必看!大语言模型调研汇总!!.pdf
102 浏览量
2023-08-26
20:31:32
上传
评论
收藏 1.25MB PDF 举报


作者:guolipa @知乎
自从ChatGPT出现之后,各种大语言模型是彻底被解封了,每天见到的模型都能不重样,几乎分不清这
些模型是哪个机构发布的、有什么功能特点、以及这些模型的关系。比如 GPT-3.0 和 GPT 3.5 就有一系
列的模型版本和索引,还有羊驼、小羊驼、骆驼 ......
动图封面
于是浅浅的调研了一下比较有名的大语言模型,主要是想混个脸熟,整理完之后就感觉清晰多了,又可
以轻松逛知乎学习了。
动图封面
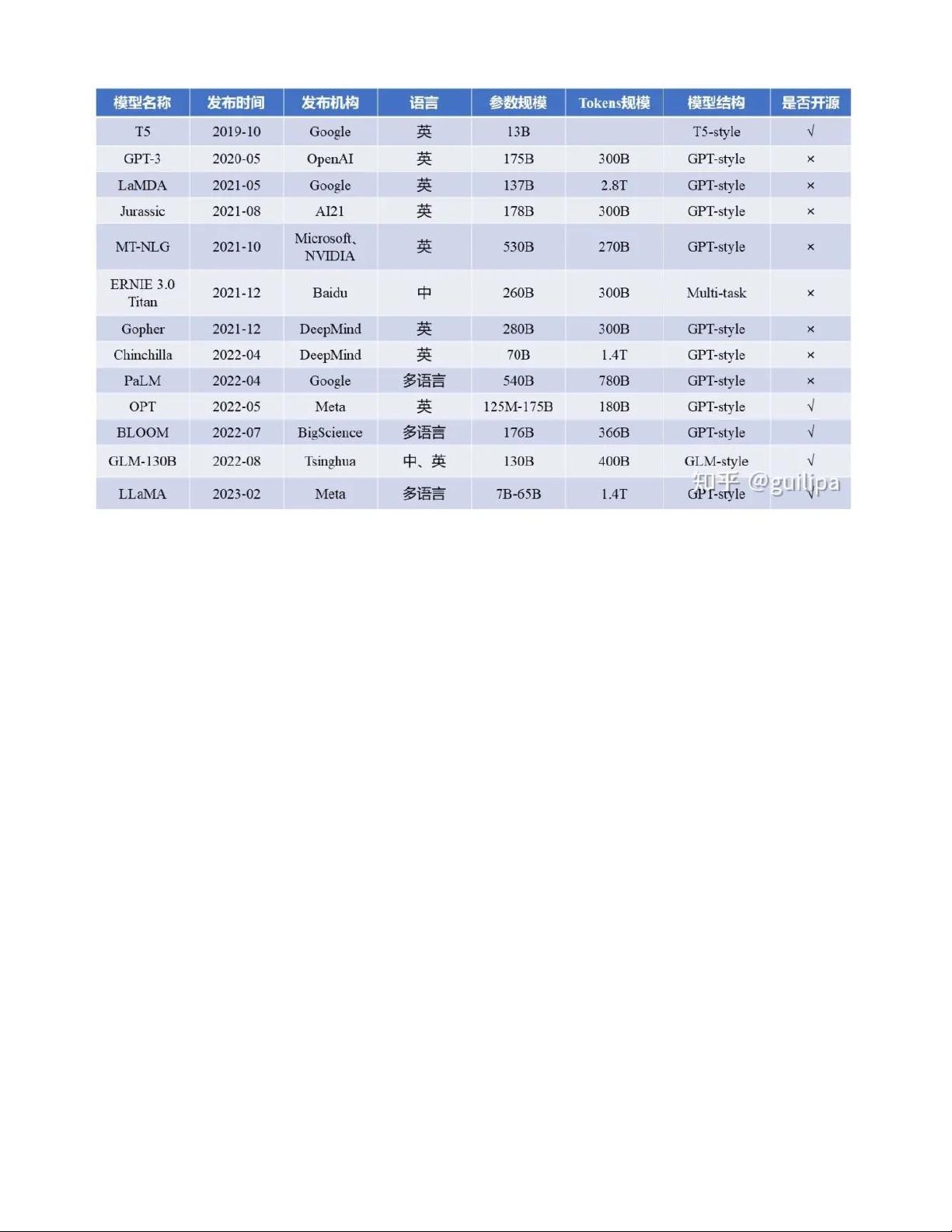
一一. Basic Language Model
基础语言模型是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类
反馈等任何对齐优化。

剩余17页未读,继续阅读
资源评论













