【Apache Flink 在国有大型银行智能运营场景的应用】
Apache Flink 是一款开源的流处理框架,因其高效、实时和容错能力强的特点,在大数据处理领域得到了广泛应用。在国有大型银行的智能运营场景中,Flink 展现了其强大的功能,帮助银行解决了数据处理和流程分析的诸多挑战。
1. **公司介绍**
建信金科是中国建设银行的金融科技子公司,致力于运用包括Flink在内的先进技术,如人工智能、区块链、云计算、大数据等,推动银行的数字化转型。公司不仅提供金融科技解决方案,还在智慧金融、智慧政务、智慧出行等多个领域实施金融科技能力,旨在提升服务质量和效率,赋能“数字中国”建设。
2. **业务背景与挑战**
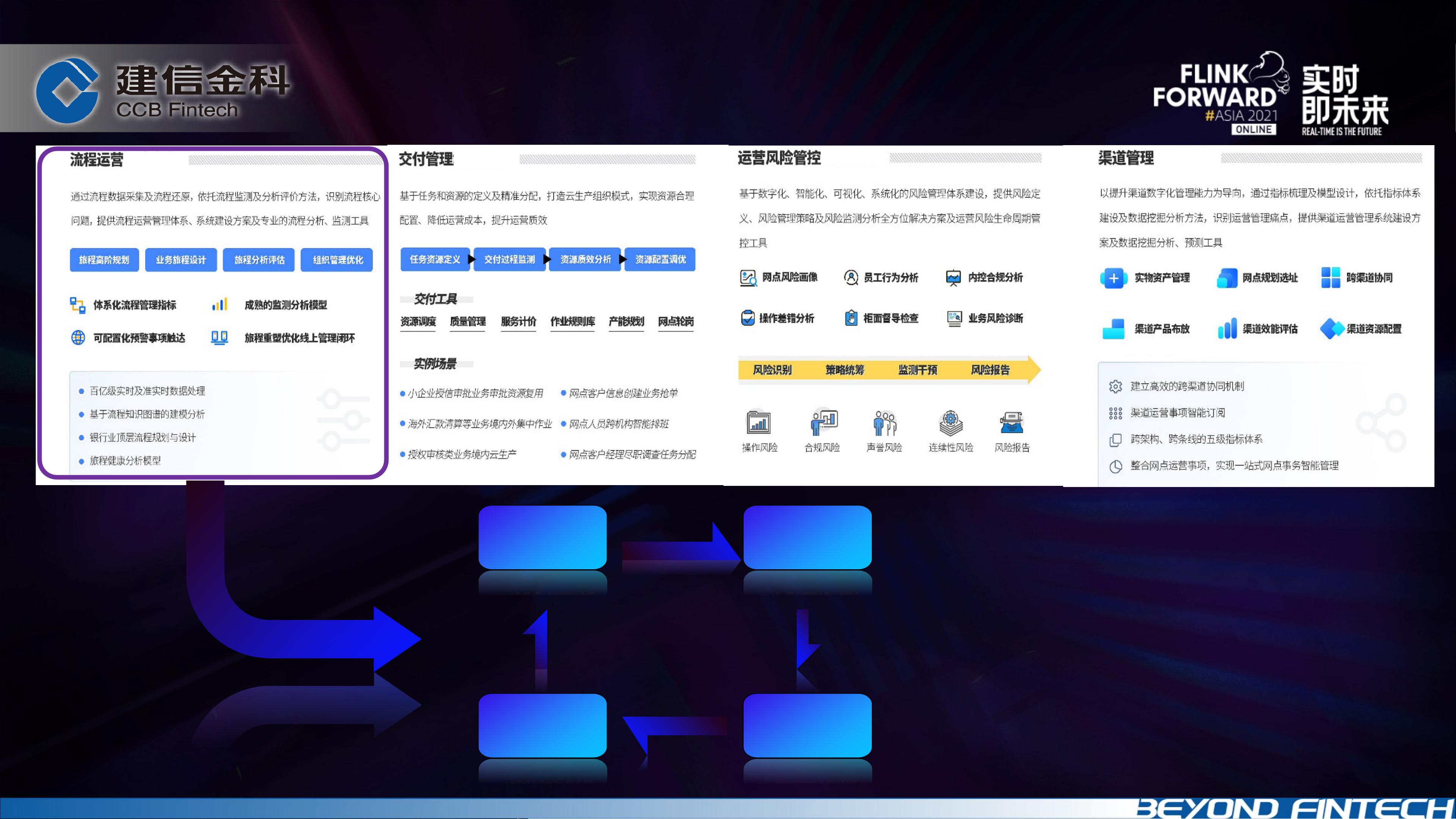
银行业务流程复杂,如信用卡申请涉及多个步骤,需要全局视角的流程管理和监控。以往,由于数据来源分散,存在数据孤岛问题,且业务需求强调高灵活性和实时性。为解决这些问题,银行需要一个通用、可配置的流程应用,能够实现实时数据处理和流程监控。
3. **方案演进**
- **流程分析**:每个业务动作对应三个日志流,通过跟踪号进行JOIN连接。初期使用keyedProcessFunction和滑动窗口,但随着数据量增加,Redis的吞吐量限制和运维复杂性暴露出来。
- **多流Join优化**:Flink的Interval Join引入,使用RocksDB自动管理中间状态,解决了Redis的性能瓶颈,减少了运维复杂性和状态积压问题。这使得Flink可以更高效地处理延迟到达的数据。
4. **业务效果**
- 通过参数化配置,实现了流程站点的灵活定义和实时监控,提升了服务满意度和流程效率。
- 使用Kafka消息队列进行数据采集,保证业务系统与分析系统的解耦,确保数据实时处理。
- 利用Flink的批流一体能力,结合Rocksdb和Kafka等组件,构建了一套稳定、高效的数据处理架构。
5. **架构流程**
- 数据源来自多个渠道,包括日志埋点、CDC报文等,通过Logstash进行数据清洗,然后进入Kafka消息队列。
- Flink作为实时处理引擎,对数据进行实时加工,并与维表进行关联,计算指标。
- 结果存储在Hbase、GreenPlum等数据库,用于BI分析和监控告警。
6. **总结**
Apache Flink 在国有大型银行的智能运营中发挥了关键作用,通过优化的多流JOIN策略和实时处理能力,实现了业务流程的可视化和监控,提高了服务质量和效率。这一实践证明了Flink在复杂业务环境下的强大适应性和实用性,为金融机构的数字化转型提供了有力的技术支持。