
Linux 中使用 eclipse 编译运行 hadoop-0.20.1 源码
Linux 中使用 Eclipse 编译运行 Hadoop-0.20.1 源码
说明:在 hadoop 伪分布式模式下,编译运行 hadoop 的
源码,在集群中运行。
(0)确保 Eclipse 的 JDK、JRE 是 1.6 以上(包含 1.6)。
(1)下载 hadoop-0.20.1,并解压,配置为伪分布式模式。
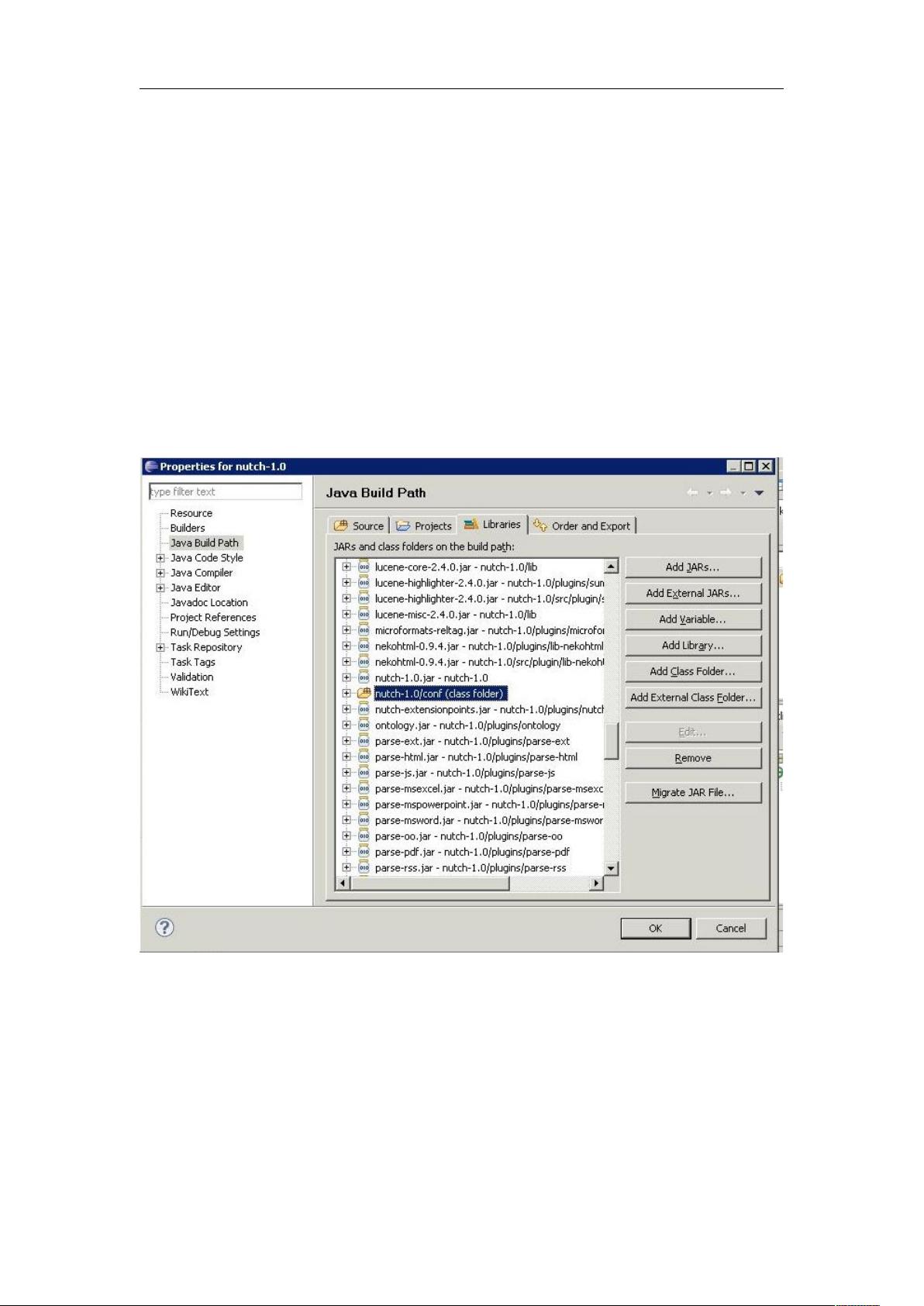
(2)在 eclipse 中新建一个 Java Project,名字自己定义(hadoop-0.20.1),选
择"Create project from existing source",选择 hadoop-0.20.1 目录。
下一步,切换到"Libraries",选择"Add Class Folder..." 按钮,从列
表中选择"conf";
切换到"Order and Export"找到"conf",点击 top 把它移到顶端;
1













- 1
- 2
前往页