分词系统研究完整版(ICTCLAS)


分词系统研究完整版
分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统,
难能可贵的是该版的 版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是,该源代码没有配套的文档,阅读起来可能有一定的障碍,尤其是对
不熟的人来说本人就一直用 作为主要的开发语言上大学时倒是学过
不过工作之后一直没有再使用过语法什么的忘的几乎一干二净了但语言这东西基本的东西都
相通的况且 也是在 的基础上形成的有一定的相似处阅读一遍源代码主要的语法
都应该不成问题了
虽然在 的系统中没有完整的文档说明但是我们可以通过查阅张华平和刘群发表的
一些相关论文资料还是可以窥探出主要的思路
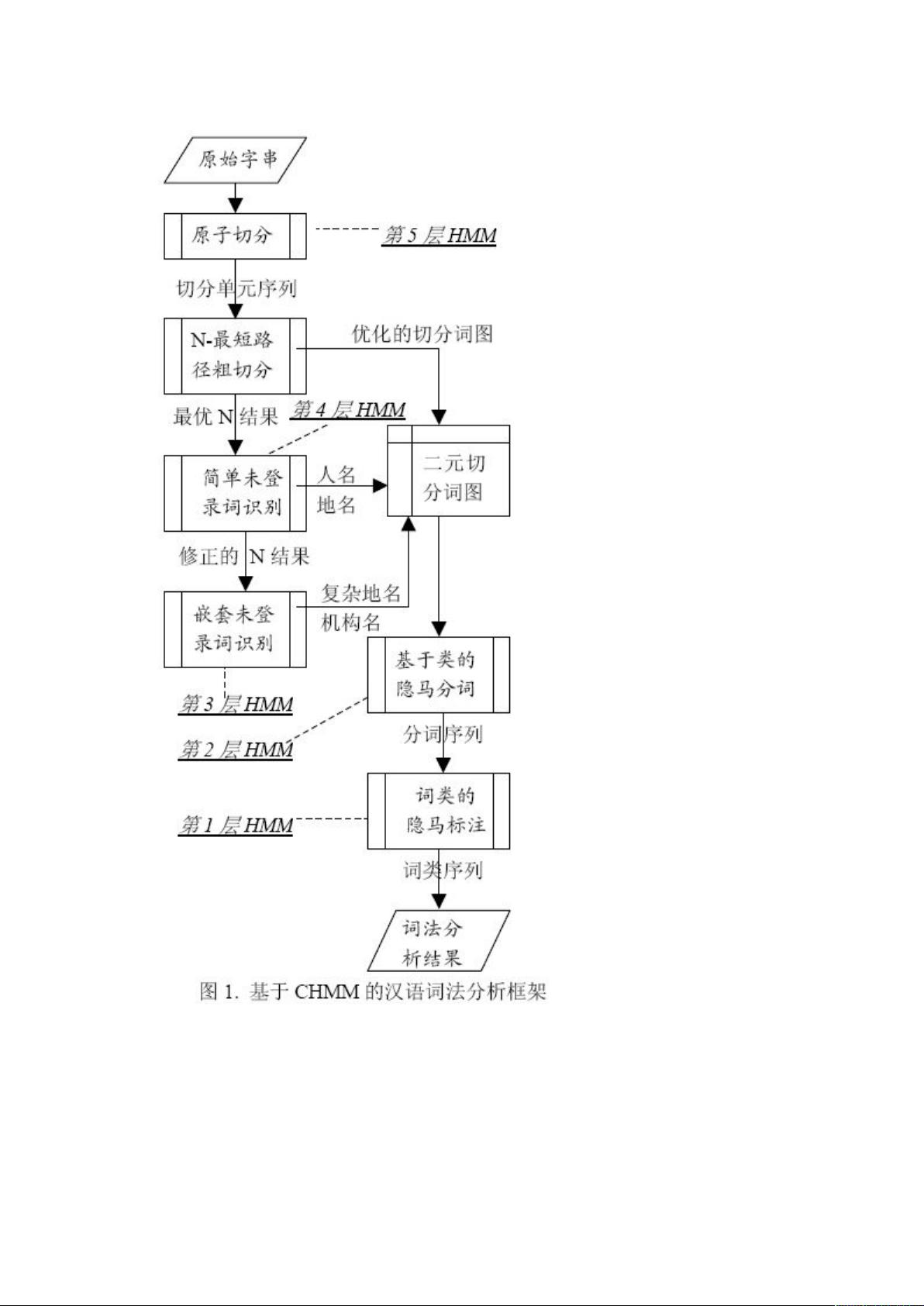
该分词系统的主要是思想是先通过 层叠形马尔可夫模型进行分词通过分层既增加
了分词的准确性又保证了分词的效率共分五层如下图一所示



剩余43页未读,继续阅读
资源评论

 new_chiokchi2011-11-04还好了,内容丰富,但是没整理一下
new_chiokchi2011-11-04还好了,内容丰富,但是没整理一下













