)} \log \left(h_\theta\left(x^{(i)}\right)\right)-\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right)\right]
$$
这个损失函数叫做对数似然损失函数,也叫:交叉熵损失函数(cross entropy loss)。这个损失函数是个凸函数,因此可以用梯度下降法求得使损失函数最小的参数。
### 1.3、梯度下降
$$
\begin{aligned}
\theta_j: &=\theta_j-\alpha \frac{\partial J(\theta)}{\partial \theta_j} \\
&=\theta_j-\alpha \frac{1}{m} \sum_{i=1}^m\left(h_\theta\left(x^i\right)-y^i\right) x_j^i
\end{aligned}
$$
### 1.4、数据集特征分析
本次实验采用西瓜数据集以及鸢尾花数据集,西瓜数据集中包含17个样本,每个西瓜样本包含两维特征,包括西瓜的含糖量以及密度,以及对应的好瓜和坏瓜标签用0和1表示。鸢尾花数据集中包含150个样本,每个样本包含四维特征分别是花萼长、花萼宽、花瓣长、花瓣宽,以及对应的鸢尾花品种标签,三个鸢尾花品种分别用0、1、2表示。
由于西瓜数据集样本数量较少,因此这里采用将所有17个样本作为训练集,并再次利用17个样本作为测试集验证模型的准确度。将鸢尾花数据集以8:2的比例切分为训练集和测试集。最后使用sklearn自带的模型验证工具对本次实现的对数几率回归模型进行精准度分析。
对于鸢尾花数据集的多分类问题,我采用的是OVR的方式,分别将鸢尾花的三个品种作为正例,将剩余两个品种作为负例训练三个分类器,再计算每个分类器的置信度,将置信度最高的分类器作为样本的预测结果。由此得到的多分类模型在鸢尾花数据集上的分类准确度最高可以达到100%。
## 2、模型预测结果及分析
### 2.1、西瓜数据集分类结果及分析
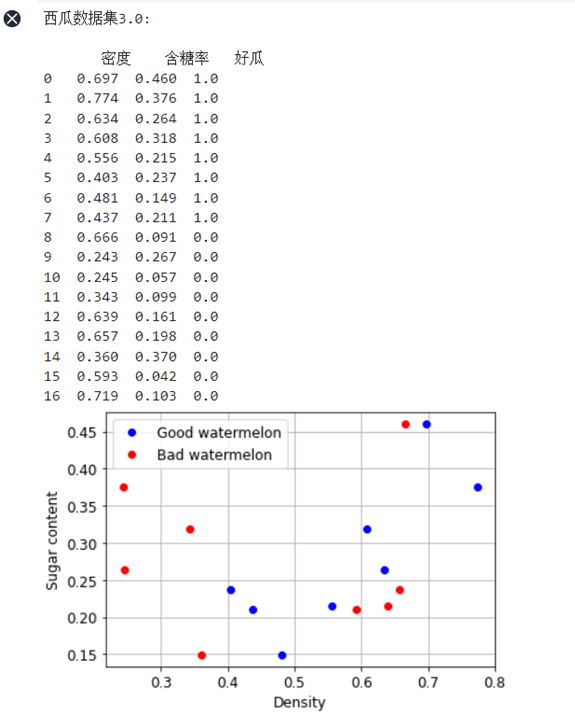
以上是西瓜数据集,西瓜数据集每个样本有含糖量以及密度两维特征,以及对应的好瓜和坏瓜标签。以及对应的数据分布情况,由上图可以可以看出西瓜数据集的含糖量以及密度分布并不是很规范,因此导致后面的对数几率回归分类模型的准确度最多只能达到70-80%,

通过参数的调试当w初始值设为0.05,迭代次数1000时模型的准确率达到71%,通过调试的过程可以发现准确率在60-70%左右。 这也是数据集的数据量少和样本分布规律并不明显导致的。
### 2.2、鸢尾花数据集分类结果及分析
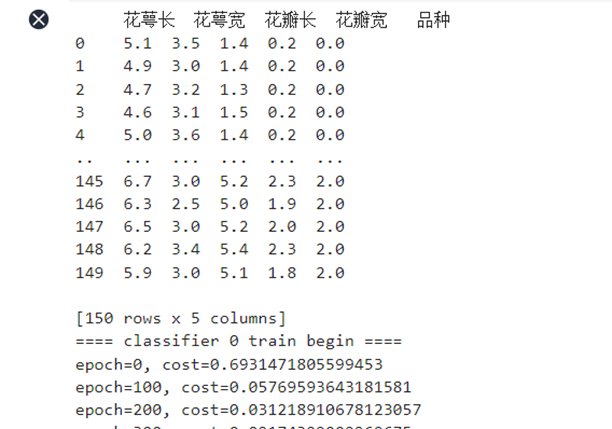
鸢尾花数据集中包含150个样本,每个样本包含四维特征分别是花萼长、花萼宽、花瓣长、花瓣宽,以及对应的鸢尾花品种标签,三个鸢尾花品种分别用0、1、2表示。鸢尾花数据集数据量充足,因此将鸢尾花数据集以8:2的比例切分为训练集和测试集。

在此多分类模型中,我采用地OVR的方式,训练出来的三个分类器。可以明显地看到随着迭代次数地增多,损失函数值下降,直到最终收敛。在参数调试过程中发现模型的准确率在90-100%之间浮动,通过不断地参数调整,当w的初始值设为0,学习率设为0.1,迭代次数设置为5000代时,模型的准确率达到最高100%。这也充分说明初始值设置以及调参对模型的收敛以及准确性起着至关重要的作用。
## 3、文件目录
|-- IrisRegress.py 鸢尾花数据集分类测试
|-- LogisticModel.py 对数几率回归模型
|-- README.md
|-- WaterRegress.py 西瓜数据集3.0分类测试
机器学习基于python实现对数几率回归模型对西瓜、鸢尾花进行分类源码+项目说明+实验报告.zip

版权申诉
39 浏览量
2024-05-09
06:42:22
上传
评论
收藏 270KB ZIP 举报
 机器学习基于python实现对数几率回归模型对西瓜、鸢尾花进行分类源码+项目说明+实验报告.zip (15个子文件)
机器学习基于python实现对数几率回归模型对西瓜、鸢尾花进行分类源码+项目说明+实验报告.zip (15个子文件)  code
code  WaterRegress.ipynb 27KB .idea vcs.xml 185B misc.xml 205B inspectionProfiles Project_Default.xml 445B profiles_settings.xml 179B modules.xml 295B .gitignore 50B LogisticRegression.iml 291B IrisRegress.ipynb 15KB WaterRegress.py 2KB LogisticModel.py 4KB __pycache__ LogisticModel.cpython-36.pyc 3KB
WaterRegress.ipynb 27KB .idea vcs.xml 185B misc.xml 205B inspectionProfiles Project_Default.xml 445B profiles_settings.xml 179B modules.xml 295B .gitignore 50B LogisticRegression.iml 291B IrisRegress.ipynb 15KB WaterRegress.py 2KB LogisticModel.py 4KB __pycache__ LogisticModel.cpython-36.pyc 3KB 实验1-对率回归算法实践.doc 331KB README.md 6KB IrisRegress.py 1KB
实验1-对率回归算法实践.doc 331KB README.md 6KB IrisRegress.py 1KB资源评论


FL1768317420
- 粉丝: 4293
- 资源: 4728









最新资源
- 基于Javascript的影视动画设计源码 - cad
- 基于Java和深度学习的瓦斯浓度预测系统后端设计源码 - 瓦斯浓度预测后端
- Screenshot_20240528_103010.jpg
- 基于Python的新能源承载力计算及界面设计源码 - HAINING-DG
- 基于Java的本科探索学习项目设计源码 - 本科探索
- 基于Javascript和Python的微商城项目设计源码 - MicroMall
- 基于Java的网上订餐系统设计源码 - online ordering system
- 基于Javascript的超级美眉网络资源管理应用模块设计源码
- 基于Typescript和PHP的编程知识储备库设计源码 - study-php
- Screenshot_2024-05-28-11-40-58-177_com.tencent.mm.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


