

Dapper,大规模分布式系统的跟踪系统
转载:http://bigbully.github.io/Dapper-translation/
作者:Benjamin H. Sigelman, Luiz Andr´e Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald
Beaver, Saul Jaspan, Chandan Shanbhag
概述
当 代的互联网的服务,通常都是用复杂的、大规模分布式集群来实现的。互联网应用构建在不同的
软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使 用不同的编程语言来实现、有
可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、
用于分析性能问题的工具。
Dapper-- Google 生产环境下的分布式跟踪系统,应运而生。那么我们就来介绍一个大规模集群的跟
踪系统,它是如何满足一个低损耗、应用透明的、大范围部署这三个 需求的。当然 Dapper 设计之
初,参考了一些其他分布式系统的理念,尤其是 Magpie 和 X-Trace,但是我们之所以能成功应用在生
产环境上,还需 要一些画龙点睛之笔,例如采样率的使用以及把代码植入限制在一小部分公共库的
改造上。
自从 Dapper 发展成为一流的监控系统之后,给其他应用的开发者和运维团队帮了大忙,所以我们今
天才发表这篇论文,来汇报一下这两年 来,Dapper 是怎么构建和部署的。Dapper 最初只是作为一
个自给自足的监控工具起步的,但最终进化成一个监控平台,这个监控平台促生出多种多样的 监控
工具,有些甚至已经不是由 Dapper 团队开发的了。下面我们会介绍一些使用 Dapper 搭建的分析工
具,分享一下这些工具在 google 内部使用的 统计数据,展现一些使用场景,最后会讨论一下我们迄
今为止从 Dapper 收获了些什么。
1. 介绍
我 们开发 Dapper 是为了收集更多的复杂分布式系统的行为信息,然后呈现给 Google 的开发者们。
这样的分布式系统有一个特殊的好处,因为那些大规模的 低端服务器,作为互联网服务的载体,是
一个特殊的经济划算的平台。想要在这个上下文中理解分布式系统的行为,就需要监控那些横跨了
不同的应用、不同的服务 器之间的关联动作。
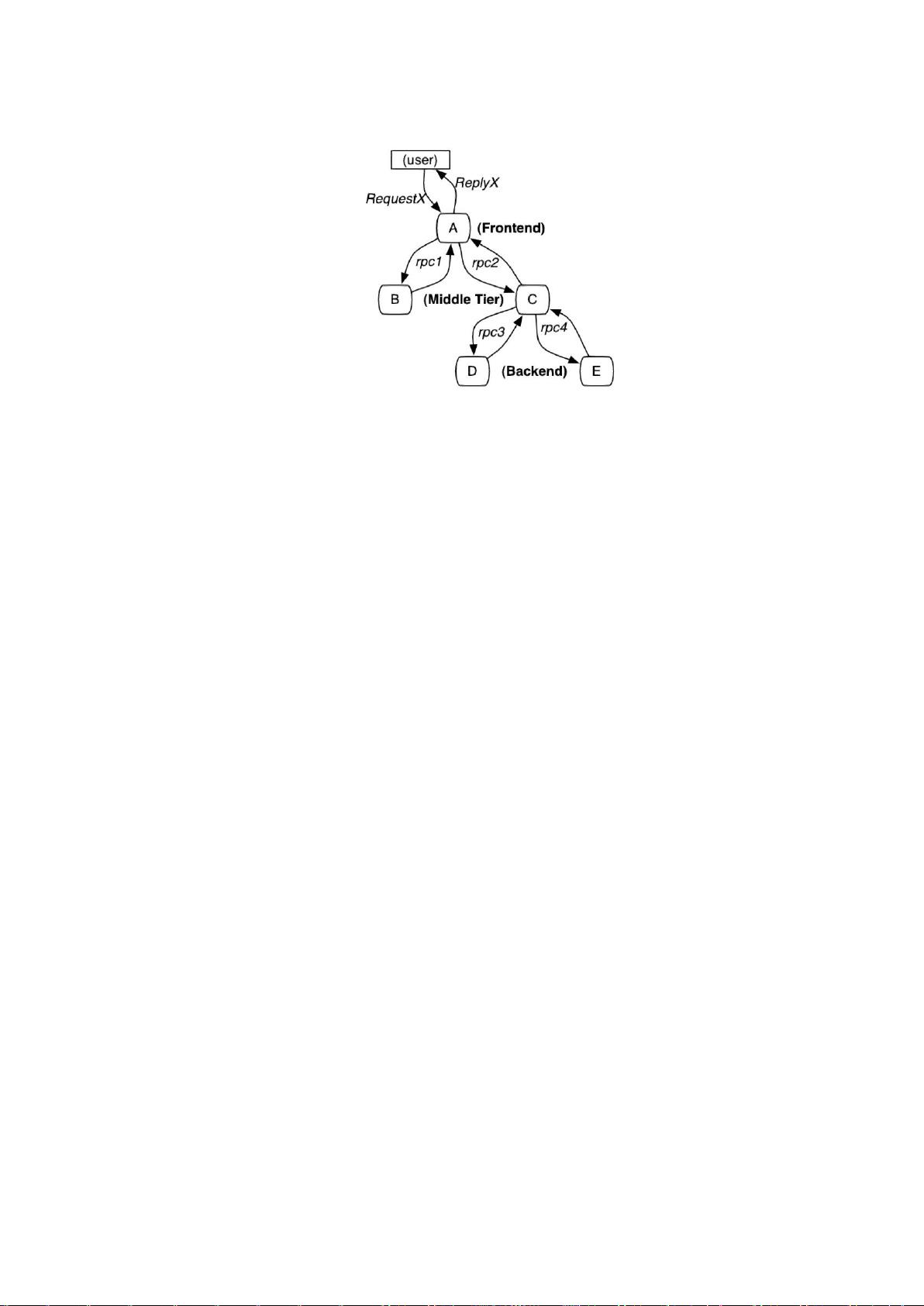
下 面举一个跟搜索相关的例子,这个例子阐述了 Dapper 可以应对哪些挑战。比如一个前段服务可
能对上百台查询服务器发起了一个 Web 查询,每一个查询都有 自己的 Index。这个查询可能会被发
送到多个的子系统,这些子系统分别用来处理广告、进行拼写检查或是查找一些像图片、视频或新
闻这样的特殊结果。根据 每个子系统的查询结果进行筛选,得到最终结果,最后汇总到页面上。我
们把这种搜索模型称为“全局搜索”(universal search)。总的来说,这一次全局搜索有可能调用上千台
服务器,涉及各种服务。而且,用户对搜索的耗时是很敏感的,而任何一个子系统的低效都导致导
致 最终的搜索耗时。如果一个工程师只能知道这个查询耗时不正常,但是他无从知晓这个问题到底
是由哪个服务调用造成的,或者为什么这个调用性能差强人意。首 先,这个工程师可能无法准确的
定位到这次全局搜索是调用了哪些服务,因为新的服务、乃至服务上的某个片段,都有可能在任何
时间上过线或修改过,有可能是面 向用户功能,也有可能是一些例如针对性能或安全认证方面的功
能改进。其次,你不能苛求这个工程师对所有参与这次全局搜索的服务都了如指掌,每一个服务都
有 可能是由不同的团队开发或维护的。再次,这些暴露出来的服务或服务器有可能同时还被其他客
户端使用着,所以这次全局搜索的性能问题甚至有可能是由其他应用 造成的。举个例子,一个后台
服务可能要应付各种各样的请求类型,而一个使用效率很高的存储系统,比如 Bigtable,有可能正被
反复读写着,因为上面跑 着各种各样的应用。
上 面这个案例中我们可以看到,对 Dapper 我们只有两点要求:无所不在的部署,持续的监控。无
所不在的重要性不言而喻,因为在使用跟踪系统的进行监控时, 即便只有一小部分没被监控到,那

剩余15页未读,继续阅读






评论2
最新资源