


Python爬虫爬虫_城市公交、地铁站点和线路数据采集实例城市公交、地铁站点和线路数据采集实例
城市公交、地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构、路网规划、公交选址等。但是,这类数据往往掌握在特定部门中,
很难获取。互联网地图上有大量的信息,包含公交、地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集。闲言少叙,接下来将详细介绍如何
使用Python爬虫爬取城市公交、地铁站点和数据。
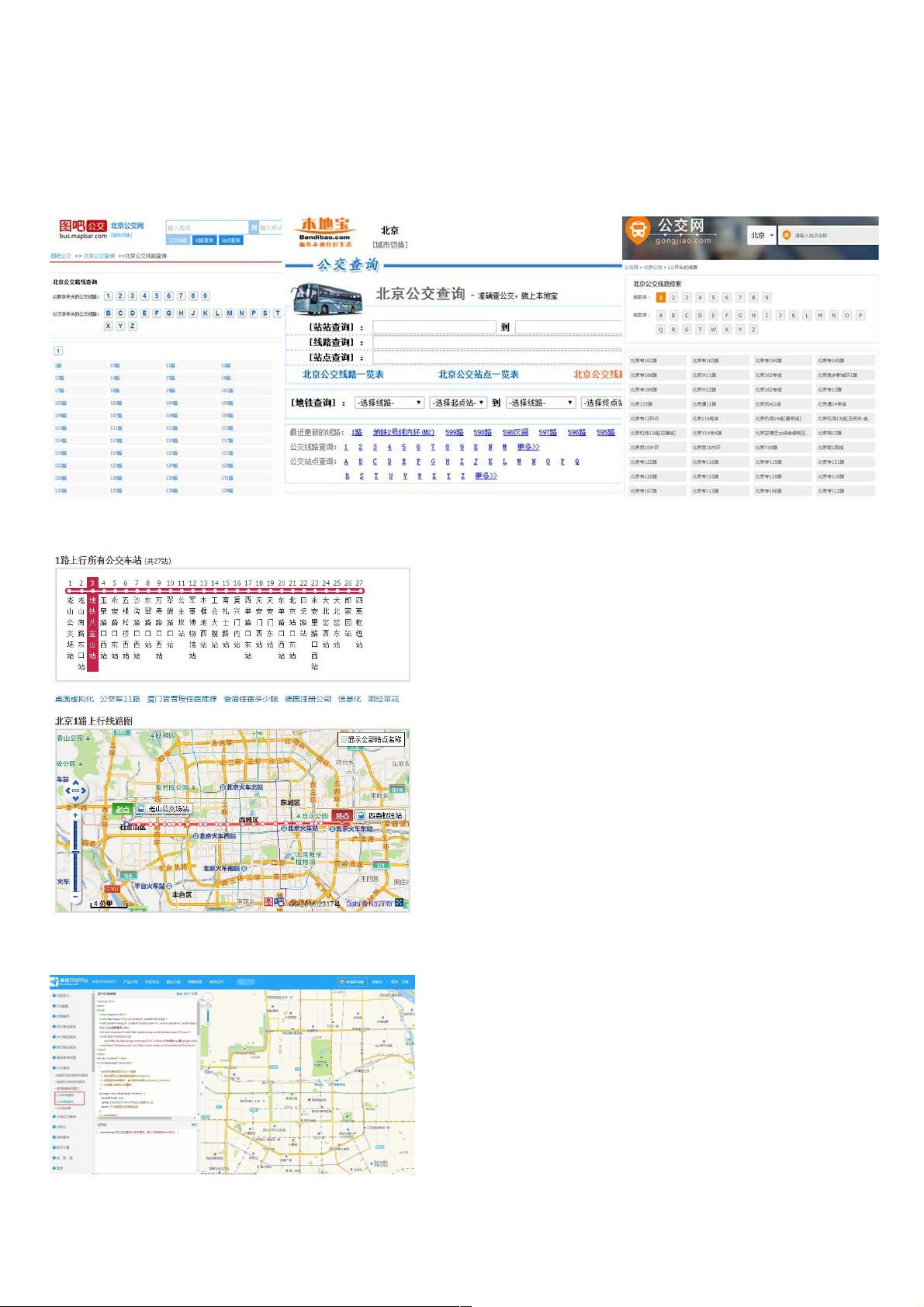
首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线。可以通过图吧公交、公交网、8684、本地宝等网站获取,该类网站提供了按数
字和字母划分类别的公交线路名称。Python写个简单的爬虫就能采集,可参看WenWu_Both的文章的文章,博主详细介绍了如何利用python爬取8684上某城
市所有的公交站点数据。该博主采集了站点详细的信息,包括,但是缺少了公交站点的坐标、公交线路坐标数据。这就让人抓狂了,没有空间坐标怎么
落图,怎么分析,所以,本文重点介绍的是站点坐标、线路的获取。
以图吧公交为例,点击某一公交后,出现该路公交的详细站点信息和地图信息。博主顿感兴奋,觉得马上就要成功了,各种抓包,发现并不能解析。可
能博主技术所限,如有大神能从中抓到站点和线路的坐标信息,请不宁赐教。这TM就让人绝望了啊,到嘴的肥肉吃不了。
天无绝人之路,尝试找找某地图的API,发现可以调用,通过解析,能够找到该数据的后台地址。熟悉前端的可以试试,博主前端也就只会个hello
world,不献丑了。这是一种思路,实践证明是可以的。
地图API可以,那么通过地图抓包呢?打开某图主页,直接输入某市公交名称,通过抓包,成功找到站点和线路信息。具体抓包信息如下图所
示,busline_list中详细列出了站点和线路的信息,其中有两条,是同一趟公交不同方向的数据,略有差别,需注意。找到入口过后,接下来爬虫就要大
显身手了。













