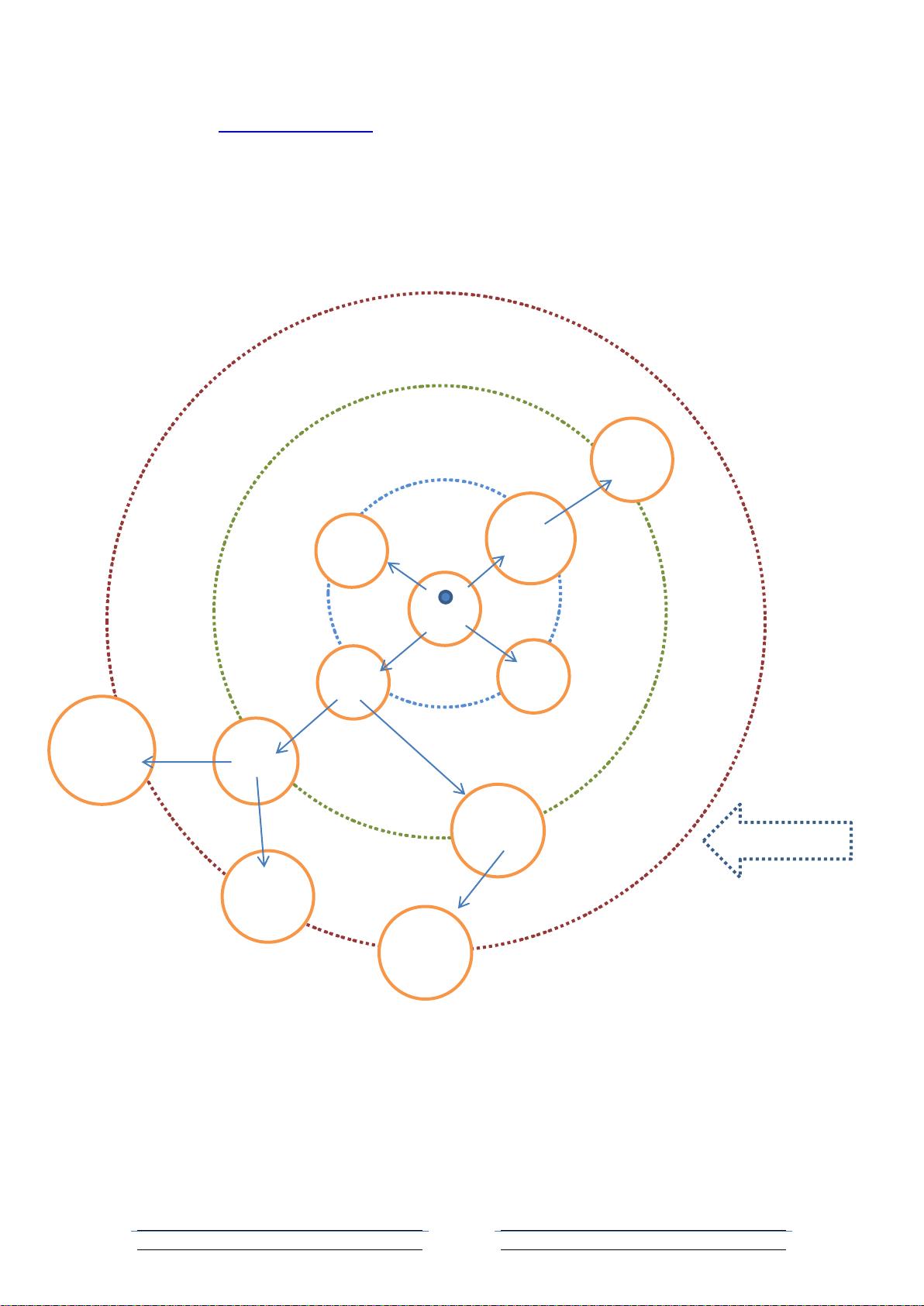
娱乐、电影→暴走大事件、Big 笑功坊、钢铁侠
所谓深度优先抓取;爬虫是按照深度递归的方式抓取网页,只要网页中还存在超链接,
那么爬虫会一直访问直到抓取到没有超链接的网页,再返回上一层次,如果返回的层次中存
在未抓取的网页,则对网页进行抓取,如果网页存在超链接,那么重复上述步骤直到抓取不
到链接。以上述图中网络拓扑为例,一种可能的抓取方式是:
导航→[优酷→(娱乐→暴走大事件→big 笑功坊)→(电影→钢铁侠)]→[淘宝]→[爱奇
艺→电视剧]→[迅雷]
[注:上面式子中不同括号代表不同层次,相同符号代表相同层次]
对于深度优先和广度优先,可结合数据结构中图的遍历方式进行理解消化。
构建网络爬虫的主要目的在于获取我们感兴趣的信息,下面我们采用建立一个小型的链
接数据文本(一般我们采用数据库,但这里简单起见只把信息保存到文本文件)为例,写一
个小型的爬虫脚本。由于 python 语言具有便捷,语法简单,移植性强,轻量的特点,考虑
采用 python 语言。
构建爬虫,建立小型网站链接文本标记网
站名字与 URL 信息;例如:
优酷网 www.youku.com
Python 的 环 境 搭 建 很 简 单 , windows 平 台 直 接 在
https://www.python.org/download/releases/2.7.6/
下载安装即可, python 集成了 IDLE 开发环境,便于我们编写功能模块,当然目前还有很多
很不错的集成化开发环境像 eclipse 等,但我觉得有 IDLE 这个工具足矣。下面我将用 IDLE 的
方式开发本功能模块。
开发步骤:
(1) 打开 IDLE:
Window 按钮→所有程序→python 2.7.6→ IDLE(python GUI)
(2) 新建 python 文件:File→new windows(或者 new file)
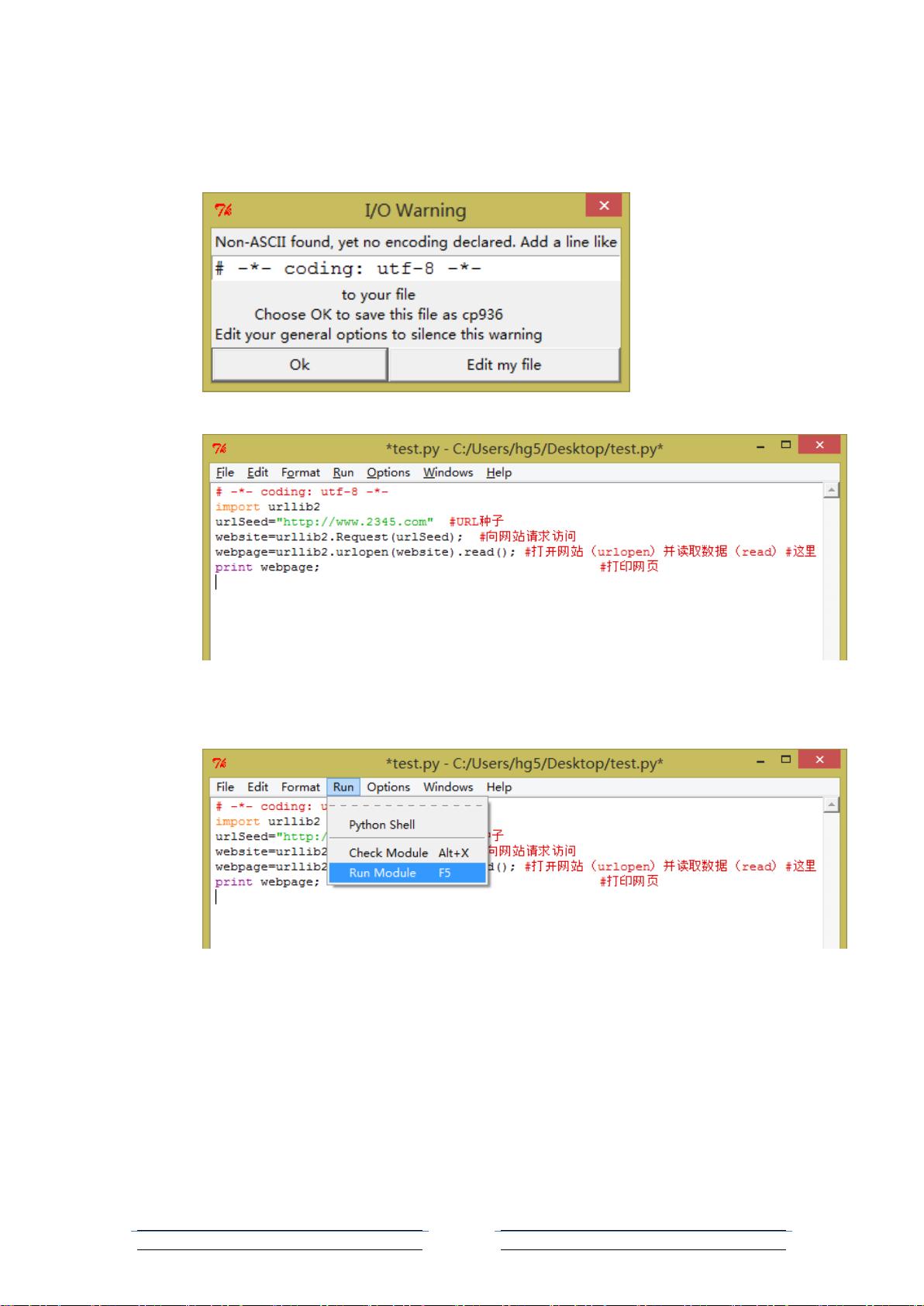
(3)python 内置 urllib2 模块已经能够满足我们抓取网页地需要,在新文件中中输入以下代
码,代码相对简单:
[注意:“#”后面的内容为注释,不熟悉 python 的同学注意了]
import urllib2
urlSeed="http://www.2345.com" #URL 种子
website=urllib2.Request(urlSeed); #向网站请求访问
webpage=urllib2.urlopen(website).read(); #打开网站(urlopen)并读取数据(read)