

LDA 文本模型讲义
0. 背景
在 Machine Learning 中,LDA 是两个常用模型的简称:Linear Discriminant Analysis
和 Latent Dirichlet Allocation。这次主题讲的是后者。LDA 是一个在文本建模中很著名
的模型,类似于 SVD、PLSA 等模型,可以用于浅层语义分析,在文本语义分析中是一个很有
用的模型。这个模型涉及到的数学知识包括:Gamma 函数、Dirichlet 分布、Dirichlet-
Multinomial 共轭、gibbs Sampling、贝叶斯文本建模、PLSA 以及 LDA。
1. LDA 的作用
传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如 TF-IDF
等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没
有,但两个文档是相似的。
例如,有两个句子分别如下:
“乔布斯离我们而去了。”
“苹果价格会不会降?”
可以看到上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的
方法判断这两个句子肯定不相似,所以在判断文档相关性的时候需要考虑到文档的语义,而
语义挖掘的利器是主题模型,LDA 就是其中一种比较有效的模型。
在主题模型中,主题表示一个概念、一个方面,表现为一系列相关的单词,是这些单词
的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单词,这些单词与这个
主题有很强的相关性。
主题模型要解决的问题:怎样才能生成主题?对文章的主题应该怎么分析?
2. LDA 模型
2.1 基础知识
Gamma 函数
函数形式
函数性质:
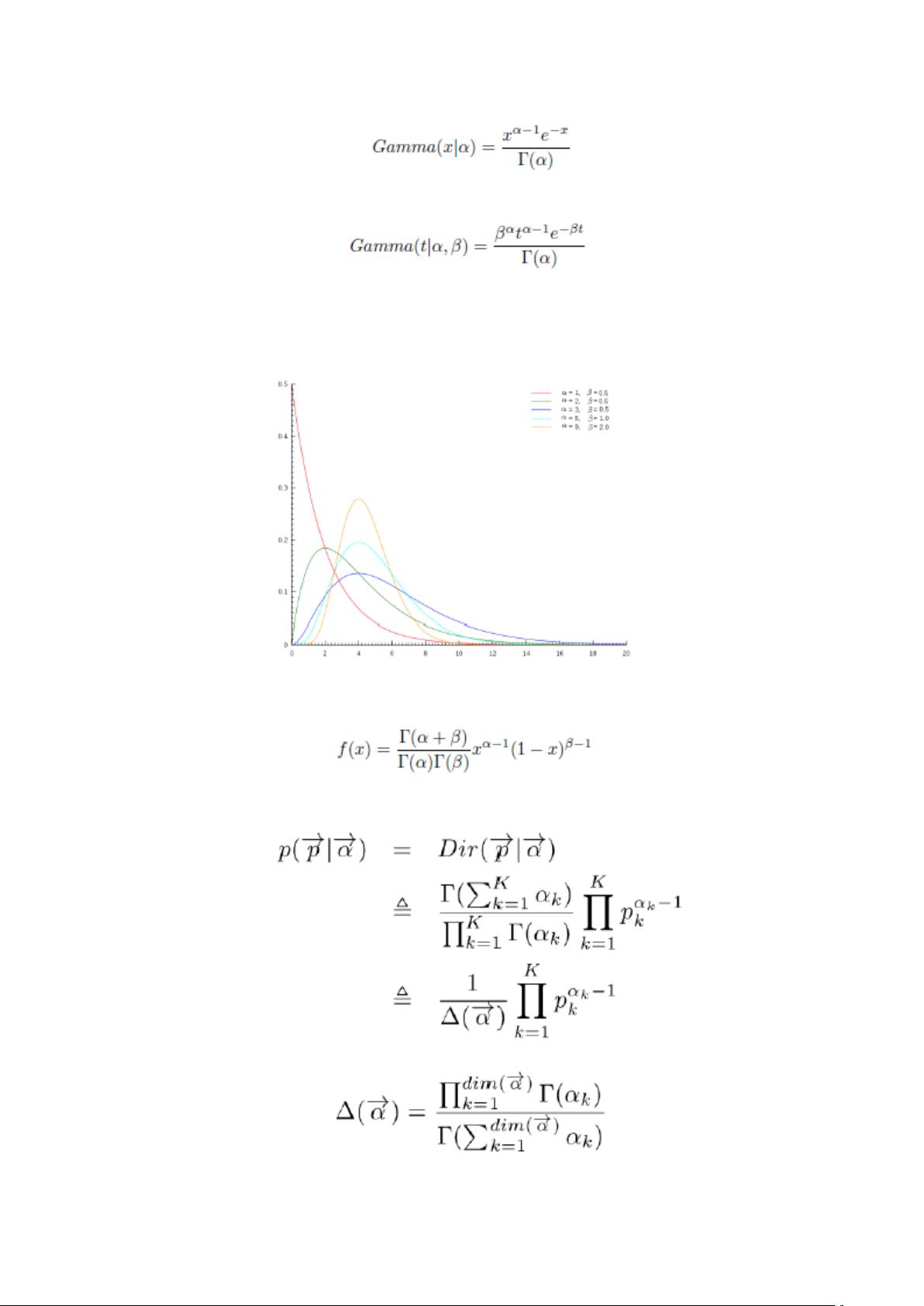
Gamma 分布
对 Gamma 函数进行变换,得到如下形式
取积分中的函数作为概率密度,得到一个形式简单的 Gamma 分布的密度函数:
剩余12页未读,继续阅读
资源评论













