A Tutorial on Principal Component Analysis [2014]
需积分: 23 20 浏览量
2018-11-26
21:38:56
上传
评论
收藏 377KB PDF 举报


A Tutorial on Principal Component Analysis
Jonathon Shlens
∗
Google Research
Mountain View, CA 94043
(Dated: April 7, 2014; Version 3.02)
Principal component analysis (PCA) is a mainstay of modern data analysis - a black box that is widely used
but (sometimes) poorly understood. The goal of this paper is to dispel the magic behind this black box. This
manuscript focuses on building a solid intuition for how and why principal component analysis works. This
manuscript crystallizes this knowledge by deriving from simple intuitions, the mathematics behind PCA. This
tutorial does not shy away from explaining the ideas informally, nor does it shy away from the mathematics. The
hope is that by addressing both aspects, readers of all levels will be able to gain a better understanding of PCA as
well as the when, the how and the why of applying this technique.
I. INTRODUCTION
Principal component analysis (PCA) is a standard tool in mod-
ern data analysis - in diverse fields from neuroscience to com-
puter graphics - because it is a simple, non-parametric method
for extracting relevant information from confusing data sets.
With minimal effort PCA provides a roadmap for how to re-
duce a complex data set to a lower dimension to reveal the
sometimes hidden, simplified structures that often underlie it.
The goal of this tutorial is to provide both an intuitive feel for
PCA, and a thorough discussion of this topic. We will begin
with a simple example and provide an intuitive explanation
of the goal of PCA. We will continue by adding mathemati-
cal rigor to place it within the framework of linear algebra to
provide an explicit solution. We will see how and why PCA
is intimately related to the mathematical technique of singular
value decomposition (SVD). This understanding will lead us
to a prescription for how to apply PCA in the real world and an
appreciation for the underlying assumptions. My hope is that
a thorough understanding of PCA provides a foundation for
approaching the fields of machine learning and dimensional
reduction.
The discussion and explanations in this paper are informal in
the spirit of a tutorial. The goal of this paper is to educate.
Occasionally, rigorous mathematical proofs are necessary al-
though relegated to the Appendix. Although not as vital to the
tutorial, the proofs are presented for the adventurous reader
who desires a more complete understanding of the math. My
only assumption is that the reader has a working knowledge
of linear algebra. My goal is to provide a thorough discussion
by largely building on ideas from linear algebra and avoiding
challenging topics in statistics and optimization theory (but
see Discussion). Please feel free to contact me with any sug-
gestions, corrections or comments.
∗
Electronic address: jonathon.shlens@gmail.com
II. MOTIVATION: A TOY EXAMPLE
Here is the perspective: we are an experimenter. We are trying
to understand some phenomenon by measuring various quan-
tities (e.g. spectra, voltages, velocities, etc.) in our system.
Unfortunately, we can not figure out what is happening be-
cause the data appears clouded, unclear and even redundant.
This is not a trivial problem, but rather a fundamental obstacle
in empirical science. Examples abound from complex sys-
tems such as neuroscience, web indexing, meteorology and
oceanography - the number of variables to measure can be
unwieldy and at times even deceptive, because the underlying
relationships can often be quite simple.
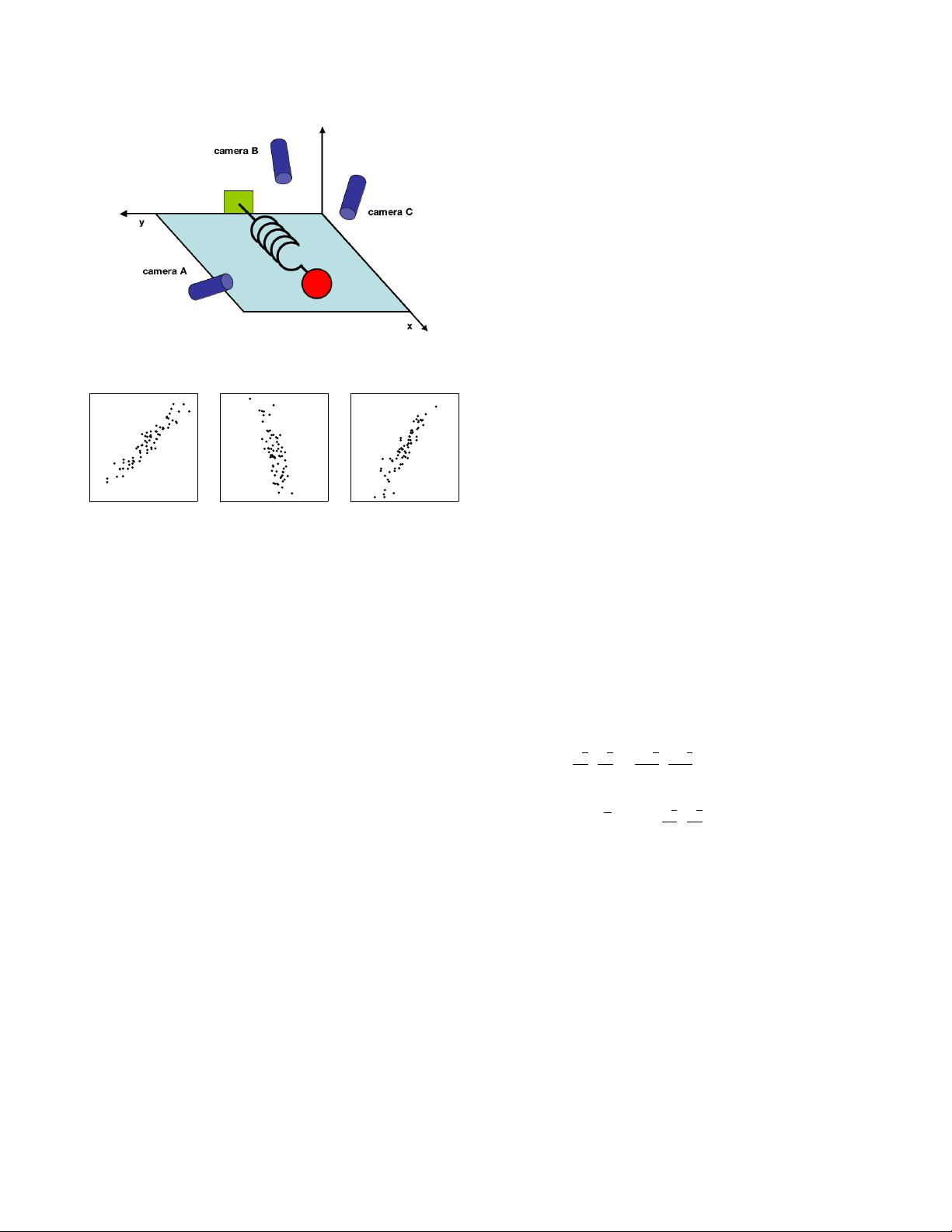
Take for example a simple toy problem from physics dia-
grammed in Figure 1. Pretend we are studying the motion
of the physicist’s ideal spring. This system consists of a ball
of mass m attached to a massless, frictionless spring. The ball
is released a small distance away from equilibrium (i.e. the
spring is stretched). Because the spring is ideal, it oscillates
indefinitely along the x-axis about its equilibrium at a set fre-
quency.
This is a standard problem in physics in which the motion
along the x direction is solved by an explicit function of time.
In other words, the underlying dynamics can be expressed as
a function of a single variable x.
However, being ignorant experimenters we do not know any
of this. We do not know which, let alone how many, axes
and dimensions are important to measure. Thus, we decide to
measure the ball’s position in a three-dimensional space (since
we live in a three dimensional world). Specifically, we place
three movie cameras around our system of interest. At 120 Hz
each movie camera records an image indicating a two dimen-
sional position of the ball (a projection). Unfortunately, be-
cause of our ignorance, we do not even know what are the real
x, y and z axes, so we choose three camera positions
~
a,
~
b and
~
c
at some arbitrary angles with respect to the system. The angles
between our measurements might not even be 90
o
! Now, we
record with the cameras for several minutes. The big question
remains: how do we get from this data set to a simple equation
arXiv:1404.1100v1 [cs.LG] 3 Apr 2014

剩余11页未读,继续阅读
资源评论













