《DAVID数据库使用教程》是一份详尽的指导材料,主要针对那些希望深入了解和有效利用DAVID(Database for Annotation, Visualization and Integrated Discovery)数据库的用户。DAVID数据库是一个功能强大的生物信息学工具,主要用于基因功能注释、富集分析以及基因集合的可视化。在本教程中,我们将探讨如何充分利用这个数据库进行数据解析和生物学研究。
DAVID数据库的核心功能包括基因功能注释和富集分析。功能注释是将基因与已知的生物学功能联系起来,例如基因的功能描述、参与的通路、表达模式等。这有助于研究人员理解基因在细胞或生物体中的作用。富集分析则是对一组基因进行统计测试,确定哪些功能类别或通路在该组中显著过表达,这是探究基因集合共性的重要手段。
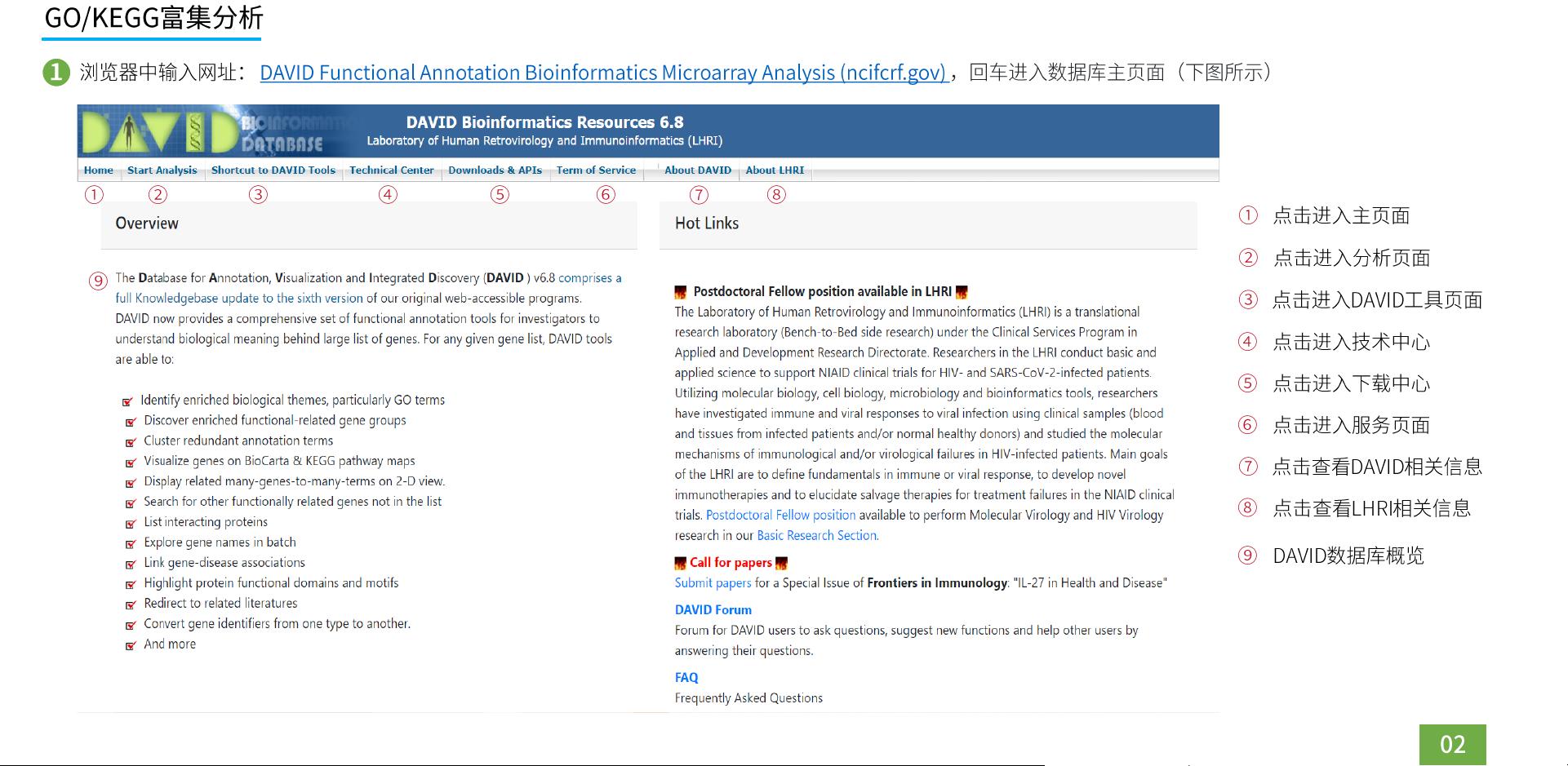
使用DAVID数据库的第一步是输入基因列表。你可以导入CSV或TXT文件,包含你感兴趣的基因标识符,如Entrez Gene ID、Ensembl ID等。导入后,系统会自动进行匹配和转换,确保与数据库中的信息一致。
接下来,DAVID将进行功能分类和富集分析。它会将基因分组到生物学相关的功能类别下,如KEGG通路、GO(Gene Ontology)术语等,并计算每个类别的富集统计值,如P值和富集因子。P值用于衡量结果的显著性,富集因子则反映了特定功能在输入基因集合中比在整个基因组中更为常见的程度。
DAVID还提供了一种强大的可视化工具,帮助用户直观地理解分析结果。例如,富集图可以显示每个功能类别的大小、富集度和统计显著性。此外,网络图能展示基因间的相互关系,帮助识别关键基因和模块。
在进一步分析时,DAVID的“Functional Annotation Clustering”功能将相似的注释组合成簇,便于识别核心主题和相关性。每个簇都有一个富集得分,表示其内部注释的相关性,这有助于缩小关注范围,深入研究关键生物学过程。
DAVID提供了报告生成和下载功能,方便用户保存和分享分析结果。报告包含了所有关键的统计信息、图表和注释,为后续的文献检索和假设生成提供基础。
DAVID数据库是生物学家研究基因功能和通路分析的重要工具。通过掌握其使用方法,科研人员可以更高效地解读高通量实验数据,揭示基因组中的隐藏模式和生物学意义。在实际工作中,结合其他生物信息学工具和实验验证,DAVID可以帮助推动我们对生命科学的理解不断深化。