

第 3 章 有穷状态自动机
1. 语言的识别
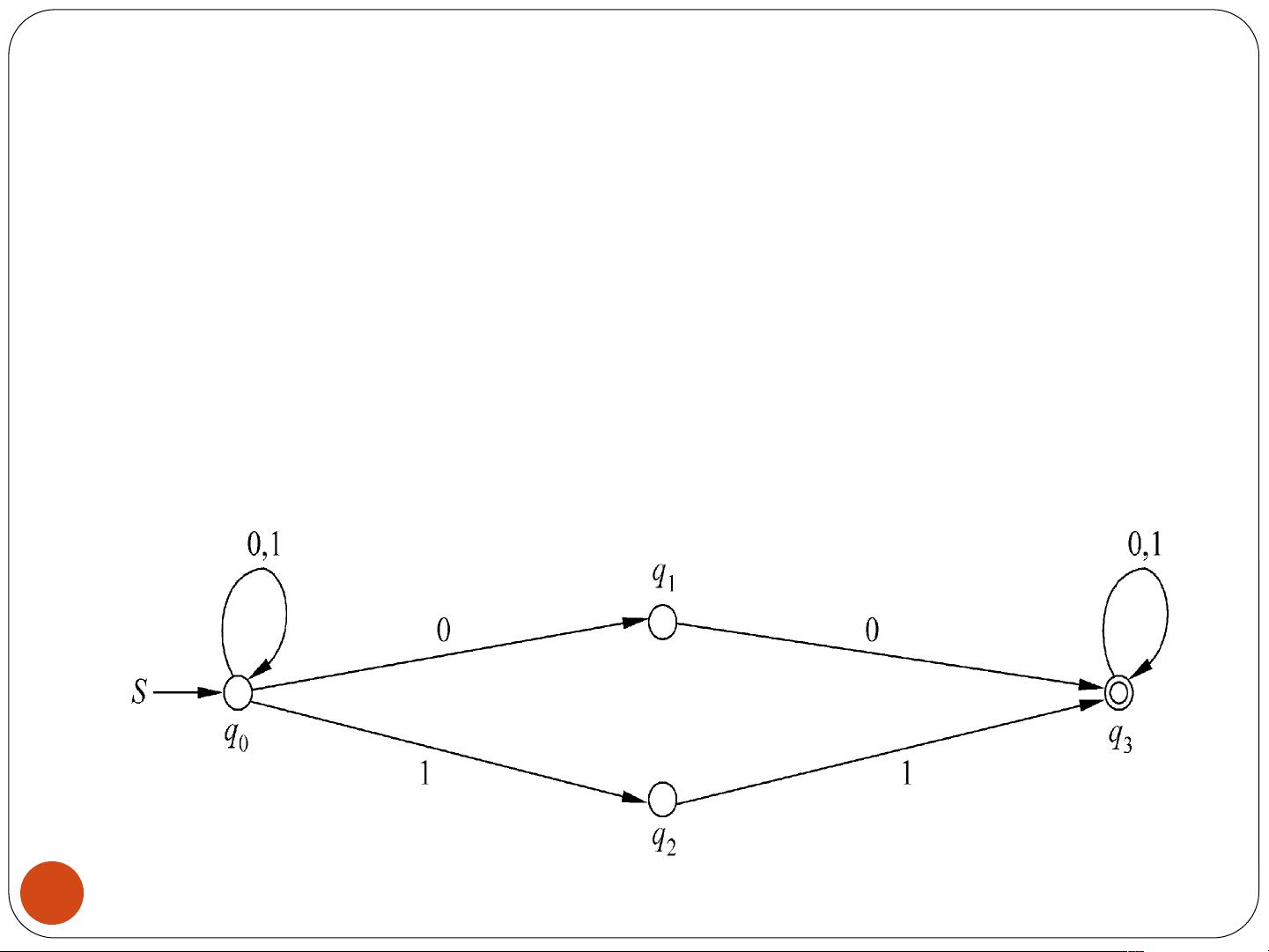
2. 有穷状态自动机
3. 不确定的有穷状态自动机
4. 带空转移的有穷状态自动机
5.FA 是正则语言的识别器
6.FA 的一些变形
7. 小结
1



剩余44页未读,继续阅读
资源评论


智慧安全方案
- 粉丝: 3851
- 资源: 59万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- Matlab机械臂七次B样条轨迹规划程序:带速度加速度约束的八个点优化解决方案,基于NSGA-II遗传算法的时间、能量、冲击最优策略,Matlab机械臂七次B样条轨迹规划程序:带速度加速度约束的八个点
- 基于MATLAB的交流电机动态分析程序:输入参数预测转速与力矩变化,基于MATLAB的交流电机动态方程分析与模拟程序:输入参数预测转速、力矩变化,基于matlab的交流电机动态方程,用于交流电机动态分
- 21个直播间礼物svga资源
- COMSOL模拟锌离子电池:锌离子沉积浓度场的源文件解析,深入探究COMSOL模拟锌离子电池中锌离子沉积浓度场源文件的技术与应用,comsol模拟锌离子电池锌离子沉积浓度场源文件 ,comsol模拟
- 多策略增强版三角拓扑聚合优化器-基于数学模型的连续优化与工程应用优化器的新发展,基于多策略改进的三角拓扑聚合优化器(ITTAO):一种数学启发式算法,解决连续优化问题与工程应用中的全局与局部最优平衡
- Simulink仿真模型光伏储能VSG与电容融合运行展示:波形完美展现光储一次调频、削峰填谷与直流母线电压控制功能,Simulink仿真模型下的光伏储能VSG运行及功能特点:光储一次调频、削峰填谷、直
- COMSOL电弧模拟与等离子体特性研究,COMSOL电弧模拟技术:探索等离子体行为与物理机制,comsol电弧模拟 等离子体 ,comsol电弧模拟; 等离子体模拟; 仿真建模; 物理现象模拟,COM
- 采用STC89C54RD设计的智能家居控制系统【含系统程序、系统PPT、设计报告、电路图等】
- MATLAB仿真的夫琅禾费衍射强度图:圆孔、圆环、矩形孔定制研究,MATLAB仿真:夫琅禾费衍射强度图的可定制性-以圆孔、圆环及矩形孔为例的研究分析,MATLAB夫琅禾费衍射强度图仿真 圆孔,圆环
- 基于CarSim与Matlab的ABS模糊控制策略联合仿真研究:优化制动效能与滑移率控制,汽车ABS模糊控制策略与逻辑门限值控制的联合仿真研究:提升制动效能与滑移率优化,基于CarSim和Matlab
- matlab实现FFT算法线性调频多目标仿真研究-LFM-FFT-目标识别-matlab
- COMSOL模拟锌离子电池锌负极电场模型教程:初学者友好版,附详细制作过程与多种模型源文件参考,COMSOL模拟锌离子电池锌负极电场模型源文件详解与教程:从初学者的角度出发,掌握电场模型制作全流程及多
- 30KW储能双向变流器PCS逆变器设计方案:高效能量转换与存储技术,优质高效 30KW储能PCS逆变器双向变流器设计方法与解析资料大全,30KW储能PCS逆变器双向变流器设计方案资料, ,核心关键词:
- 无感FOC技术解析:基于磁链观测器的零速带载闭环启动与力矩保持算法资料及MDK项目源码详解,无感FOC算法资料:磁链观测器、零速带载闭环启动、堵转力矩保持与直接正反转控制技术详解-含Cubemx配置
- AC DC DC模拟EV充电仿真系统:前后级交错PFC Boost与移相全桥隔离技术实现与matlab Simulink环境下模拟实践,AC DC转换与DC模拟EV充电仿真:PFC Boost与移相全
- matlab实现FXLMS主动噪声控制算法研究-自适应滤波器-噪声污染-噪音消除-matlab
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


