Hadoop 源码剖析
Hadoop 源码剖析
1 Hadoop 是什么
Hadoop 原来是 Apache Lucene 下的一个子项目,它最初是从 Nutch 项目中分离出来的专门负责分布式存储以
及分布式运算的项目。简单地说来,Hadoop 是一个可以更容易开发和运行处理大规模数据的软件平台。下面列举
hadoop 主要的一些特点:
1 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
2 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可
达数千个节点。
3 高效率(Ecient):通过分发数据,hadoop 可以在数据所在的节点上并行地(parallel)处理它们,
这使得处理非常的快速。
4 可靠性(Reliable):hadoop 能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署
(redeploy)计算任务。
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称 HDFS。HDFS 有着高容错性
(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high
throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS 放宽了
(relax)POSIX 的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
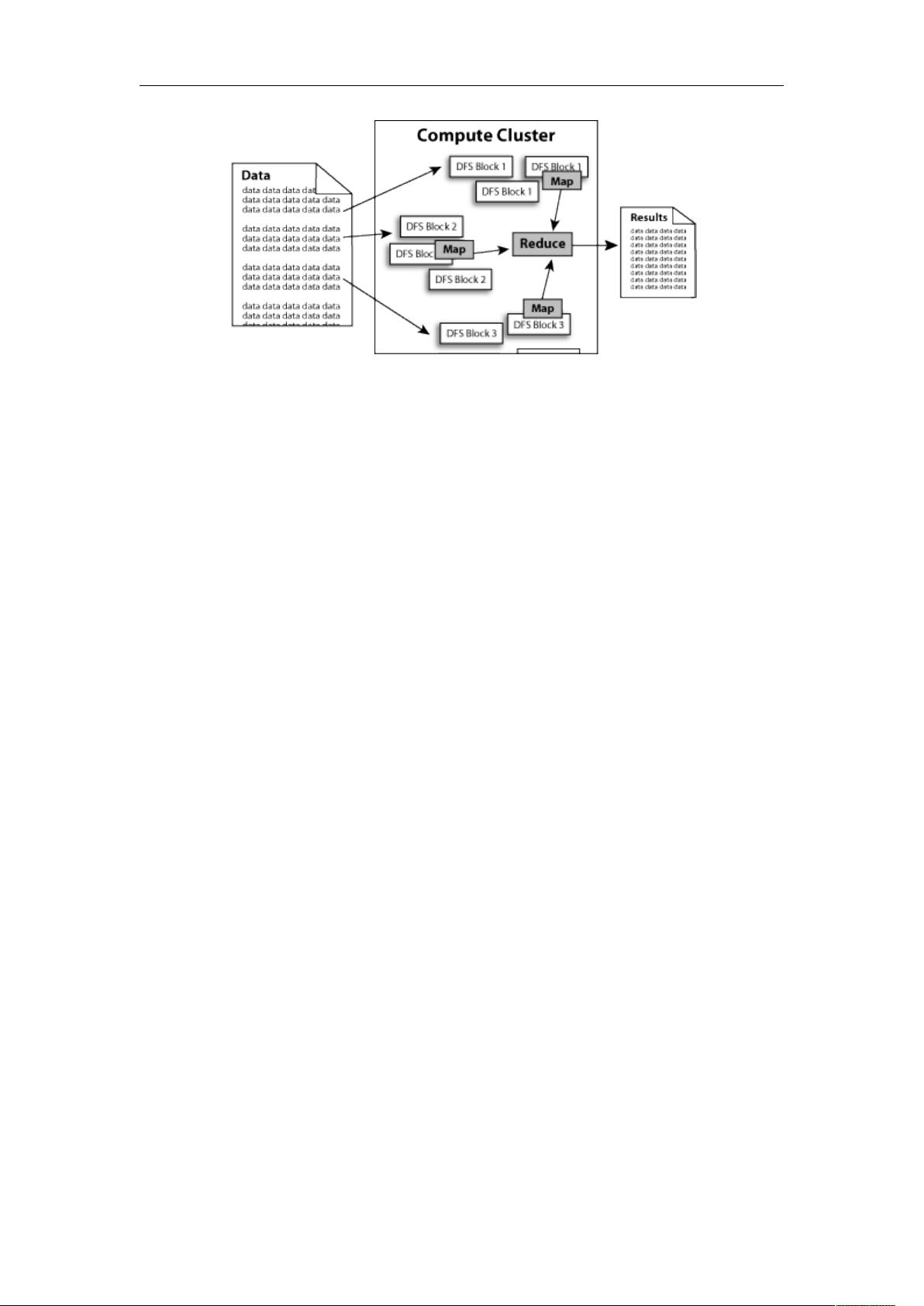
Hadoop 还实现了 MapReduce 分布式计算模型。MapReduce 将应用程序的工作分解成很多小的工作小块
(small blocks of work)。HDFS 为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制
(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce 就可以在它们所在的节点
上处理这些数据了。
如下图所示:
1