大数据实时计算FlinkSQL解密
135 浏览量
2021-03-03
11:47:37
上传
评论
收藏 665KB PDF 举报

大数据实时计算大数据实时计算FlinkSQL解密解密
阿里巴巴自2015年开始调研开源流计算引擎,最终决定基于Flink打造新一代计算引擎,针对Flink存在的不足进行优化和改
进,并将最终代码贡献给开源社区。目前为止,我们已经向社区贡献了数百个Commiter。阿里巴巴将该项目命名为Blink,主
要由Blink Runtime与Flink SQL组成。Blink Runtime是阿里巴巴内部高度定制化的计算内核,Flink SQL则是面向用户的API
层,我们完善了部分功能,比如Agg、Join、Windows处理等。今年,我们已经全部跑通TPCH 及TPC-DS的Query,熟悉数
据库的人都知道,这代表着整个数据库或引擎是一个基本功能完备的产品。
接下来主要介绍Flink SQL的基本概念及使用。传统的流式计算引擎,比如Storm、Spark Streaming都会提供一些function或者
datastream API,用户通过Java或Scala写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随
着版本的不断更新,API也出现了很多不兼容的地方。
我们一直在思考最适合流计算处理的API,毫无疑问,SQL已经成为大数据领域通用且成熟的语言,因此我们的Flink和Blink均
基于此,之所以选择将SQL作为核心API,是因为其具有几个非常重要的特点,一是SQL属于设定式语言,用户只要表达清楚
需求即可,不需要了解具体做法;二是SQL可优化,内置多种查询优化器,这些查询优化器可为SQL翻译出最优执行计划;三是
SQL易于理解,不同行业和领域的人都懂;四是SQL非常稳定,在数据库30多年的历史中,SQL本身变化较少,非常稳定。当
我们升级或替换引擎时,用户是无感知的且完全兼容;最后,SQL经过优化可以统一流和批。
过去,我们既需要批模式跑全量数据,也需要流模式实时跑增量数据,因此需要同时维护两个引擎,并且保持两份代码之间的
同步。如果使用SQL,我们便可以一份代码同时跑在两个模式下,但SQL是为传统批处理设计的,并不能为流处理所用。SQL
定义在表上,而不是流上。传统SQL处理的数据集比较有限,查询一次只返回一个结果。但是,流处理需要不断接收数据,不
断对结果进行更新,并且查询也不会结束,这导致其需要对历史数据不断修正。所以,SQL的很多概念无法直接映射到流计
算,这就是在流计算上定义SQL的难点。
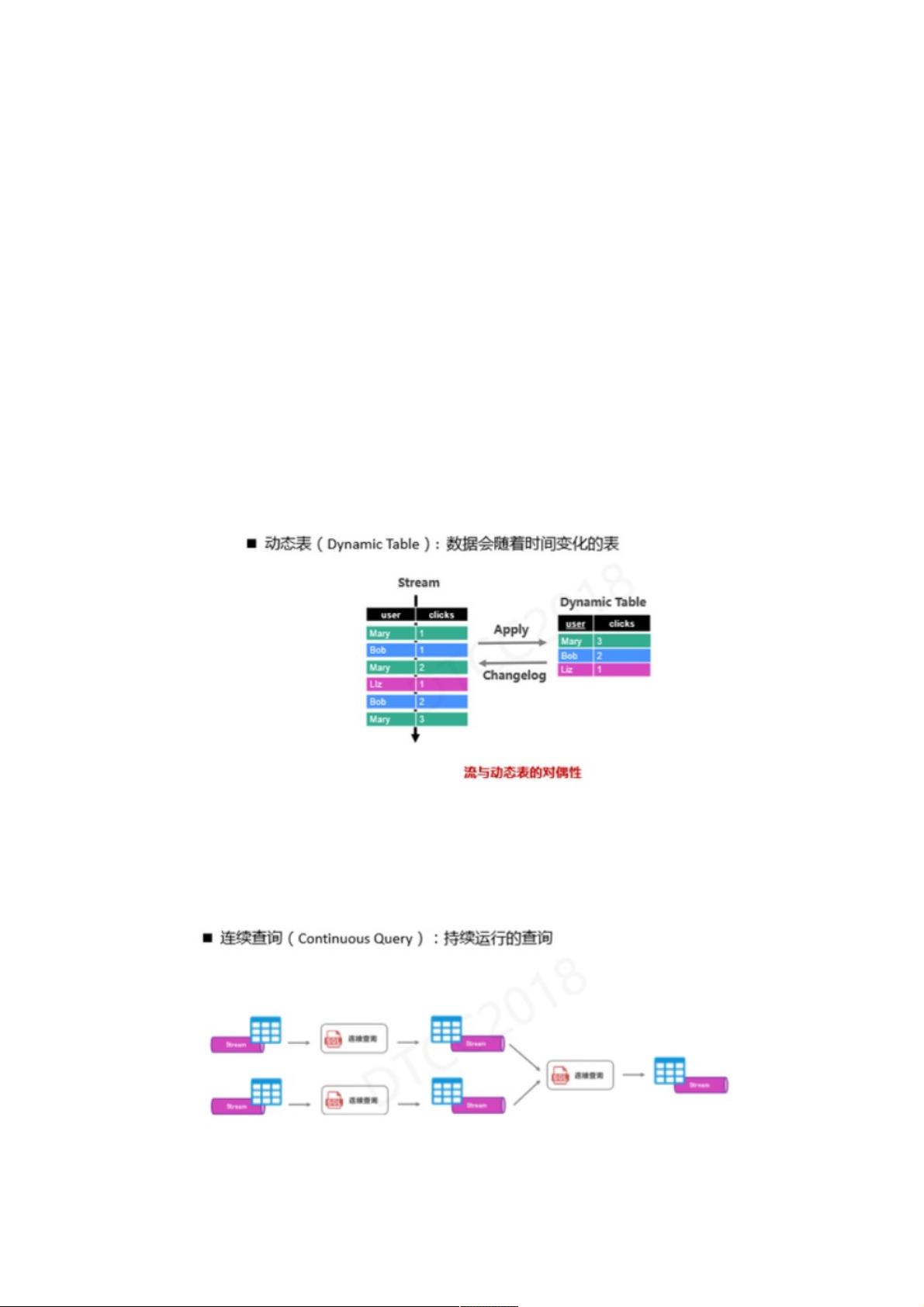
为了在流计算上定义SQL,我们需要引入几个概念。既然批处理需要定义SQL表的概念,那在流计算上也需要表的概念,我们
需要将传统静态表扩展成动态表,所谓动态表就是数据会随时间而不断变化的表。此时,我们发现流和动态表之间有一种对偶
性,也就是说流和动态表可以相互转换。将流的每条数据插入到数据库中,就得到了一张表;同时我们可以抽取动态表的
changelog还原原始流。
从流计算到SQL,我们可以把它看成是连续查询。连续查询区别于传统的批处理查询,需要源源不断地接收数据,每收到一条
新数据就会更新结果且结果也是一张动态表,那结果的动态表又可以作为下一个查询的输入,从而串起整个流计算。
基于上述两个概念,我们可以在SQL上定义流计算。但是,流计算中的数据需要不断修正和更新,因此这些数据下发后可能导
致最终结果的错误,我们需要把这些错误数据进行修正,这就涉及到流计算中一个非常重要的概念——Retraction。
资源评论













