



文章目录
� 一、GPT 介绍
�
� 1.无监督预训练
� 2.有监督下游任务精调
� 3.适配不同的下游任务
� 二、基于 pytorch 自己训练一个小型 chatgpt
�
� 1.数据集
� 2. 模型
� 3.方法介绍
� 4.核心代码展示
� 4.实现效果
一、GPT 介绍
OpenAI 公式在 2018 年提出了一种生成式预训练(Generative
Pre-Trainging,GPT)模型用来提升自然语言理解任务的效果,正式将自然语言处
理带入预训练时代,预训练时代意味着利用更大规模的文本数据一级更深层次的
神经网络模型学习更丰富的文本语义表示。同时,GPT 的出现提出了“”生成式预
训练+判别式任务精调的自然语言处理新范式,使得自然语言处理模型的搭建变
得不在复杂。
� 生成式预训练:在大规模文本数据上训练一个高容量的语言模型,从而学
习更加丰富的上下文信息;
� 判别式任务精调:将预训练好的模型适配到下游任务中,并使用有标注的
数据学习判别式任务。
GPT 的整体结构是一个基于 Transformer 的单向语言模型,即从左到右对输入文
本建模,模型结构如图所示。
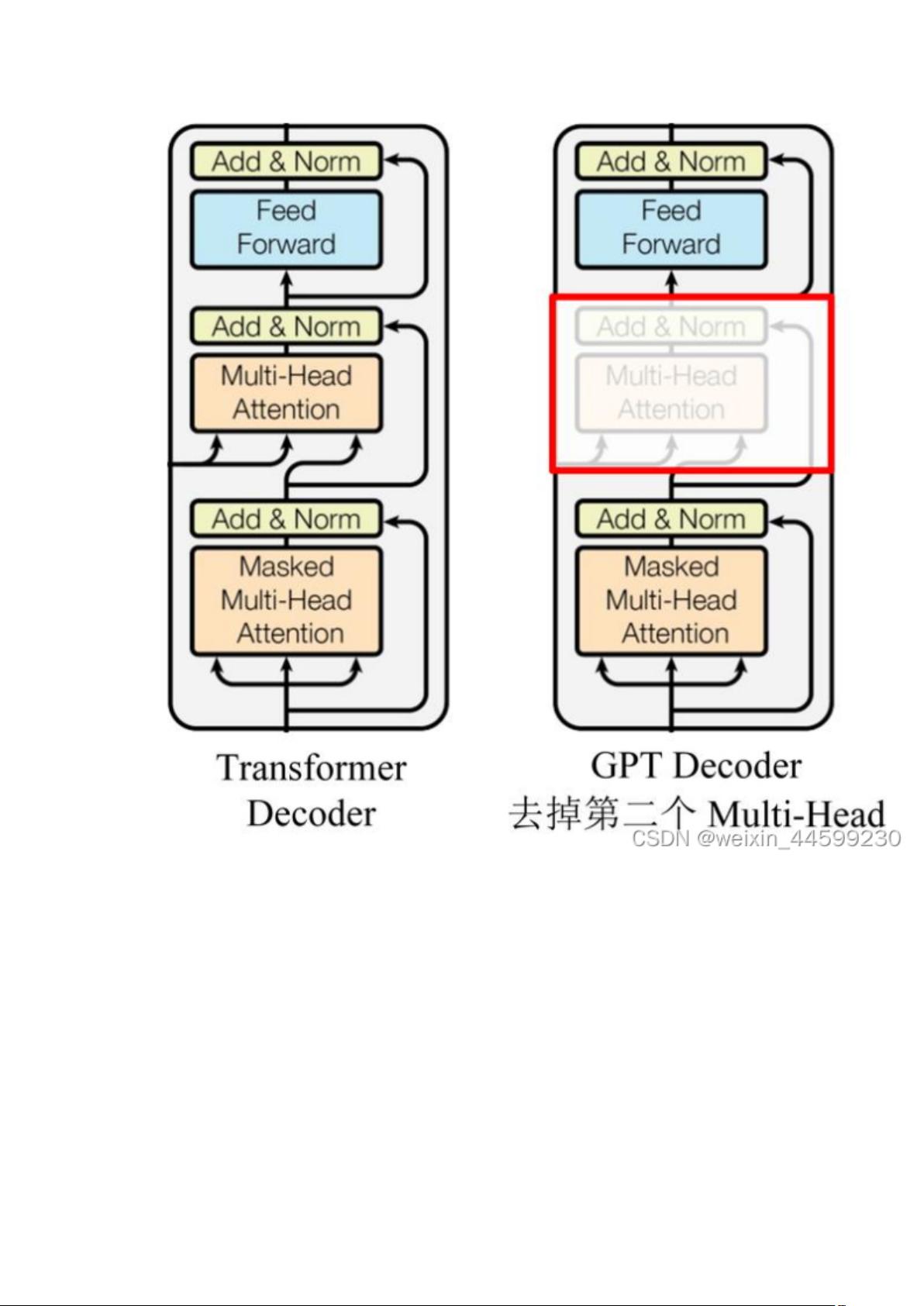
GPT 只使用了 Transformer 的 Decoder 结构,由于没有了 Encoder,就没有
Encoder 的输出,所以去掉了原本的 Encoder-Decoder Attention。
GPT 模型使用 Transformer 的 Decoder 结构,在 Decoder self-attention 结构中
使用了 mask 机制,将自注意力矩阵的上三角 mask 掉,每个单词只能获取它本
身以及它之前词的注意力,防止模型看到未来时刻信息,因为语言模型就是要预
测未来时刻单词的,让其看到未来时刻信息相当于作弊了,模型学不到任何东西。
如图所示,将上三角的值设置为负无穷,经过 softmax 计算后就会变成 0,每个
词只能注意到当前词以及之前词。例如图中,A 这个词这一行,只有第一列有值,
它只能注意自身,B 这个词这一行,它前两列有值,说明 B 只能注意到 A 以及
B,注意不到 C 和 D,因为模型需要根据 AB 去预测 C,所以不让模型注意到 C
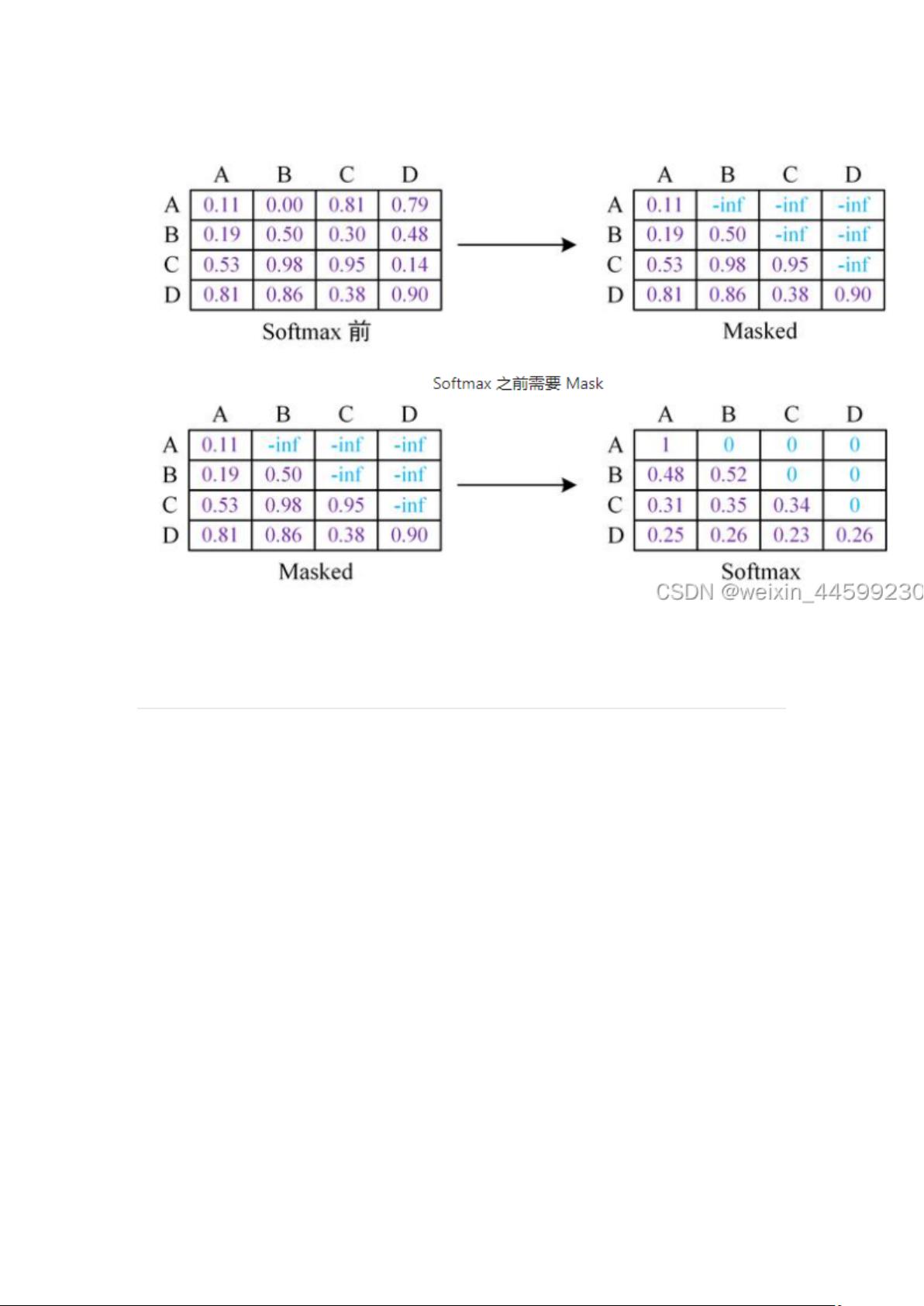
以及更靠后的信息。
1.无监督预训练
GPT 利用常规语言建模的方法优化给定文本序列 x = x 1 , x 2 , . . . , x n
x=x_{1},x_{2},...,x_{n} x=x1,x2,...,xn的最大似然估计 L P T L^{PT} LPT。
L P T = ∑ i l o g P ( x i ∣ x i − k . . . x i − 1 ; θ ) L^{PT} =
\sum_{i}^{}logP(x_{i}|x_{i-k}...x_{i-1};\theta ) LPT=i∑logP(xi∣xi−k...xi−1;θ)
式中 k 表示语言模型的窗口大小,即基于 k 个历史词 x i − k . . . x i − 1
x_{i-k}...x_{i-1} xi−k...xi−1预测当前时刻的词 x i x_{i} xi, θ \theta θ 表示神经网络
的参数。
对于长度为 k 的窗口词序列 x ′ = x − k . . . x − 1 x'=x_{-k}...x_{-1} x′=x−k...x−1,
通过以下方式计算建模概率 P。
h [ 0 ] = e x ′ W e + W p h^{[0]}=e_{x'}W^{e}+W^{p} h[0]=ex′We+Wp
h [ l ] = T r a n s f o r m e r - D e c o d e r ( h [ l − 1 ] ) , ∀ l ∈ 1,2,...,L
h^{[l]}=Transformer\text{-}Decoder(h^{[l-1]}),\forall l \in
\text{{1,2,...,L}} h[l]=Transformer-Decoder(h[l−1]),∀l∈1,2,...,L
P ( x ) = S o f t m a x ( h [ L ] W e T )
P(x)=Softmax(h^{[L]}W^{e^{T}}) P(x)=Softmax(h[L]WeT)

式中, e x ′ ∈ R k × ∣ V ∣ e_{x'} \in R^{k×|V|} ex′∈Rk×∣V∣表示 x ′ x' x′的独热向
量表示; W e ∈ R ∣ V ∣ × d W^{e} \in R^{|V|×d} We∈R∣V∣×d 表示词向量矩阵,
W p W^{p} Wp 表示位置向量矩阵,L 表示总层数。
现在模型一般不取 k 个历史词,而是取所有历史词。
2.有监督下游任务精调
在预训练阶段,GPT 利用大规模数据训练出基于深层 Transformer 的语言模型,
已经掌握了文本的通用语义表示。精调(fine-tuning)的目的在通用语义的表示
基础上,根据下游任务(Downstream task)的特征进行领域适配,使之与下游
任务的形式更加契合,以获得更好的下游任务应用效果。
下游任务精调通常是由有标签数据进行训练和优化的。假设下游任务的标注数据
为 C,其中每个样例的输入是 x = x 1 x 2 . . . x n x=x_{1}x_{2}...x_{n} x=x1
x2...xn构成的长度为 n 的文本序列,与之对应的标签为 y。首先将文本序列输入
预训练的 GPT 中,获得最后一层最后一个词对应的隐含层输出 h n [ L ]
h^{[L]}_{n} hn[L],紧接着,将该隐含层输出通过一层全连接层,预测最终标签 y。
P ( y ∣ x 1 , x 2 , . . . x n ) = S o f t m a x ( h n [ L ] W y )
P(y|x_{1},x_{2},...x_{n})=Softmax(h^{[L]}_{n}W^{y}) P(y∣x1,x2,...xn)=Softmax(h
n[L]Wy)
其中, W y ∈ R d ✖ c W^{y} \in R^{d✖c} Wy∈Rd✖c 表示全连接层权重,c 为
类别个数。
最终,通过优化以下损失函数精调下游任务。
L F T ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 . x 2 , . . . , x n ) L^{FT}(C) =
\sum_{(x,y)}^{}logP(y|x_{1}.x_{2},...,x_{n}) LFT(C)=(x,y)∑logP(y∣x1.x2,...,xn)
另外,为了进一步提升精调后模型的通用性以及收敛速度,可以在下游任务精调
时加入一定权重的预训练任务损失。这样做是为了缓解在下游任务精调时出现灾
难性遗忘问题。因为在下游任务精调过程中,GPT 的训目标是优化下游任务数
据上的效果,更强调特殊性。因此势必会对预训练阶段学习的通用知识产生部分
的覆盖或者擦除,丢失一定的通用性。通过结合下游任务精调损失和预训练任务
损失,可以有效缓解灾难性遗忘问题,在优化下游任务效果的同时保留一定的通
用性。在实际应用中,可通过下式精调下游任务。
L ( C ) = L F T ( C ) + λ L P T ( C ) L(C)=L^{FT}(C)+\lambda
L^{PT}(C) L(C)=LFT(C)+λLPT(C)
3.适配不同的下游任务
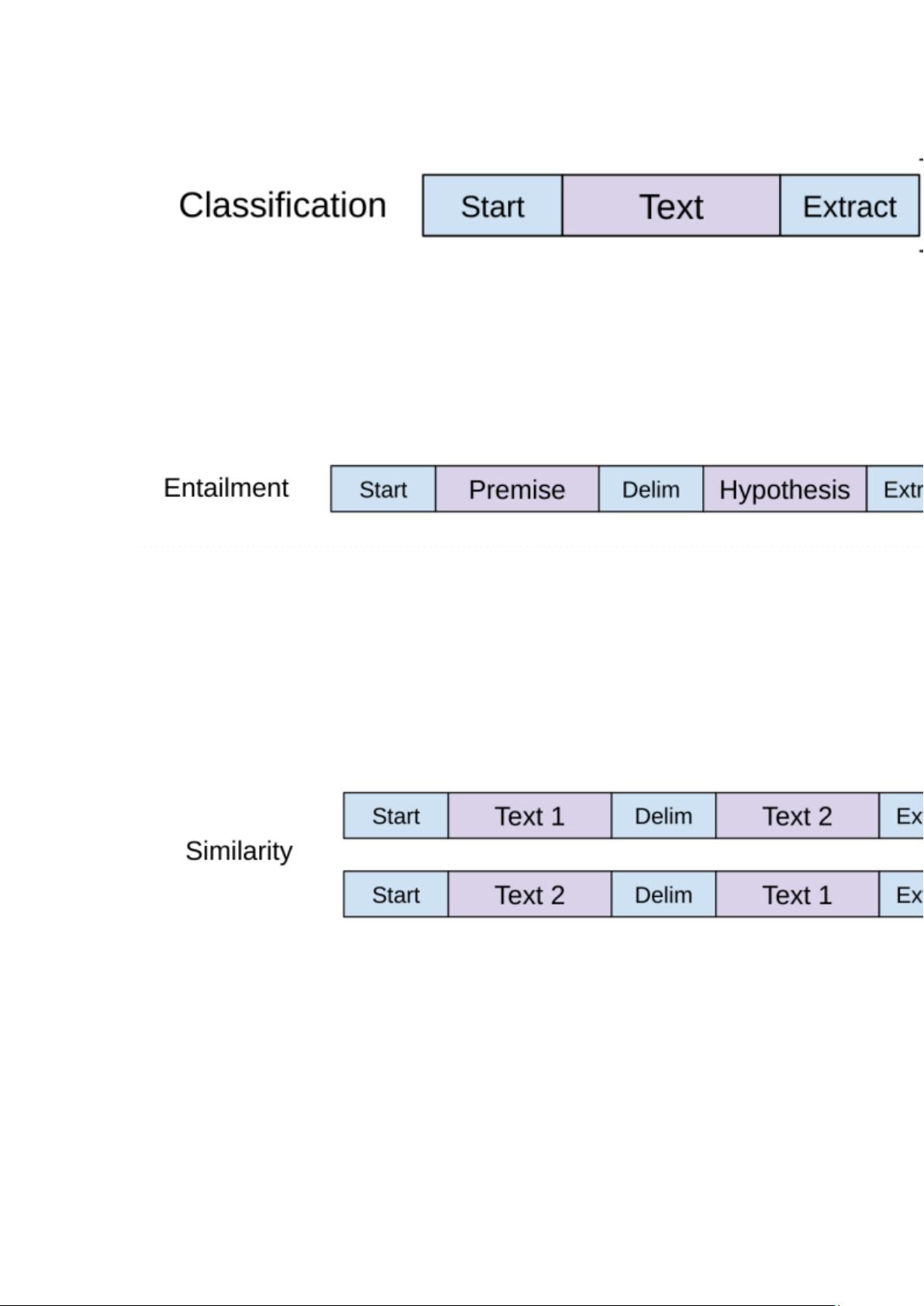
分类任务
对文本开头加一个开始标识符,结尾加上一个抽取标识符,将其输入 Transformer
解码器,最后的这个抽取标识符得到的结果在经过一个全连接层即可进行分类,
使用最后一个标识符的原因是最后一个标识符可以抽取前面所有词的信息。
蕴含任务
给一段话,然后给一个假设,判断这段话有没有蕴含假设提出的内容。
比如假设是 a 喜欢 b,给出的这段话是 a 喜欢 b,那么这段话是支持这个假设的,
如果给出这段话是 a 讨厌 b,那么这段话不支持这个假设,如果给出的这段话
是 a 和 b 是邻居,那么既不支持也不反对,其实本质也是一个三分类任务。将
两句话拼接起来,最开始加上开始符,中间加上分隔符,最后加上抽取符。
相似任务
判断两段话是否相似,也是需要将两段话拼接起来,前边加上开始符,中间分隔
符,最后抽取符。相似是一个对称问题,a 与 b 相似,那么 b 与 a 也是相似的,
所以需要将两句话交换个位置,构造两个序列输入模型,将两个结果相加经过全
连接层进行分类。
选择题













