根据提供的文件信息,我们可以推断出这是一份关于Hadoop分布式文件系统(HDFS)的学习笔记。接下来将基于这些信息,详细阐述HDFS的核心概念、架构以及读写操作流程。
### Hadoop概述
Hadoop是一个开源软件框架,用于分布式存储和处理大型数据集。它由Apache基金会维护,主要包含两大组件:Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS是Hadoop的核心组件之一,负责提供高吞吐量的数据访问,并适合那些需要处理大量数据的应用程序。
### HDFS架构
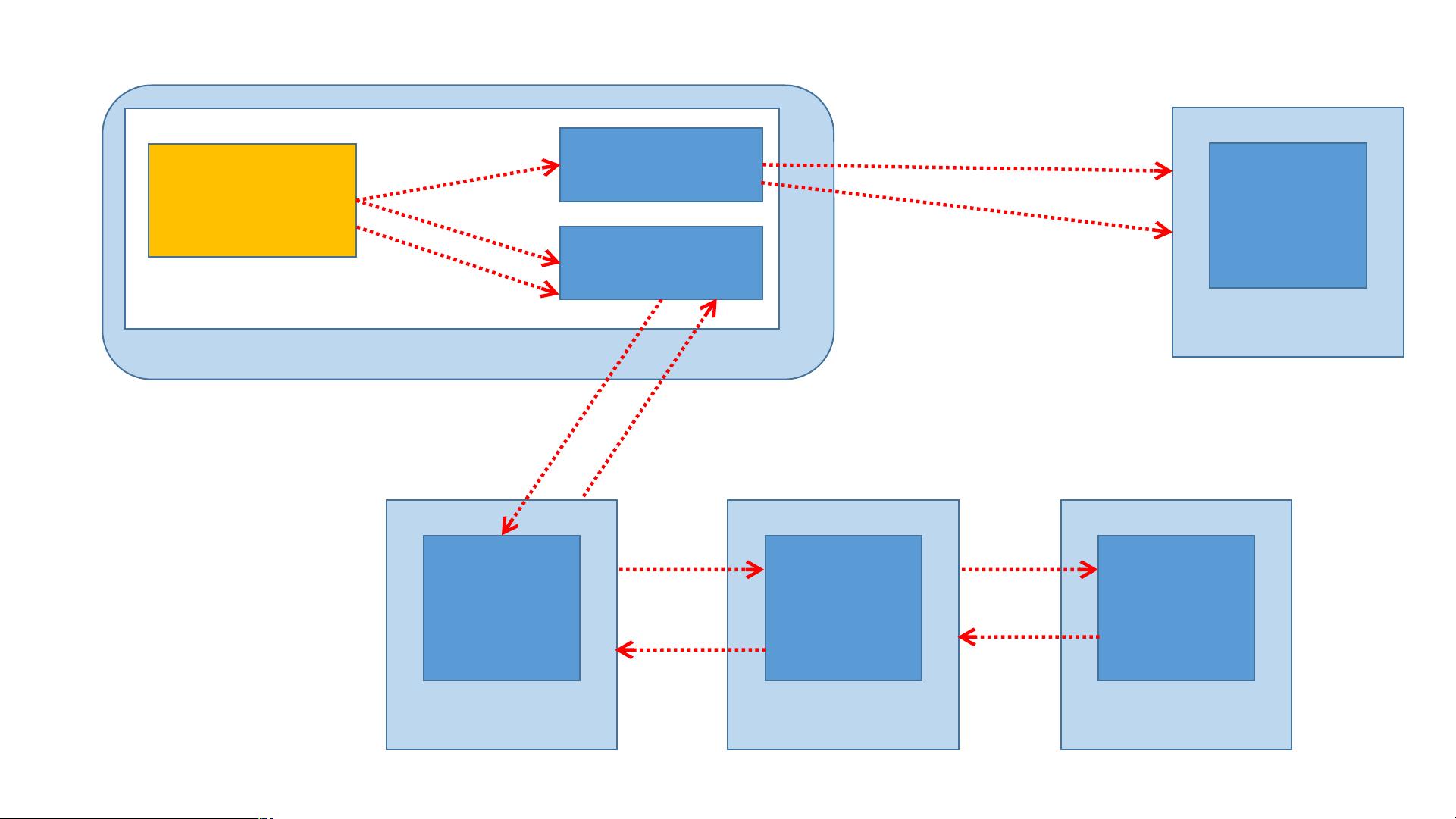
HDFS采用了主从式架构,主要由两种节点组成:**NameNode** 和 **DataNode**。
- **NameNode**:作为主节点,负责管理文件系统的命名空间(Namespace)和客户端对文件的访问。具体来说,它保存了文件系统的元数据,包括文件到数据块的映射、数据块的位置信息等。
- **DataNode**:作为从节点,负责管理分配给它们的存储块。DataNode会根据NameNode的指令进行数据块的创建、删除和复制等操作。
此外,还有**Client**的角色,它是用户与HDFS交互的接口。客户端通过发起文件读写请求来与HDFS进行交互。
### HDFS中的数据读取流程
在HDFS中读取数据时,客户端首先向NameNode发起读取请求,请求中包含了想要读取的文件路径。NameNode根据文件名查找其元数据信息,并返回文件所在的数据块以及这些数据块所在的DataNode地址列表给客户端。客户端随后直接与DataNode通信,从DataNode中获取数据块。为了提高读取效率,HDFS采用了流水线读取机制,即客户端可以从离它最近的一个DataNode读取数据,同时后续的数据块会通过DataNode之间的内部传输直接传递给客户端,从而减少了网络延迟。
### HDFS中的数据写入流程
当客户端需要向HDFS中写入数据时,同样首先联系NameNode。NameNode返回一个或多个DataNode地址列表给客户端,客户端将数据写入第一个DataNode。第一个DataNode收到数据后,会将其转发给第二个DataNode,以此类推,直到所有指定的副本都被写入完毕。写入过程中,如果任意DataNode发生故障,NameNode会自动重新调度写入操作,确保数据的可靠性。
### 客户端组件
在HDFS中,客户端与HDFS的交互通过一系列API完成,主要包括:
- **DistributedFileSystem**:客户端用来访问HDFS的主要类。它提供了文件系统的所有基本操作,如打开、关闭、重命名文件或目录等。
- **FSDataOutputStream**:用于向HDFS中写入数据的流对象。
- **FSDataInputStream**:用于从HDFS中读取数据的流对象。
### JVM的角色
由于Hadoop及其生态系统是用Java编写的,因此所有的组件都是运行在Java虚拟机(JVM)上的。客户端、NameNode和DataNode都运行在各自的JVM实例上。这意味着Hadoop可以在任何支持Java的平台上运行。
HDFS是一种高效、可靠的分布式文件系统,适用于大规模数据处理场景。通过对HDFS架构的理解,我们可以更好地掌握如何在Hadoop环境中进行数据的存储和访问。这对于从事大数据处理的开发人员和技术人员来说是非常重要的。







评论0
最新资源