DIMP算法.docx
需积分: 50 83 浏览量
2020-07-29
17:36:50
上传
评论 2
收藏 562KB DOCX 举报

【1 引言】
通用目标跟踪 是 在视频序列各帧中估计任意目标状态的任务。在最一般的设置中,
目标仅由在序列中它的初始状态来定义。当前大多数解决跟踪问题的方法是通过构建一个
能够区分目标和背景外观的目标模型,由于特定于目标的信息仅可在测试时获得,目标模
型无法在离线训练阶段被学习(目标模型),例如对象检测。取而代之的是,目标模型必须
在推理阶段本身通过利用测试时的目标信息来构建。
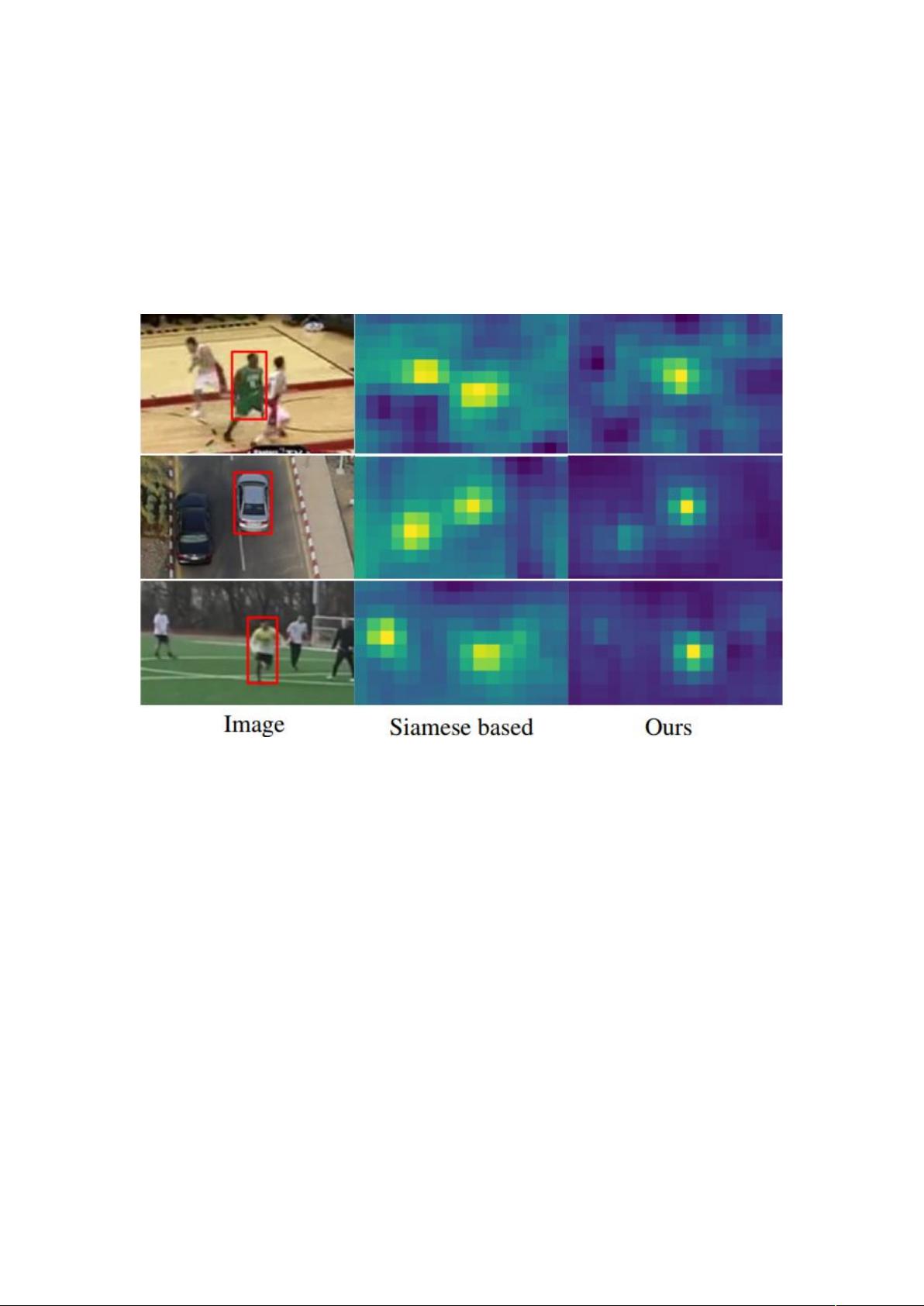
Figue1:目标对象(红色框)的置信度图是 通过使用 i)Siamese 方法(中间)以及 ii)我们的方法
(右)获得的目标模型 所提供的。以 Siamese 方式进行预测的模型仅使用目标外观,很难将目标与背景
中的干扰对象区分开。相比之下,我们的模型预测架构还集成了背景外观,从而提供了卓越的识别能力。
追求端到端的学习解决方案时,视觉跟踪问题的这种非常规特性 带来了重大挑战。
Siamese 学习模板[2,23]已最成功地解决了上述问题。这些方法首先学习一个嵌入
特征,其中通过简单的互相关来计算两个图像区域之间的相似度。然后通过找到与目标模
板最相似的图像区域来执行跟踪。在这种设置下,目标模型仅仅匹配于从目标区域提取的
模板特征。因此,可以使用多对带有标注的图像轻松地对跟踪器进行端到端训练。
尽管最近取得了成功,但 Siamese 学习框架仍受到严重限制。首先,Siamese 追踪
器在推断目标模型时仅仅利用目标外观。这完全忽略了背景外观信息,这对于将目标与场
景中的相似对象区分开来至关重要(请参见图 1)。其次,学习的相似性度量对于未包含
在离线训练集中的对象不一定是可靠的,从而导致泛化不佳。第三,Siamese 没有提供强
大的模型更新策略。相反,最先进的方法采取的却是简单的模板平均 [46]。与其他最新的
跟踪方法相比,这些限制导致鲁棒性较差[20].
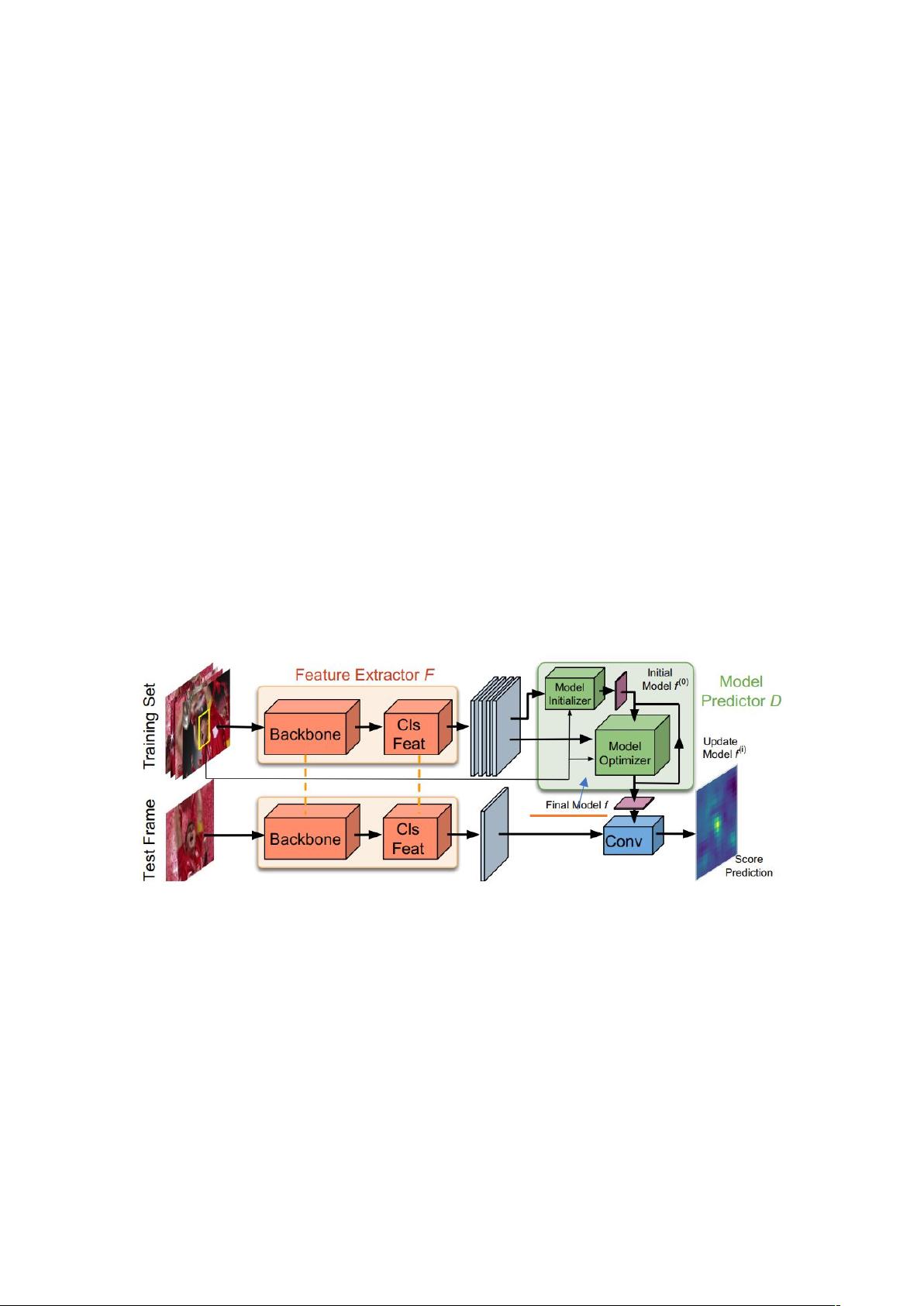
在这项工作中,我们引入了另一种以端到端的方式进行培训的替代跟踪体系结构,该
体系结构直接解决了所有上述限制。在我们的设计中,我们从具有识别能力的在线学习程
序中获得启发,这些程序已成功应用于最新的跟踪器中[6,9,30]。我们的方法基于目标
模型预测网络,它源自一个 识别能力的学习损失,通过应用迭代优化步骤来实现。该体系

剩余10页未读,继续阅读
资源评论













