1 INTRODUCTION
Recent work has shown that presenting explicit reasoning steps (i.e., chains of thought; COT) in En-
glish elicits multi-step reasoning abilities of large language models such as GPT-3 and PaLM (Brown
et al., 2020; Chowdhery et al., 2022; Wei et al., 2022b, inter alia). Pretrained multilingual language
models have also achieved impressive performance on various NLP tasks across typologically distinct
languages (Conneau et al., 2020; Xue et al., 2021; Chowdhery et al., 2022; Clark et al., 2020; Hu
et al., 2020; Ruder et al., 2021, inter alia). Tasks in existing multilingual benchmarks usually require
only simple reasoning steps, and so it is still unclear how well language models perform on tasks that
require more complex reasoning in a multilingual setting.
In this work, we introduce the
MGSM
benchmark to bridge the gap between the progress on English-
based chain-of-thought reasoning and multilingual NLP. We extend a subset of the English-language
GSM8K dataset (Cobbe et al., 2021) to ten typologically diverse languages via manual translation of
problems into target languages. To the best of our knowledge, this is the first multilingual benchmark
to evaluate the arithmetic reasoning abilities of language models.
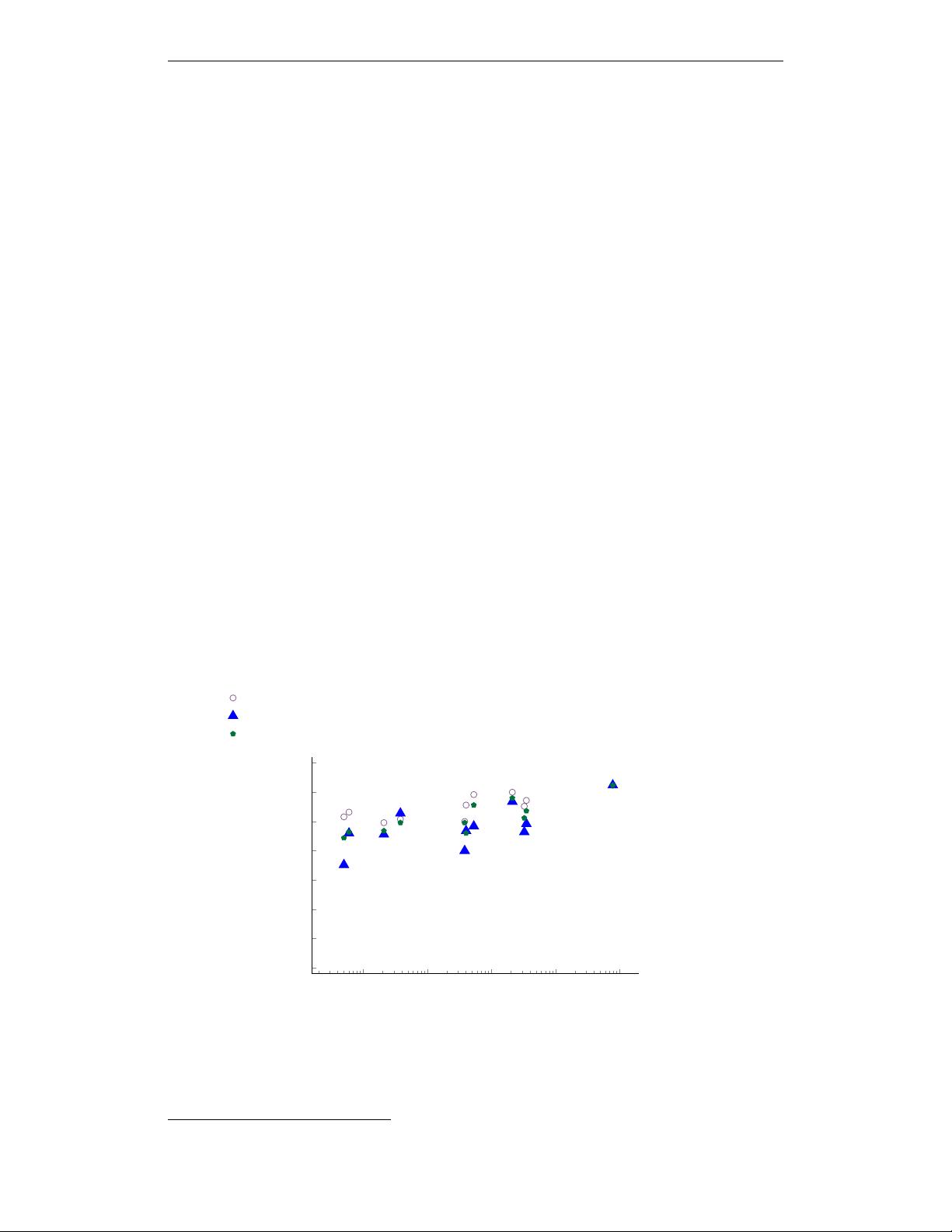
We evaluate two large language models, GPT-3 (Brown et al., 2020; Ouyang et al., 2022) and PaLM
(Chowdhery et al., 2022), on this benchmark. While both models solve less than 20% of problems
with standard prompting, the 540-billion-parameter PaLM model in particular shows exceptional
multilingual reasoning abilities with intermediate reasoning steps (Figure 1), solving more than 40%
of the problems in any investigated language, including underrepresented languages such as Bengali
and Swahili. In our best setting, PaLM achieves an average solve rate of 55% across languages. We
find that intermediate reasoning steps in English consistently lead to competitive or better results
than those written in the native language of the question, suggesting that English chain-of-thought
prompting may be a useful baseline for future multilingual reasoning work.
We further demonstrate that the multilingual reasoning abilities of pretrained models extend to
common-sense reasoning (Ponti et al., 2020) and word-in-context semantic judgment (Raganato
et al., 2020). By presenting the models with few-shot examples in different languages, PaLM sets a
new state-of-the-art performance (
89.9%
) on XCOPA (Ponti et al., 2020), outperforming the prior
approaches that require thousands of training examples.
2 THE MGSM BENCHMARK
In this section, we describe the collection process of Multilingual Grade School Math (MGSM), to
our knowledge the first multilingual arithmetic reasoning benchmark.
2 3 4 5 6 7 8
# Steps
0
10
20
30
40
50
60
70
80
# Problems
78
61
55
29
13 13
1
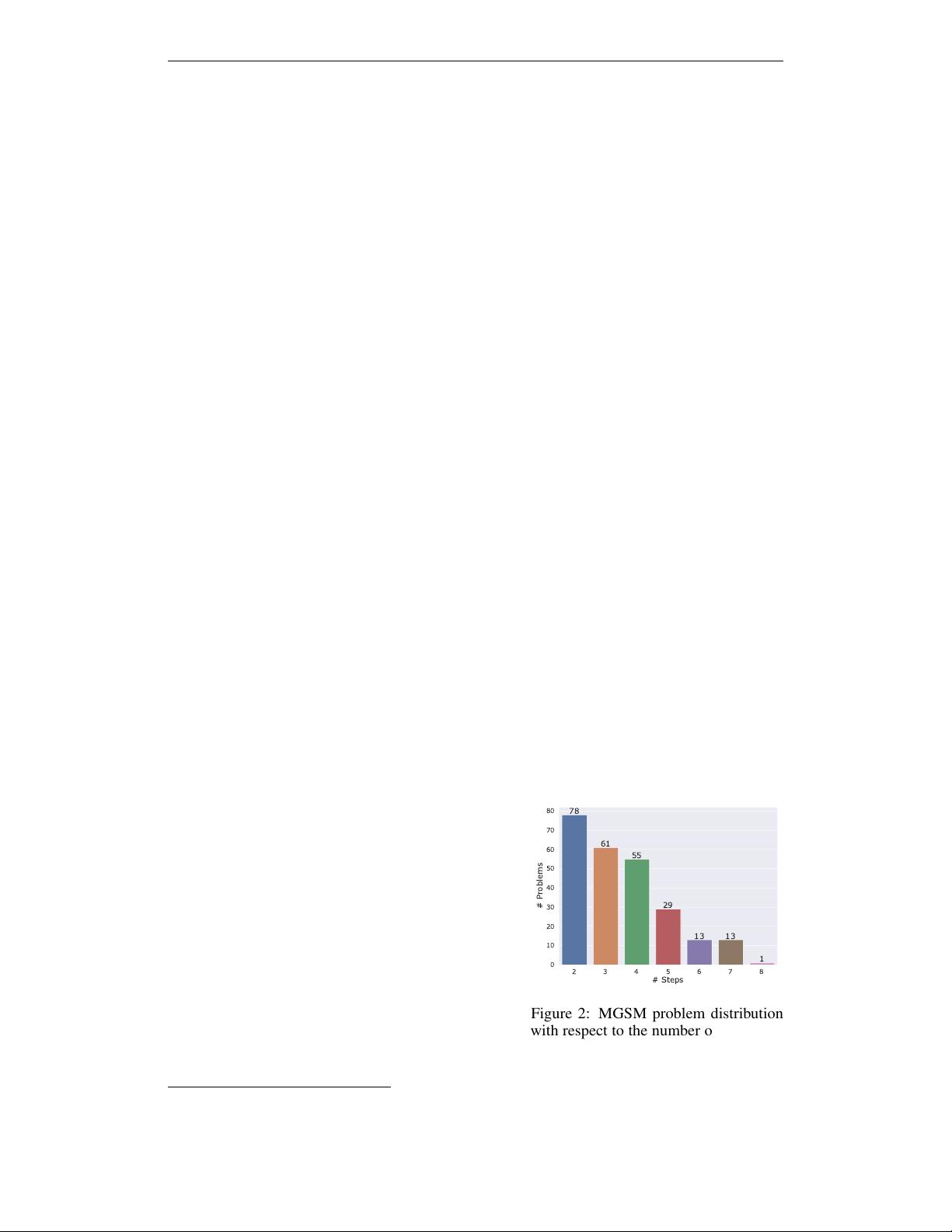
Figure 2: MGSM problem distribution
with respect to the number of reasoning
steps in the standard solution.
Source data.
We used GSM8K (Cobbe et al., 2021), an
English-language human-annotated grade-school math
problem dataset, as the base data source. For MGSM,
we took the first 250 examples from the GSM8K official
test example list. Each problem requires two to eight
steps to solve according to the official solution (Figure 2).
The answer for each question in GSM8K was written as
an Arabic numeral, which we kept consistent across all
languages to facilitate cross-lingual prediction.
1
Target language selection.
We selected a typologi-
cally diverse set of ten languages other than English (EN),
spanning eight language families and different levels of
representation in standard pretraining datasets such as
mC4 (Xue et al., 2021): Bengali (BN), Chinese (ZH),
French (FR), German (DE), Japanese (JA), Russian (RU),
Spanish (ES), Swahili (SW), Telugu (TE), and Thai (TH).
1
Certain scripts such as Devanagari employ different numerals. We restrict the data to Arabic numerals for
consistency but future work may investigate cross-lingual numeracy by mapping Arabic numerals to those of the
corresponding script (see Spithourakis & Riedel, 2018).
2