《C-Minus词法分析和语法分析设计编译器编译原理课程设计报告》
编译器是将高级编程语言转换为机器可执行代码的重要工具,其核心组成部分包括词法分析器和语法分析器。本报告主要围绕C-Minus语言的词法分析和语法分析进行设计,以实现一个简单的C-编译器。
1. **课程设计目标**
实验旨在构建一个C-Minus编译器,该编译器仅包含扫描程序(scanner)和语法分析(parser)两部分,用于理解并解析C-Minus语言的基本元素。
2. **分析与设计**
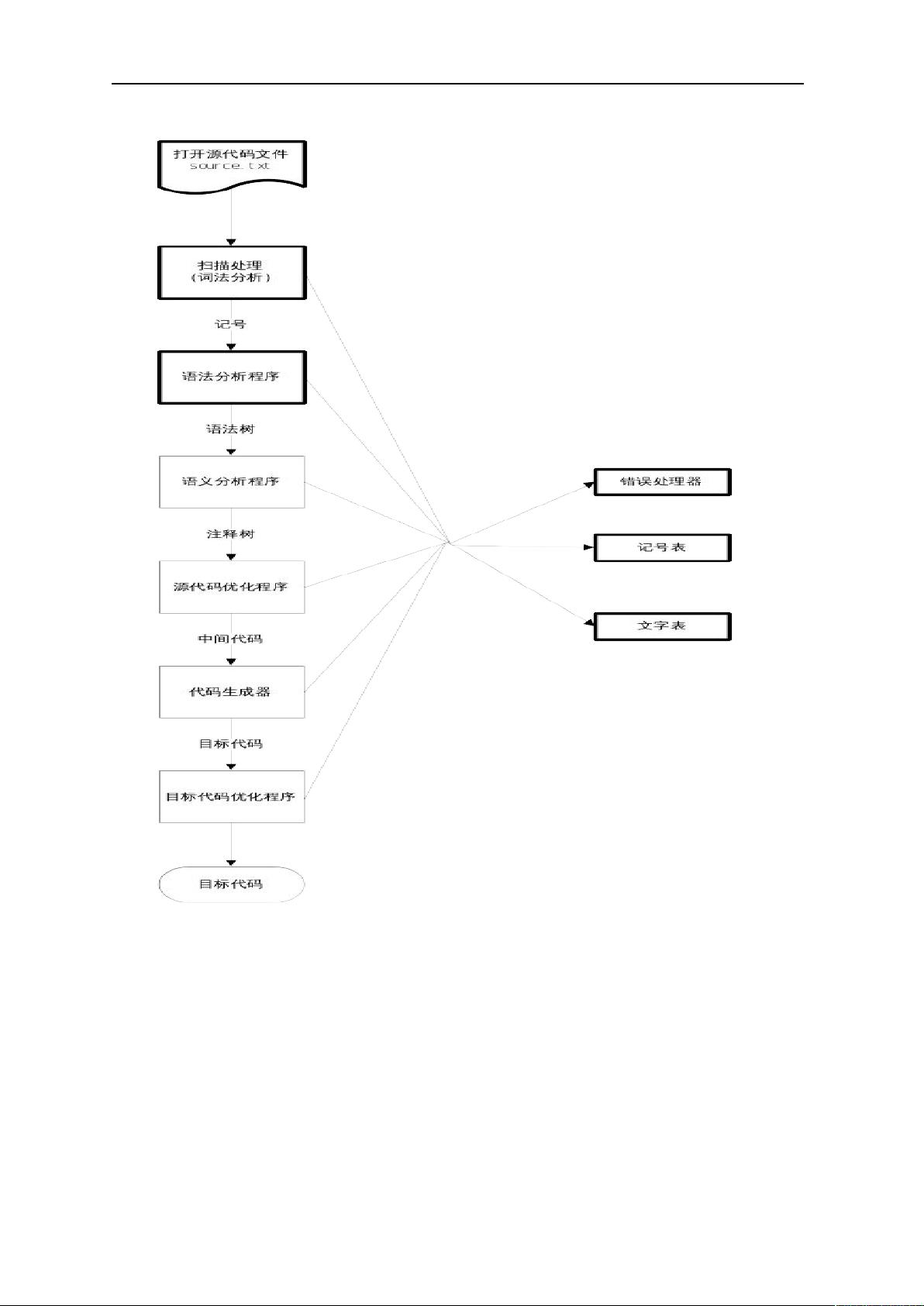
C-编译器的整体框架由词法分析和语法分析两部分构成。词法分析负责识别输入源代码中的各种符号,如关键字、操作符、标识符、数字以及注释等;语法分析则依据语法规则解析这些符号,形成抽象语法树(AST),以便后续生成目标代码。
3. **词法分析(Scanner)**
- **设计思想**:采用确定有限自动机(DFA)模型,通过switch-case结构实现状态转换。
- **关键词与符号**:C-Minus包含特定的关键字(如else, if, int, return, void, while等)和专用符号(如+,-,*,/,<,<=,>,>=,==,!=,=等)。
- **标识符与数字**:标识符由字母开头,后跟零个或多个字母或数字;数字由数字组成。
- **空格与注释**:空格用于分隔标识符和数字,但会被忽略;注释以/*开始,以*/结束,可出现在任意空白位置,不支持嵌套。
4. **程序流程**
当DFA到达接受状态时,表示识别出一个单词。初始状态设为START,读取字符并根据DFA进行状态转换。例如,遇到'/'时,状态转为SLASH,再遇到'*'则进入INCOMMENT状态,表示注释开始。注释结束后,状态转回正常处理。
5. **文件与函数设计**
词法分析程序包括`scanner.h`和`scanner.cpp`两个文件:
- `scanner.h`:声明词法状态枚举(如START, INNUM, INID, INDBSYM, DONE)和Token类型枚举,包括关键字、操作符、标识符、数字、注释等,以及Token结构体,存储类型、字符串和行号。
- `scanner.cpp`:实现词法分析的具体逻辑,如状态转换和Token的生成。
6. **词法分析过程**
词法分析器遍历输入源代码,根据DFA状态逐字符处理。当遇到特殊字符,如'/',会根据后续字符判断是否为注释。一旦识别出一个完整单词,就创建相应的Token对象并输出。
7. **语法分析(Parser)**
语法分析器根据C-Minus的语法规则,将词法分析产生的Token序列转化为抽象语法树。这部分通常采用递归下降解析或LALR解析技术,但对于本设计报告,具体实现未详细展开。
8. **结论**
通过本次课程设计,我们能够深入理解编译器的工作原理,掌握词法分析和语法分析的基本方法,并具备了实现一个简单编译器的能力。这不仅巩固了编译原理的理论知识,也为将来可能涉及的软件开发工作打下了坚实的基础。
在实际的编译器设计中,词法分析和语法分析是至关重要的步骤,它们的成功与否直接影响到整个编译过程的效率和结果的准确性。本报告提供了一个基本的C-Minus编译器设计思路,对于学习编译原理和实践编译器开发具有指导意义。















评论1
最新资源