中文分词系统的设计与实现
一、 设计目标
本题要求设计和实现一个中文分词系统,将任意给定的一段中文切分成一个
一个单独的词。按所推荐的参考算法和数据结构通过编程实现系统,使学生进一
步强化 C 语言程序设计能力,掌握动态存储分配、文件读写等高级编程,掌握
Hash 表、Trie 树等数据结构的使用方法,提高综合运用各门课程知识解决实际
问题的能力。
二、 设计要求
中文分词是将一段中文的字序列切分成词序列的过程。比如,“我是一名大
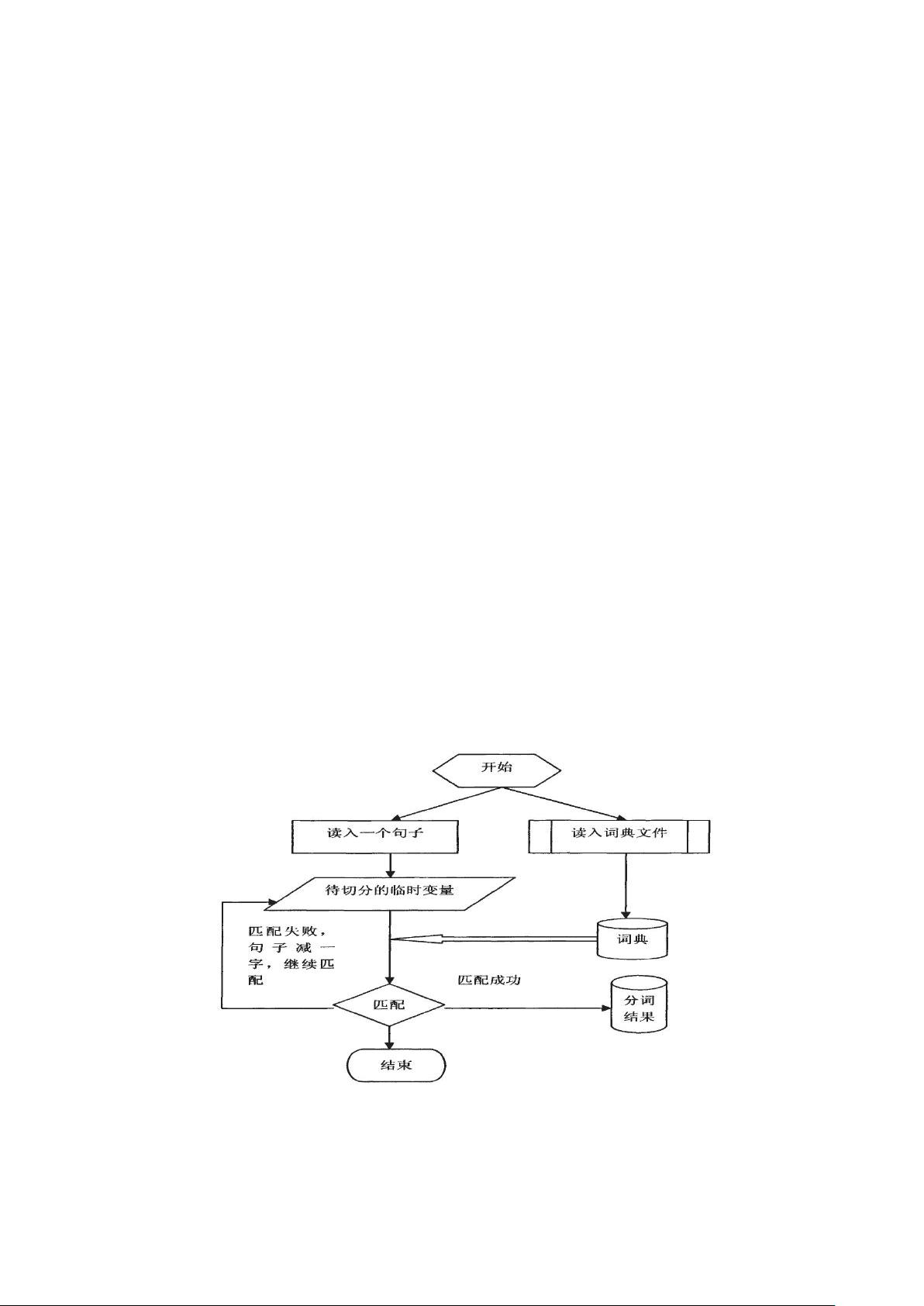
学生”切分的结果为“我|是|一名|大学生”。中文分词系统所采用的算法较多,
一种基本的分词算法为基于字符串匹配的分词方法,这种方法需要用到词典。分
词过程中需要频繁地对词典进行查找和匹配,为了提高分词速度,需要使用特殊
的数据结构对词典进行索引和存储。
本系统需实现以下基本功能:
1. 词典维护功能:可从文件导入词典,对词典进行增加、删除和修改,将
维护好的词典保存到文件,数据存放的格式可以自定义。
2. 索引维护功能:为了提高词典的查找和比对速度,需要对词典建立各种
索引。因此,当词典发生变化后,索引需相应更新。系统启动后,索引被加载到
内存,索引更新后,应采用合适的数据存放格式将索引存到硬盘,以便下次启动
系统时,被加载的索引与系统上次运行时的索引完全一致。
3. 待处理中文文本的输入:待处理中文文本可以有多个段落,每个段落可
以有多个句子,每个句子字数不限,还可以带各种标点符号。待处理中文文本可
以通过键盘输入,也可以从文本文件导入。
4. 对输入的中文文本进行分词处理:分割后的词两两之间用“|”分隔,保
持原文次序。提供保存到文本文件的功能。
5. 用户界面功能:系统需要有良好的用户界面,方便操作。用户界面可以
采用简单文本菜单界面、下拉式文本菜单界面和图形菜单界面。
在实现上述功能基础上,如果系统还能正确切分中文文本中的英文单词、各
种数字,则可以酌情给予附加分奖励。
三、 参考算法
为了充分发挥大家的编程能力,题目对系统实现所采用的算法和数据结构没
有限定,也就是说,只要分词结果足够准确、切分速度足够快,任何算法和数据