
.
教师评阅意见:
签名: 年 月 日
实验成绩:
一、 设计题目
基于 MATLAB 通信系统仿真——信源编解码。
二、实验内容及要求
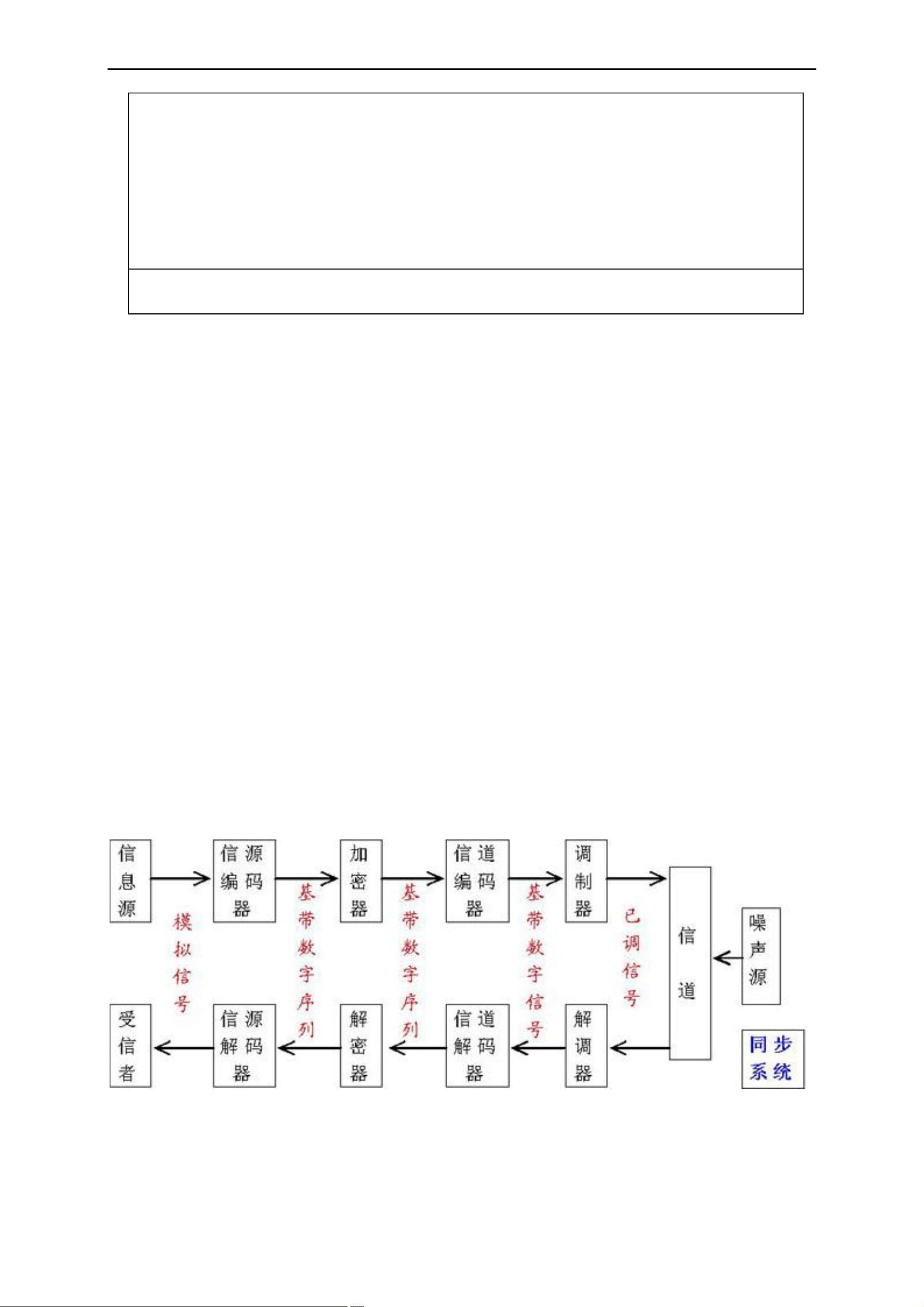
内容:完成对一模拟信号的抽样、量化、编码,然后利用 Huffman 信源编码对其进
行数据压缩,再利用(15,11)的线性分组码进行信道编码,然后采用DPSK 调制方
式调制,接着通过信道;在接收端进行其逆过程,即先解调(可采用相干解调或差
分相干解调),再依次为信道译码,Huffman 信源译码,PCM 译码。
要求:利用相关知识,建立系统模型,完成各个模块的代码设计。
三、实验过程(详细设计)
通信系统模型:

剩余14页未读,继续阅读
资源评论


xxpr_ybgg
- 粉丝: 6803
- 资源: 3万+









最新资源
- 精选毕设项目-蒙台梭利幼教.zip
- 精选毕设项目-母婴商城.zip
- 精选毕设项目-面包旅行.zip
- 精选毕设项目-柠檬树婚纱照.zip
- 精选毕设项目-企业OA系统小程序.zip
- 精选毕设项目-平安保险小程序.zip
- 凹凸社区APP源码蜜桃社区源码+视频搭建教程
- 精选毕设项目-汽车测评小程序.zip
- 精选毕设项目-企业版商城小程序.zip
- 精选毕设项目-汽车维修保养商店小程序.zip
- 精选毕设项目-仁怀酱酒宝:酒类商城模板.zip
- 精选毕设项目-扫码购物商城.zip
- 精选毕设项目-人民好公仆小程序(生活+便民+政务).zip
- 精选毕设项目-谁是杀手小程序游戏.zip
- 精选毕设项目-世博展会小程序.zip
- 精选毕设项目-守望先锋资讯小程序.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


