
AI 绘画教程:Stable Diffusion 中如何控制人像的姿势?
在 AI 绘画中,有时候我们需要主角(人物或动物)摆出特定的姿势,该怎么做呢?
第一种方法:以图生图
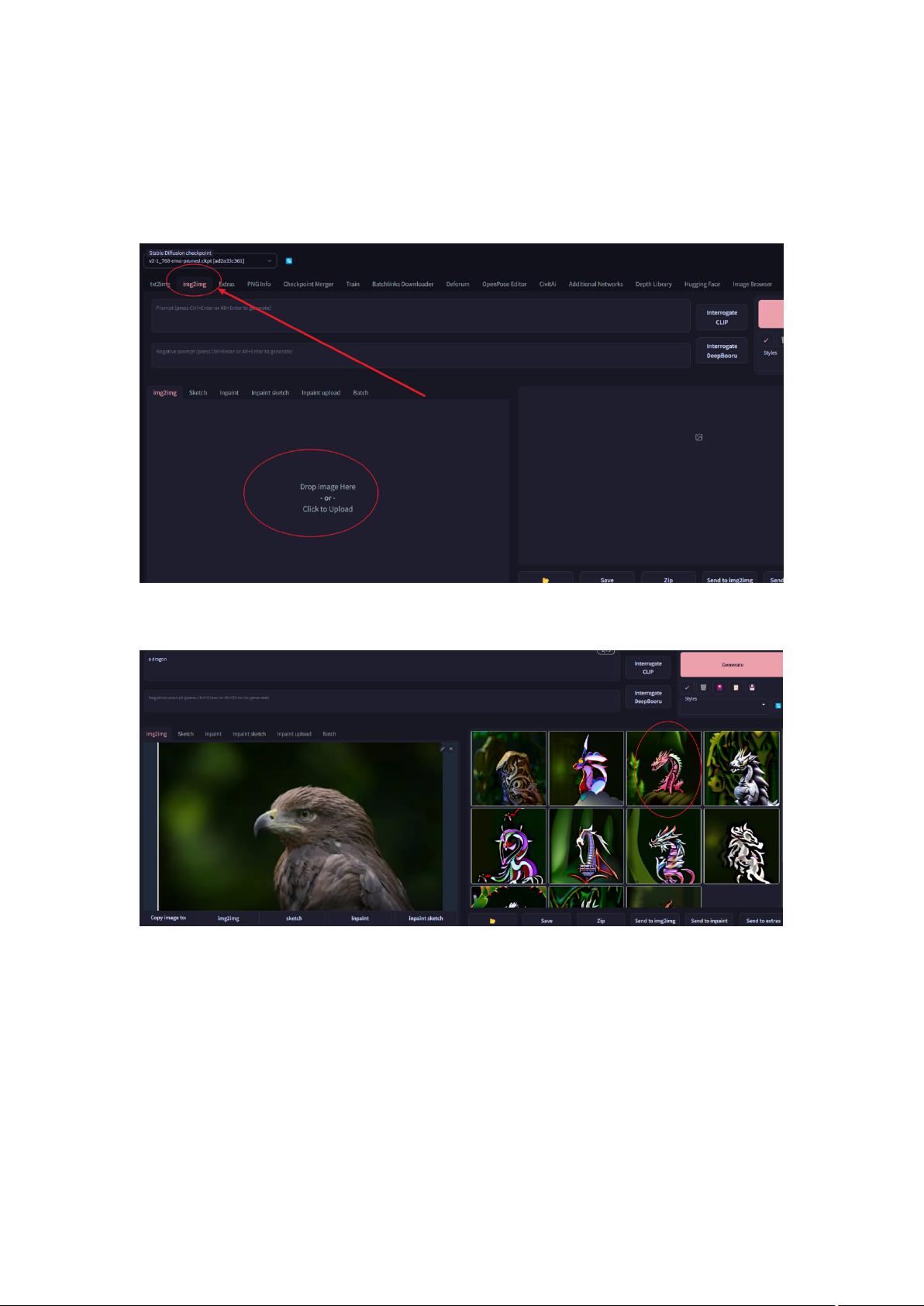
打开 Stable Diffusion 界面,点击 imag2img
下面出现一个”drop image here or click to upload”的方框,从网上找一张你希望呈现的姿势图
片,比如一个老鹰,姿势:双眼盯着远方。把这张图片拖拽到方框,或者从本地电脑上传。
然后在提示词框里输入提示词,比如:a dragon ,然后点击 generate 生成图像。但是这样生
成的图像,姿势不好控制,有些会比较像,有些差很远。
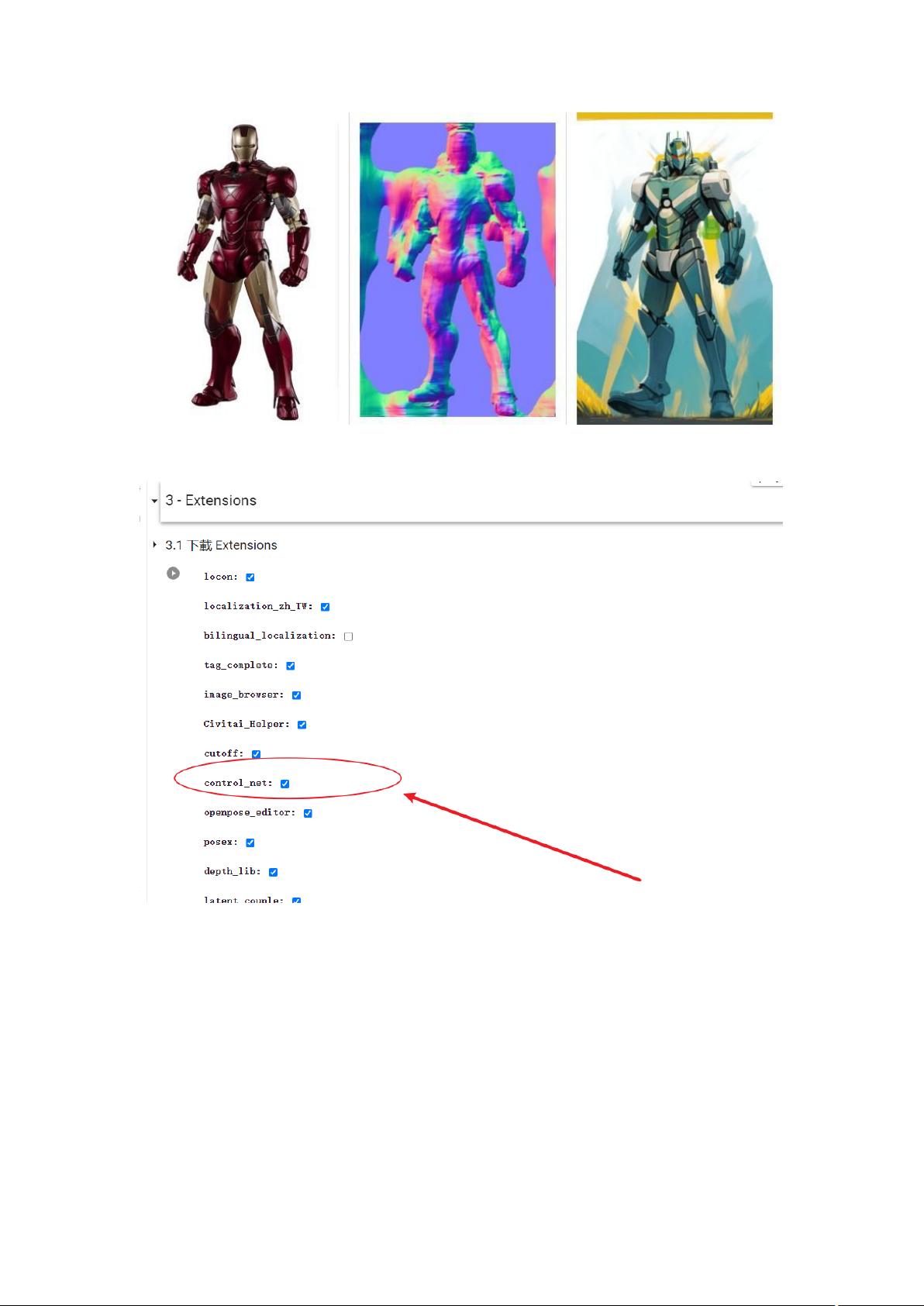
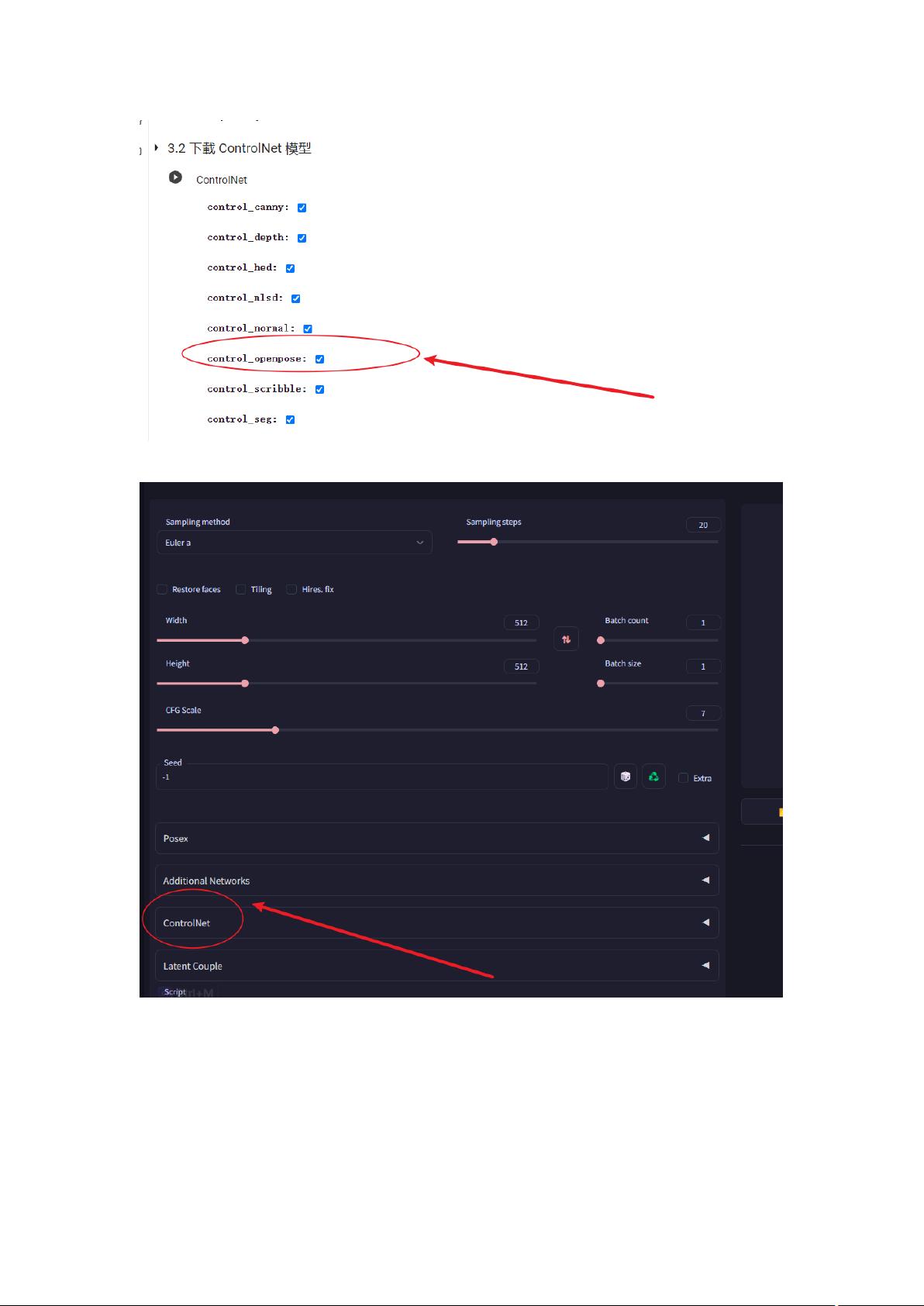
第二种方法:使用 ControlNet。这是一个很强大的 stable Diffusion 插件,可以精准的控制 AI
绘画中人物或动物的姿势,从而生成很多好玩有创意的图片。
比如,穿上钢铁侠战衣的擎天柱:
剩余13页未读,继续阅读
资源评论













