哈夫曼树的实现.docx
版权申诉
59 浏览量
2022-07-06
01:38:05
上传
评论
收藏 1.97MB DOCX 举报


《数据结构》课程设计
哈夫曼编码
一 目的
1.实现一个哈夫曼编码系统,让用户可以选择输入字符或者读取指定文件的字符;统
计出现的字符及其频率;根据统计结果建立哈夫曼树并且利用该树将各字符对应的编码表
保存在指定文件中;同时可以利用该哈夫曼表,将用户输入的字符或者指定文件的字符转
换成相应的编码文件。
2. 培养动手操作能力,将知识从书面理论层次提升到动手实践操作层次,通过尝试和
分析培养编程逻辑思维能力,并在其中找到属于自己的方法。
3. 通过课程设计,加深对《数据结构》课程所学知识的理解。
二 需求分析
1、输入数据需求分析
用户可以输入自己想要编码的字符串;并且程序可从相应的 EnglishPassage.txt 文档
中读取信息。
2、输出数据需求分析
用户可以在运行界面清晰明了的看到每种选择。并且程序可以将字符频率,编码后的
结果以及译码后的结果输出到屏幕上。
3、程序功能需求分析
(1)菜单选择功能:该程序包含主次两个菜单;向用户输出菜单选择页面,让用户能
够清晰的看到本程序所包含的各项功能,用户根据菜单提示选择输入执行相应的功能,当
用户输入不合法时提示用户。
(2)统计字符及其频率功能:用户可以输入自己想要编码的字符串或者选择从文件中
读取,该字符串必须含有字母,否则系统会提示输入有误。然后统计该字符串中每种字符
及其出现的频率。
(3)形成编码表功能:根据建立的哈夫曼树,程序会生成编码表。该编码表会被输出
到屏幕并且保存在 Code.txt 文件中。
(4)编码功能:形成编码表之后,程序会将字符串根据该编码表生成编码显示在屏幕
中并写入 ResultFile.txt 文件中。
(5)译码功能:程序可以将 ResultFile.txt 文件中的编码翻译成可读的字符串显示在屏
幕上并写入 translate.txt 文件中。
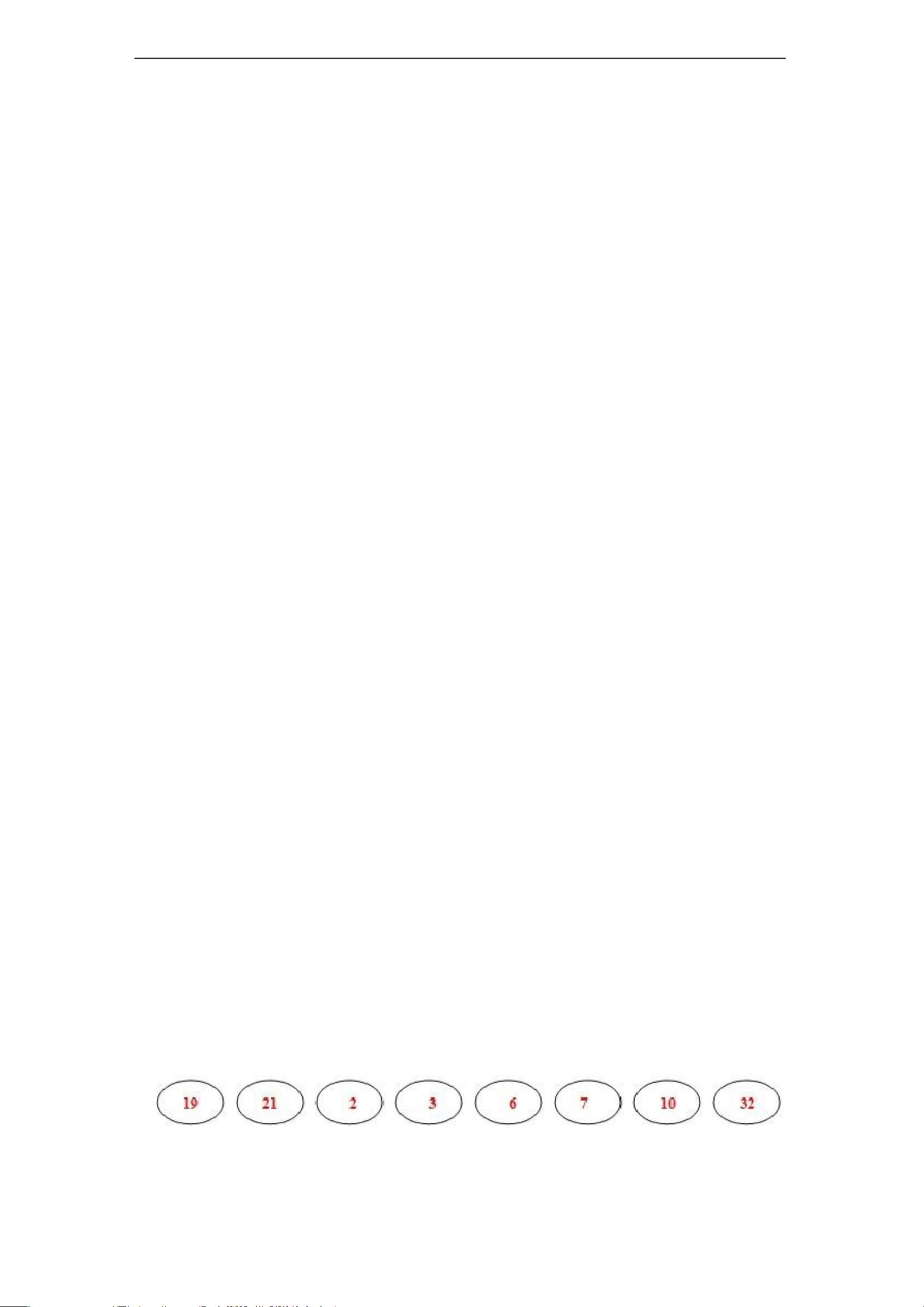
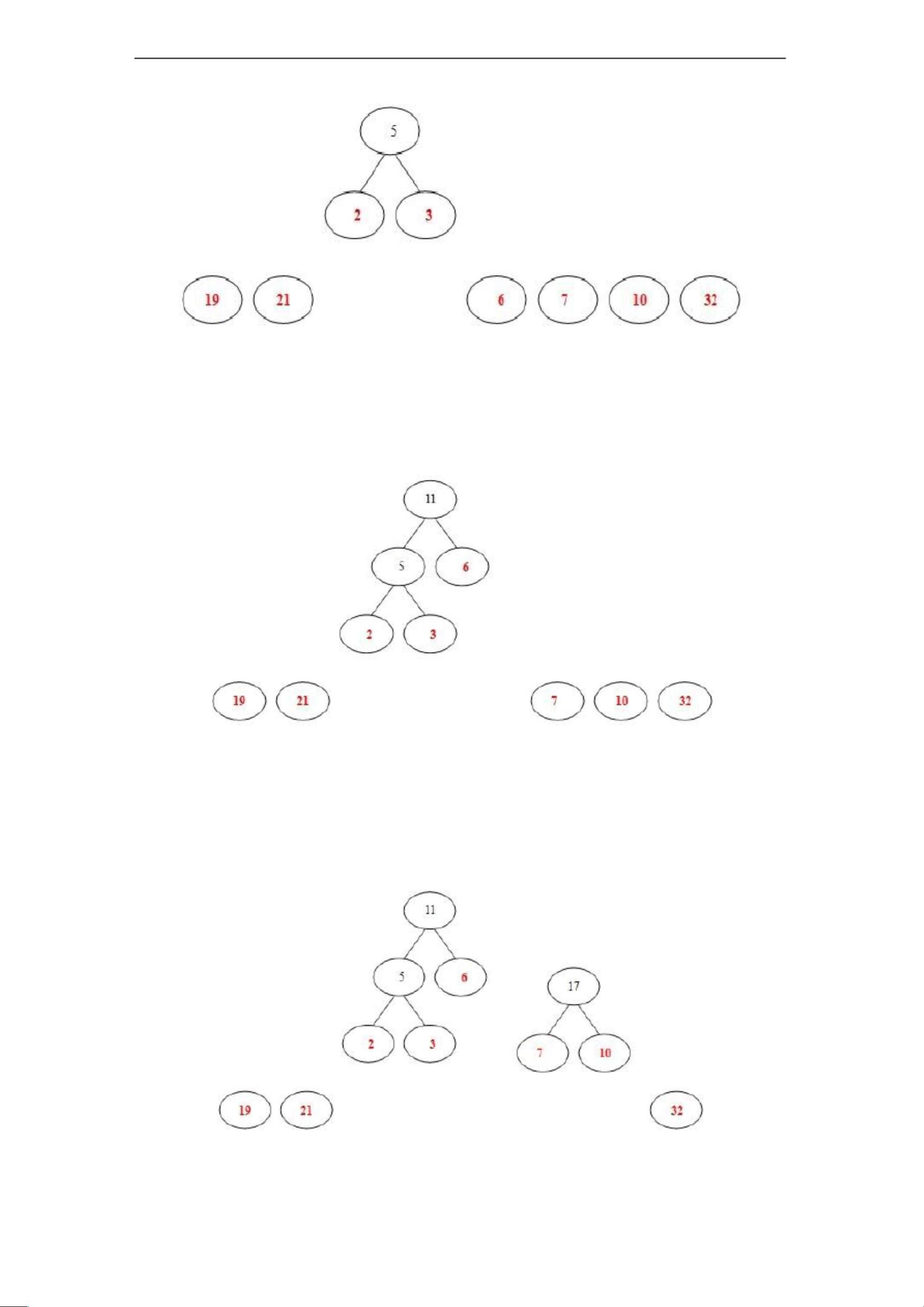
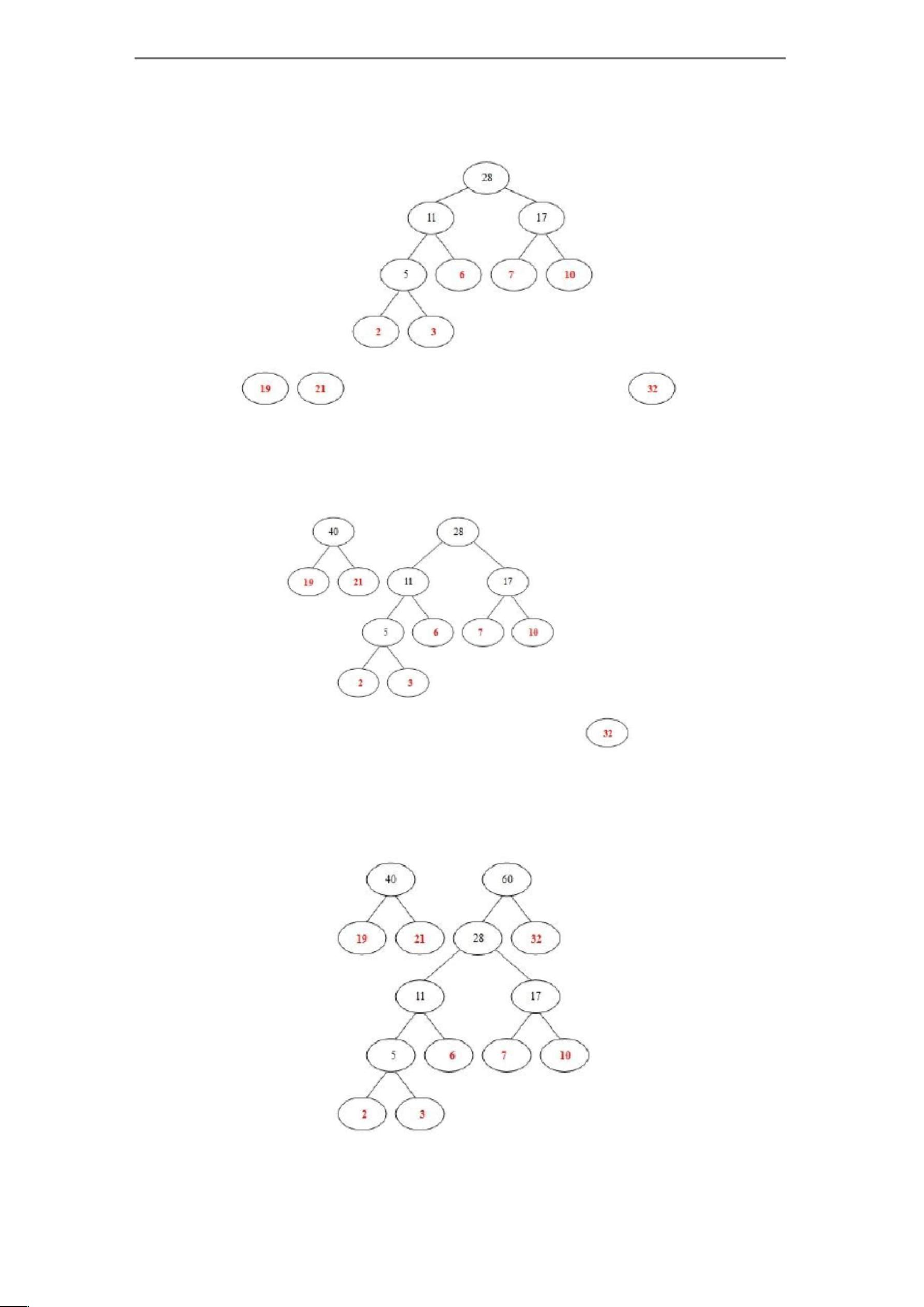
三 概要设计
1、流程图
整个哈夫曼编码系统的流程如图 1 所示。
1

剩余33页未读,继续阅读
资源评论













